'
suf = '
'
@@ -274,7 +275,7 @@ def close_up_code_segment_during_stream(gpt_reply):
def format_io(self, y):
"""
- 将输入和输出解析为HTML格式。将y中最后一项的输入部分段落化,并将输出部分的Markdown和数学公式转换为HTML格式。
+ 将输入和输出解析为HTML格式。将y中最后一项的输入部分段落化,并将输出部分的Markdown和数学公式转换为HTML格式。
"""
if y is None or y == []:
return []
@@ -290,7 +291,7 @@ def format_io(self, y):
def find_free_port():
"""
- 返回当前系统中可用的未使用端口。
+ 返回当前系统中可用的未使用端口。
"""
import socket
from contextlib import closing
@@ -410,9 +411,43 @@ def on_report_generated(files, chatbot):
return report_files, chatbot
def is_openai_api_key(key):
- # 正确的 API_KEY 是 "sk-" + 48 位大小写字母数字的组合
API_MATCH = re.match(r"sk-[a-zA-Z0-9]{48}$", key)
- return API_MATCH
+ return bool(API_MATCH)
+
+def is_api2d_key(key):
+ if key.startswith('fk') and len(key) == 41:
+ return True
+ else:
+ return False
+
+def is_any_api_key(key):
+ if ',' in key:
+ keys = key.split(',')
+ for k in keys:
+ if is_any_api_key(k): return True
+ return False
+ else:
+ return is_openai_api_key(key) or is_api2d_key(key)
+
+
+def select_api_key(keys, llm_model):
+ import random
+ avail_key_list = []
+ key_list = keys.split(',')
+
+ if llm_model.startswith('gpt-'):
+ for k in key_list:
+ if is_openai_api_key(k): avail_key_list.append(k)
+
+ if llm_model.startswith('api2d-'):
+ for k in key_list:
+ if is_api2d_key(k): avail_key_list.append(k)
+
+ if len(avail_key_list) == 0:
+ raise RuntimeError(f"您提供的api-key不满足要求,不包含任何可用于{llm_model}的api-key。")
+
+ api_key = random.choice(avail_key_list) # 随机负载均衡
+ return api_key
@lru_cache(maxsize=128)
def read_single_conf_with_lru_cache(arg):
@@ -423,7 +458,7 @@ def read_single_conf_with_lru_cache(arg):
r = getattr(importlib.import_module('config'), arg)
# 在读取API_KEY时,检查一下是不是忘了改config
if arg == 'API_KEY':
- if is_openai_api_key(r):
+ if is_any_api_key(r):
print亮绿(f"[API_KEY] 您的 API_KEY 是: {r[:15]}*** API_KEY 导入成功")
else:
print亮红( "[API_KEY] 正确的 API_KEY 是 'sk-' + '48 位大小写字母数字' 的组合,请在config文件中修改API密钥, 添加海外代理之后再运行。" + \
From 5549e5880aa80b5db65f63e88efd02d6257c06f6 Mon Sep 17 00:00:00 2001
From: Your Name  -- 多种大语言模型混合调用([v3.1分支](https://github.com/binary-husky/chatgpt_academic/tree/v3.1)测试中)
+- 多种大语言模型混合调用(ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4, [v3.1分支](https://github.com/binary-husky/chatgpt_academic/tree/v3.1)测试中)
-- 多种大语言模型混合调用([v3.1分支](https://github.com/binary-husky/chatgpt_academic/tree/v3.1)测试中)
+- 多种大语言模型混合调用(ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4, [v3.1分支](https://github.com/binary-husky/chatgpt_academic/tree/v3.1)测试中)
- +
+
+v3.1的[huggingface测试版](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta)(huggingface版不支持chatglm)
+
## 直接运行 (Windows, Linux or MacOS)
diff --git a/docs/logo.png b/docs/logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..567dee1a957833b9a925cf709c6ebedce482bd43
GIT binary patch
literal 11335
zcmX|nbwE_#6E7{X(k;2f5(0}Lxspq#NUL;7DBUcu
+

- -
- -
-
-
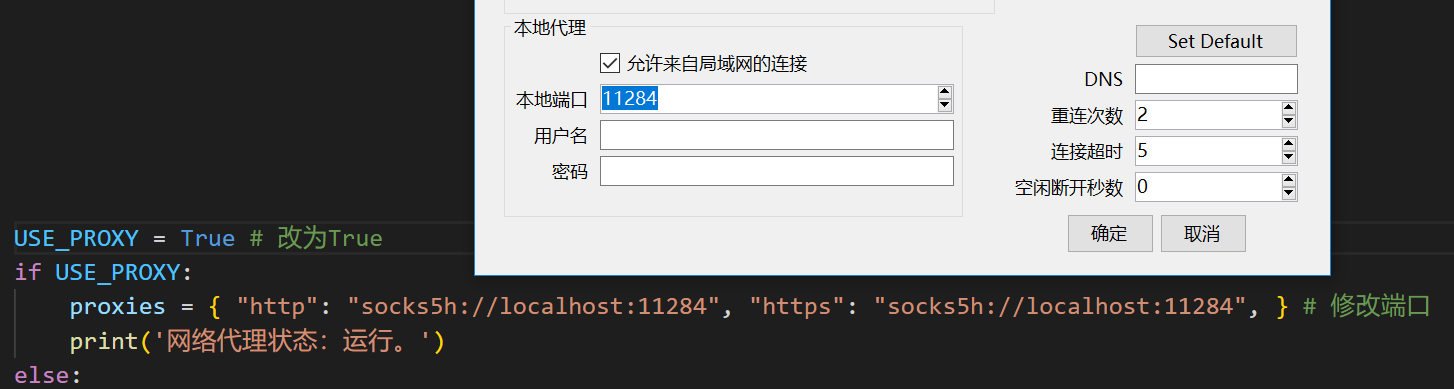
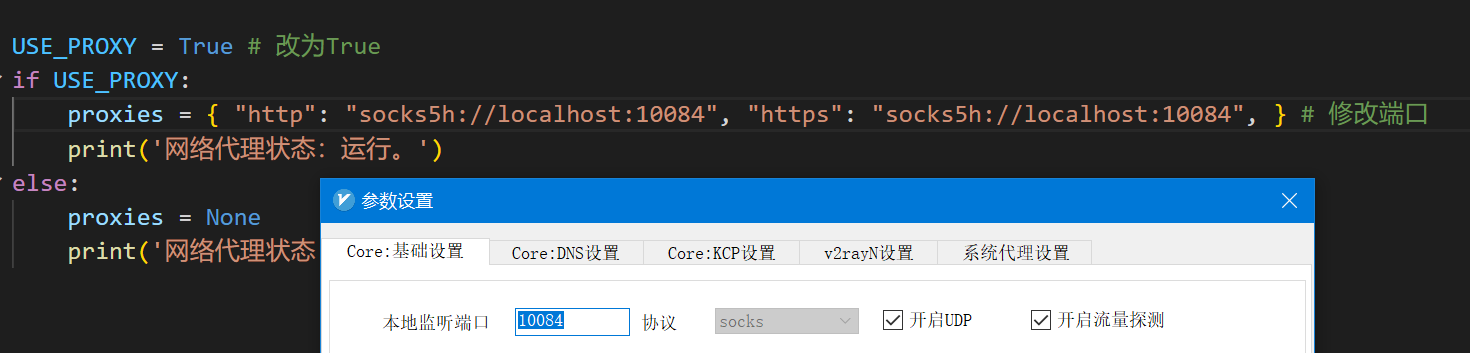
-配置完成后,你可以用以下命令测试代理是否工作,如果一切正常,下面的代码将输出你的代理服务器所在地:
-```
-python check_proxy.py
-```
-### 方法二:纯新手教程
-[纯新手教程](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
-
-## 功能测试
+## 部分功能展示
### 图片显示:
@@ -258,8 +265,9 @@ python check_proxy.py
## Todo 与 版本规划:
-
-- version 3.0 (Todo): 优化对chatglm和其他小型llm的支持
+- version 3.2+ (todo): 函数插件支持更多参数接口
+- version 3.1: 支持同时问询多个gpt模型!支持api2d,支持多个apikey负载均衡
+- version 3.0: 对chatglm和其他小型llm的支持
- version 2.6: 重构了插件结构,提高了交互性,加入更多插件
- version 2.5: 自更新,解决总结大工程源代码时文本过长、token溢出的问题
- version 2.4: (1)新增PDF全文翻译功能; (2)新增输入区切换位置的功能; (3)新增垂直布局选项; (4)多线程函数插件优化。
@@ -271,14 +279,12 @@ python check_proxy.py
## 参考与学习
-
```
代码中参考了很多其他优秀项目中的设计,主要包括:
-# 借鉴项目1:借鉴了ChuanhuChatGPT中读取OpenAI json的方法、记录历史问询记录的方法以及gradio queue的使用技巧
+# 借鉴项目1:借鉴了ChuanhuChatGPT中诸多技巧
https://github.com/GaiZhenbiao/ChuanhuChatGPT
-# 借鉴项目2:
+# 借鉴项目2:清华ChatGLM-6B:
https://github.com/THUDM/ChatGLM-6B
-
```
diff --git a/docs/Dockerfile+ChatGLM b/docs/Dockerfile+ChatGLM
index 4a11f06..8e60524 100644
--- a/docs/Dockerfile+ChatGLM
+++ b/docs/Dockerfile+ChatGLM
@@ -11,11 +11,11 @@ RUN apt-get install -y git python python3 python-dev python3-dev --fix-missing
# 配置代理网络(构建Docker镜像时使用)
# # comment out below if you do not need proxy network | 如果不需要翻墙 - 从此行向下删除
-RUN $useProxyNetwork curl cip.cc
-RUN sed -i '$ d' /etc/proxychains.conf
-RUN sed -i '$ d' /etc/proxychains.conf
-RUN echo "socks5 127.0.0.1 10880" >> /etc/proxychains.conf
-ARG useProxyNetwork=proxychains
+# RUN $useProxyNetwork curl cip.cc
+# RUN sed -i '$ d' /etc/proxychains.conf
+# RUN sed -i '$ d' /etc/proxychains.conf
+# RUN echo "socks5 127.0.0.1 10880" >> /etc/proxychains.conf
+# ARG useProxyNetwork=proxychains
# # comment out above if you do not need proxy network | 如果不需要翻墙 - 从此行向上删除
@@ -42,11 +42,14 @@ ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN $useProxyNetwork git pull
# 为chatgpt-academic配置代理和API-KEY (非必要 可选步骤)
+# 可同时填写多个API-KEY,支持openai的key和api2d的key共存,用英文逗号分割,例如API_KEY = "sk-openaikey1,sk-openaikey2,fkxxxx-api2dkey1,fkxxxx-api2dkey2"
+# LLM_MODEL 是选择初始的模型
+# LOCAL_MODEL_DEVICE 是选择chatglm等本地模型运行的设备,可选 cpu 和 cuda
RUN echo ' \n\
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \n\
USE_PROXY = True \n\
LLM_MODEL = "chatglm" \n\
-LOCAL_MODEL_DEVICE = "cuda" \n\
+LOCAL_MODEL_DEVICE = "cpu" \n\
proxies = { "http": "socks5h://localhost:10880", "https": "socks5h://localhost:10880", } ' >> config_private.py
# 启动
From 28aa6d1dc0826608d9349bdd5b1d35dd5cbfd1de Mon Sep 17 00:00:00 2001
From: Your Name
-
-
-- 多种大语言模型混合调用(ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4, [v3.1分支](https://github.com/binary-husky/chatgpt_academic/tree/v3.1)测试中)
+- 多种大语言模型混合调用(ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
Function | Description
--- | ---
-One-click refinement | Supports one-click refinement, one-click searching for grammatical errors in papers.
-One-click translation between Chinese and English | One-click translation between Chinese and English.
-One-click code interpretation | Can correctly display and interpret the code.
-[Custom shortcuts](https://www.bilibili.com/video/BV14s4y1E7jN) | Supports custom shortcuts.
-[Configure proxy server](https://www.bilibili.com/video/BV1rc411W7Dr) | Supports configuring proxy server.
-Modular design | Supports custom high-order experimental features and [function plug-ins], and plug-ins support [hot update](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
-[Self-program analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plug-in] [One-Key Understanding](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) the source code of this project.
-[Program analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plug-in] One-click can analyze other Python/C/C++/Java/Golang/Lua/Rect project trees.
-Read papers | [Function Plug-in] One-click reads the full text of a latex paper and generates an abstract.
-Latex full-text translation/refinement | [Function Plug-in] One-click translates or refines a latex paper.
-Batch annotation generation | [Function Plug-in] One-click generates function annotations in batches.
-Chat analysis report generation | [Function Plug-in] Automatically generate summary reports after running.
-[Arxiv assistant](https://www.bilibili.com/video/BV1LM4y1279X) | [Function Plug-in] Enter the arxiv paper url and you can translate the abstract and download the PDF with one click.
-[PDF paper full-text translation function](https://www.bilibili.com/video/BV1KT411x7Wn) | [Function Plug-in] Extract title and abstract of PDF papers + translate full text (multi-threaded).
-[Google Scholar integration assistant](https://www.bilibili.com/video/BV19L411U7ia) (Version>=2.45) | [Function Plug-in] Given any Google Scholar search page URL, let GPT help you choose interesting articles.
-Formula display | Can simultaneously display the tex form and rendering form of formulas.
-Image display | Can display images in Markdown.
-Multithreaded function plug-in support | Supports multi-threaded calling of chatgpt, one-click processing of massive texts or programs.
-Support for markdown tables output by GPT | Can output markdown tables that support GPT.
-Start dark gradio theme [theme](https://github.com/binary-husky/chatgpt_academic/issues/173) | Add ```/?__dark-theme=true``` to the browser URL to switch to the dark theme.
-Huggingface free scientific online experience](https://huggingface.co/spaces/qingxu98/gpt-academic) | After logging in to Huggingface, copy [this space](https://huggingface.co/spaces/qingxu98/gpt-academic).
-[Mixed support for multiple LLM models](https://www.bilibili.com/video/BV1EM411K7VH/) ([v3.0 branch](https://github.com/binary-husky/chatgpt_academic/tree/v3.0) in testing) | It must feel great to be served by both ChatGPT and [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B)!
-Compatible with [TGUI](https://github.com/oobabooga/text-generation-webui) to access more language models | Access to opt-1.3b, galactica-1.3b and other models ([v3.0 branch](https://github.com/binary-husky/chatgpt_academic/tree/v3.0) under testing).
-… | ...
+One-Click Polish | Supports one-click polishing and finding grammar errors in academic papers.
+One-Key Translation Between Chinese and English | One-click translation between Chinese and English.
+One-Key Code Interpretation | Can correctly display and interpret code.
+[Custom Shortcut Keys](https://www.bilibili.com/video/BV14s4y1E7jN) | Supports custom shortcut keys.
+[Configure Proxy Server](https://www.bilibili.com/video/BV1rc411W7Dr) | Supports configuring proxy servers.
+Modular Design | Supports custom high-order function plugins and [function plugins], and plugins support [hot updates](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
+[Self-programming Analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plugin] [One-Key Read] (https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) The source code of this project is analyzed.
+[Program Analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plugin] One-click can analyze the project tree of other Python/C/C++/Java/Lua/... projects
+Read the Paper | [Function Plugin] One-click interpretation of the full text of latex paper and generation of abstracts
+Latex Full Text Translation, Proofreading | [Function Plugin] One-click translation or proofreading of latex papers.
+Batch Comment Generation | [Function Plugin] One-click batch generation of function comments
+Chat Analysis Report Generation | [Function Plugin] After running, an automatic summary report will be generated
+[Arxiv Assistant](https://www.bilibili.com/video/BV1LM4y1279X) | [Function Plugin] Enter the arxiv article url to translate the abstract and download the PDF with one click
+[Full-text Translation Function of PDF Paper](https://www.bilibili.com/video/BV1KT411x7Wn) | [Function Plugin] Extract the title & abstract of the PDF paper + translate the full text (multithreading)
+[Google Scholar Integration Assistant](https://www.bilibili.com/video/BV19L411U7ia) | [Function Plugin] Given any Google Scholar search page URL, let gpt help you choose interesting articles.
+Formula / Picture / Table Display | Can display both the tex form and the rendering form of formulas at the same time, support formula and code highlighting
+Multithreaded Function Plugin Support | Supports multi-threaded calling chatgpt, one-click processing of massive text or programs
+Start Dark Gradio [Theme](https://github.com/binary-husky/chatgpt_academic/issues/173) | Add ```/?__dark-theme=true``` at the end of the browser url to switch to dark theme
+[Multiple LLM Models](https://www.bilibili.com/video/BV1wT411p7yf) support, [API2D](https://api2d.com/) interface support | It must feel nice to be served by both GPT3.5, GPT4, and [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B)!
+Huggingface non-Science Net [Online Experience](https://huggingface.co/spaces/qingxu98/gpt-academic) | After logging in to huggingface, copy [this space](https://huggingface.co/spaces/qingxu98/gpt-academic)
+... | ...
-
-- New interface (modify the `LAYOUT` option in `config.py` to switch between "left and right layout" and "up and down layout").
+
+- New interface (switch between "left-right layout" and "up-down layout" by modifying the LAYOUT option in config.py)




-
-
-
-- Don't want to read project code? Let chatgpt boast about the whole project.
+- Don't want to read the project code? Just take the whole project to chatgpt
-
+
+
+
+Multiple major language model mixing call [huggingface beta version](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta) (the huggingface version does not support chatglm)
-## Running Directly (Windows, Linux or MacOS)
+---
-### 1. Download the Project
+## Installation-Method 1: Run directly (Windows, Linux or MacOS)
+
+1. Download project
```sh
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-### 2. Configure API_KEY and Proxy Settings
+2. Configure API_KEY and proxy settings
-In `config.py`, configure the overseas Proxy and OpenAI API KEY, as follows:
-```
-1. If you are in China, you need to set an overseas proxy to use the OpenAI API smoothly. Please read the instructions in config.py carefully (1. Modify the USE_PROXY to True; 2. Modify the proxies according to the instructions).
-2. Configure OpenAI API KEY. You need to register on the OpenAI official website and obtain an API KEY. Once you get the API KEY, configure it in the config.py file.
-3. Issues related to proxy network (network timeout, proxy not working) are summarized to https://github.com/binary-husky/chatgpt_academic/issues/1
-```
-(Note: When the program is running, it will first check whether there is a private configuration file named `config_private.py`, and use the configuration in it to overwrite the same name configuration in `config.py`. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file next to `config.py` named `config_private.py` and transfer (copy) the configuration in `config.py` to `config_private.py`. `config_private.py` is not managed by Git, which can make your privacy information more secure.)
-### 3. Install Dependencies
+In `config.py`, configure the overseas Proxy and OpenAI API KEY as follows:
+```
+1. If you are in China, you need to set up an overseas proxy to use the OpenAI API smoothly. Please read config.py carefully for setup details (1. Modify USE_PROXY to True; 2. Modify proxies according to the instructions).
+2. Configure the OpenAI API KEY. You need to register and obtain an API KEY on the OpenAI website. Once you get the API KEY, you can configure it in the config.py file.
+3. Issues related to proxy networks (network timeouts, proxy failures) are summarized at https://github.com/binary-husky/chatgpt_academic/issues/1
+```
+(P.S. When the program runs, it will first check whether there is a private configuration file named `config_private.py` and use the same-name configuration in `config.py` to overwrite it. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file named `config_private.py` next to `config.py` and transfer (copy) the configuration in `config.py` to` config_private.py`. `config_private.py` is not controlled by git and can make your privacy information more secure.))
+
+
+3. Install dependencies
```sh
-# (Option 1) Recommended
+# (Option One) Recommended
python -m pip install -r requirements.txt
-# (Option 2) If you use anaconda, the steps are also similar:
-# (Option 2.1) conda create -n gptac_venv python=3.11
-# (Option 2.2) conda activate gptac_venv
-# (Option 2.3) python -m pip install -r requirements.txt
+# (Option Two) If you use anaconda, the steps are similar:
+# (Option Two.1) conda create -n gptac_venv python=3.11
+# (Option Two.2) conda activate gptac_venv
+# (Option Two.3) python -m pip install -r requirements.txt
-# Note: Use the official pip source or the Ali pip source. Other pip sources (such as some university pips) may have problems. Temporary substitution method:
+# Note: Use official pip source or Ali pip source. Other pip sources (such as some university pips) may have problems, and temporary replacement methods are as follows:
# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
```
-### 4. Run
+If you need to support Tsinghua ChatGLM, you need to install more dependencies (if you are not familiar with python or your computer configuration is not good, we recommend not to try):
+```sh
+python -m pip install -r request_llm/requirements_chatglm.txt
+```
+
+4. Run
```sh
python main.py
```
-### 5. Test Experimental Features
+5. Test function plugins
```
-- Test C++ Project Header Analysis
- In the input area, enter `./crazy_functions/test_project/cpp/libJPG` , and then click "[Experiment] Parse the entire C++ project (input inputs the root path of the project)"
-- Test Writing Abstracts for Latex Projects
- In the input area, enter `./crazy_functions/test_project/latex/attention` , and then click "[Experiment] Read the tex paper and write an abstract (input inputs the root path of the project)"
-- Test Python Project Analysis
- In the input area, enter `./crazy_functions/test_project/python/dqn` , and then click "[Experiment] Parse the entire py project (input inputs the root path of the project)"
-- Test Self-code Interpretation
- Click "[Experiment] Please analyze and deconstruct this project itself"
-- Test Experimental Function Template (asking GPT what happened in history today), you can implement more complex functions based on this template function
- Click "[Experiment] Experimental function template"
+- Test Python project analysis
+ In the input area, enter `./crazy_functions/test_project/python/dqn`, and then click "Analyze the entire Python project"
+- Test self-code interpretation
+ Click "[Multithreading Demo] Interpretation of This Project Itself (Source Code Interpretation)"
+- Test experimental function template function (requires gpt to answer what happened today in history). You can use this function as a template to implement more complex functions.
+ Click "[Function Plugin Template Demo] Today in History"
+- There are more functions to choose from in the function plugin area drop-down menu.
```
-## Use Docker (Linux)
+## Installation-Method 2: Use Docker (Linux)
+1. ChatGPT only (recommended for most people)
``` sh
-# Download Project
+# download project
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
-# Configure Overseas Proxy and OpenAI API KEY
-Configure config.py with any text editor
-# Installation
+# configure overseas Proxy and OpenAI API KEY
+Edit config.py with any text editor
+# Install
docker build -t gpt-academic .
# Run
docker run --rm -it --net=host gpt-academic
-# Test Experimental Features
-## Test Self-code Interpretation
-Click "[Experiment] Please analyze and deconstruct this project itself"
-## Test Experimental Function Template (asking GPT what happened in history today), you can implement more complex functions based on this template function
-Click "[Experiment] Experimental function template"
-## (Please note that when running in docker, you need to pay extra attention to file access rights issues of the program.)
-## Test C++ Project Header Analysis
-In the input area, enter ./crazy_functions/test_project/cpp/libJPG , and then click "[Experiment] Parse the entire C++ project (input inputs the root path of the project)"
-## Test Writing Abstracts for Latex Projects
-In the input area, enter ./crazy_functions/test_project/latex/attention , and then click "[Experiment] Read the tex paper and write an abstract (input inputs the root path of the project)"
+# Test function plug-in
+## Test function plugin template function (requires gpt to answer what happened today in history). You can use this function as a template to implement more complex functions.
+Click "[Function Plugin Template Demo] Today in History"
+## Test Abstract Writing for Latex Projects
+Enter ./crazy_functions/test_project/latex/attention in the input area, and then click "Read Tex Paper and Write Abstract"
## Test Python Project Analysis
-In the input area, enter ./crazy_functions/test_project/python/dqn , and then click "[Experiment] Parse the entire py project (input inputs the root path of the project)"
+Enter ./crazy_functions/test_project/python/dqn in the input area and click "Analyze the entire Python project."
+More functions are available in the function plugin area drop-down menu.
```
-## Other Deployment Methods
-- Use WSL2 (Windows Subsystem for Linux subsystem)
-Please visit [Deploy Wiki-1] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+2. ChatGPT+ChatGLM (requires strong familiarity with docker + strong computer configuration)
-- nginx remote deployment
-Please visit [Deploy Wiki-2] (https://github.com/binary-husky/chatgpt_academic/wiki/%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E7%9A%84%E6%8C%87%E5%AF%BC)
-
-
-## Customizing New Convenient Buttons (Academic Shortcut Key Customization)
-Open functional.py and add the entry as follows, and then restart the program. (If the button has been successfully added and is visible, both the prefix and suffix support hot modification and take effect without restarting the program.)
-
-For example,
+``` sh
+# Modify dockerfile
+cd docs && nano Dockerfile+ChatGLM
+# How to build | 如何构建 (Dockerfile+ChatGLM在docs路径下,请先cd docs)
+docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
+# How to run | 如何运行 (1) 直接运行:
+docker run --rm -it --net=host --gpus=all gpt-academic
+# How to run | 如何运行 (2) 我想运行之前进容器做一些调整:
+docker run --rm -it --net=host --gpus=all gpt-academic bash
```
-"Super English to Chinese Translation": {
- # Prefix, which will be added before your input. For example, it is used to describe your requirements, such as translation, code interpretation, polishing, etc.
- "Prefix": "Please translate the following content into Chinese, and then use a markdown table to explain each proprietary term in the text:\n\n",
-
- # Suffix, which will be added after your input. For example, in conjunction with the prefix, you can bracket your input in quotes.
+
+## Installation-Method 3: Other Deployment Methods
+
+1. Remote Cloud Server Deployment
+Please visit [Deployment Wiki-1] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+
+2. Use WSL2 (Windows Subsystem for Linux)
+Please visit [Deployment Wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+
+
+## Installation-Proxy Configuration
+### Method 1: Conventional method
+[Configure Proxy](https://github.com/binary-husky/chatgpt_academic/issues/1)
+
+### Method Two: Step-by-step tutorial for newcomers
+[Step-by-step tutorial for newcomers](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
+
+---
+
+## Customizing Convenient Buttons (Customizing Academic Shortcuts)
+Open `core_functional.py` with any text editor and add an item as follows, then restart the program (if the button has been successfully added and visible, both the prefix and suffix support hot modification without the need to restart the program to take effect). For example:
+```
+"Super English to Chinese translation": {
+ # Prefix, which will be added before your input. For example, to describe your requirements, such as translation, code interpretation, polishing, etc.
+ "Prefix": "Please translate the following content into Chinese and use a markdown table to interpret the proprietary terms in the text one by one:\n\n",
+
+ # Suffix, which will be added after your input. For example, combined with the prefix, you can put your input content in quotes.
"Suffix": "",
-
},
```
+
-
-
-
+---
-After configuring, you can use the following command to test whether the proxy works. If everything is normal, the code below will output the location of your proxy server:
-
-```
-python check_proxy.py
-```
-
-### Method Two: Pure Beginner Tutorial
-[Pure Beginner Tutorial](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
-
-## Compatibility Testing
+## Some Function Displays
### Image Display:
+
+You are a professional academic paper translator.
+
-
-
 @@ -227,7 +231,7 @@ python check_proxy.py
@@ -227,7 +231,7 @@ python check_proxy.py

 -### Latex paper reading comprehension and abstract generation with one click
+### One-click reading comprehension and summary generation of Latex papers
-### Latex paper reading comprehension and abstract generation with one click
+### One-click reading comprehension and summary generation of Latex papers






+
+Fonctionnalité | Description
+--- | ---
+Polissage en un clic | Prend en charge la correction en un clic et la recherche d'erreurs de syntaxe dans les documents de recherche.
+Traduction Chinois-Anglais en un clic | Une touche pour traduire la partie chinoise en anglais ou celle anglaise en chinois.
+Explication de code en un clic | Affiche et explique correctement le code.
+[Raccourcis clavier personnalisables](https://www.bilibili.com/video/BV14s4y1E7jN) | Prend en charge les raccourcis clavier personnalisables.
+[Configuration du serveur proxy](https://www.bilibili.com/video/BV1rc411W7Dr) | Prend en charge la configuration du serveur proxy.
+Conception modulaire | Prend en charge la personnalisation des plugins de fonctions et des [plugins] de fonctions hiérarchiques personnalisés, et les plugins prennent en charge [la mise à jour à chaud](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
+[Auto-analyse du programme](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugins] [Lire en un clic](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) le code source de ce projet.
+[Analyse de programme](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugins] En un clic, les projets Python/C/C++/Java/Lua/... peuvent être analysés.
+Lire le document de recherche | [Plugins] Lisez le résumé de l'article en latex et générer un résumé.
+Traduction et polissage de l'article complet en LaTeX | [Plugins] Une touche pour traduire ou corriger en LaTeX
+Génération Commentaire de fonction en vrac | [Plugins] Lisez en un clic les fonctions et générez des commentaires de fonction.
+Rapport d'analyse automatique des chats générés | [Plugins] Génère un rapport de synthèse après l'exécution.
+[Assistant arxiv](https://www.bilibili.com/video/BV1LM4y1279X) | [Plugins] Entrez l'url de l'article arxiv pour traduire le résumé + télécharger le PDF en un clic
+[Traduction complète des articles PDF](https://www.bilibili.com/video/BV1KT411x7Wn) | [Plugins] Extraire le titre et le résumé de l'article PDF + Traduire le texte entier (multithread)
+[Aide à la recherche Google Academ](https://www.bilibili.com/video/BV19L411U7ia) | [Plugins] Donnez à GPT l'URL de n'importe quelle page de recherche Google Academ pour vous aider à sélectionner des articles intéressants
+Affichage de formules/images/tableaux | Afficher la forme traduite et rendue d'une formule en même temps, plusieurs formules et surlignage du code prend en charge
+Prise en charge des plugins multithread | Prise en charge de l'appel multithread de chatgpt, traitement en masse de texte ou de programmes en un clic
+Activer le thème Gradio sombre [theme](https://github.com/binary-husky/chatgpt_academic/issues/173) au démarrage | Ajoutez ```/?__dark-theme=true``` à l'URL du navigateur pour basculer vers le thème sombre
+[Prise en charge de plusieurs modèles LLM](https://www.bilibili.com/video/BV1wT411p7yf), [prise en charge de l'interface API2D](https://api2d.com/) | Comment cela serait-il de se faire servir par GPT3.5, GPT4 et la [ChatGLM de Tsinghua](https://github.com/THUDM/ChatGLM-6B) en même temps?
+Expérience en ligne d'huggingface sans science | Après vous être connecté à huggingface, copiez [cet espace](https://huggingface.co/spaces/qingxu98/gpt-academic)
+... | ...
+
+
+
+
+Vous êtes un traducteur professionnel d'articles universitaires en français.
+
+Ceci est un fichier Markdown, veuillez le traduire en français sans modifier les commandes Markdown existantes :
+
+- Nouvelle interface (modifiable en modifiant l'option de mise en page dans config.py pour basculer entre les mises en page gauche-droite et haut-bas)
+
+
+
+
+
+- Tous les boutons sont générés dynamiquement en lisant functional.py, les utilisateurs peuvent ajouter librement des fonctions personnalisées pour libérer le presse-papiers.
+
+
+
+
+
+- Correction/amélioration
+
+
+
+
+
+- Si la sortie contient des formules, elles seront affichées simultanément sous forme de de texte brut et de forme rendue pour faciliter la copie et la lecture.
+
+
+
+
+
+- Pas envie de lire le code du projet ? Faites votre propre démo avec ChatGPT.
+
+
+
+
+
+- Utilisation combinée de plusieurs modèles de langage sophistiqués (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
+
+
+
+
+
+Utilisation combinée de plusieurs modèles de langage sophistiqués en version de test [huggingface](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta) (la version huggingface ne prend pas en charge Chatglm).
+
+
+---
+
+## Installation - Méthode 1 : Exécution directe (Windows, Linux or MacOS)
+
+1. Téléchargez le projet
+```sh
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+```
+
+2. Configuration de l'API_KEY et des paramètres de proxy
+
+Dans `config.py`, configurez les paramètres de proxy et de clé d'API OpenAI, comme indiqué ci-dessous
+```
+1. Si vous êtes en Chine, vous devez configurer un proxy étranger pour utiliser l'API OpenAI en toute transparence. Pour ce faire, veuillez lire attentivement le fichier config.py (1. Modifiez l'option USE_PROXY ; 2. Modifiez les paramètres de proxies comme indiqué dans les instructions).
+2. Configurez votre clé API OpenAI. Vous devez vous inscrire sur le site web d'OpenAI pour obtenir une clé API. Une fois que vous avez votre clé API, vous pouvez la configurer dans le fichier config.py.
+3. Tous les problèmes liés aux réseaux de proxy (temps d'attente, non-fonctionnement des proxies) sont résumés dans https://github.com/binary-husky/chatgpt_academic/issues/1.
+```
+(Remarque : le programme vérifie d'abord s'il existe un fichier de configuration privé nommé `config_private.py`, et utilise les configurations de celui-ci à la place de celles du fichier `config.py`. Par conséquent, si vous comprenez notre logique de lecture de configuration, nous vous recommandons fortement de créer un nouveau fichier de configuration nommé `config_private.py` à côté de `config.py` et de transférer (copier) les configurations de celui-ci dans `config_private.py`. `config_private.py` n'est pas contrôlé par git et rend vos informations personnelles plus sûres.)
+
+3. Installation des dépendances
+```sh
+# (Option 1) Recommandé
+python -m pip install -r requirements.txt
+
+# (Option 2) Si vous utilisez anaconda, les étapes sont similaires :
+# (Option 2.1) conda create -n gptac_venv python=3.11
+# (Option 2.2) conda activate gptac_venv
+# (Option 2.3) python -m pip install -r requirements.txt
+
+# note : Utilisez la source pip officielle ou la source pip Alibaba. D'autres sources (comme celles des universités) pourraient poser problème. Pour utiliser temporairement une autre source, utilisez :
+# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+```
+
+Si vous avez besoin de soutenir ChatGLM de Tsinghua, vous devez installer plus de dépendances (si vous n'êtes pas familier avec Python ou que votre ordinateur n'est pas assez performant, nous vous recommandons de ne pas essayer) :
+```sh
+python -m pip install -r request_llm/requirements_chatglm.txt
+```
+
+4. Exécution
+```sh
+python main.py
+```
+
+5. Tester les plugins de fonctions
+```
+- Test Python Project Analysis
+ Dans la zone de saisie, entrez `./crazy_functions/test_project/python/dqn`, puis cliquez sur "Parse Entire Python Project"
+- Test d'auto-lecture du code
+ Cliquez sur "[Démo multi-thread] Parser ce projet lui-même (auto-traduction de la source)"
+- Test du modèle de fonctionnalité expérimentale (exige une réponse de l'IA à ce qui est arrivé aujourd'hui dans l'histoire). Vous pouvez utiliser cette fonctionnalité comme modèle pour des fonctions plus complexes.
+ Cliquez sur "[Démo modèle de plugin de fonction] Histoire du Jour"
+- Le menu déroulant de la zone de plugin de fonctionnalité contient plus de fonctionnalités à sélectionner.
+```
+
+## Installation - Méthode 2 : Utilisation de docker (Linux)
+
+
+Vous êtes un traducteur professionnel d'articles académiques en français.
+
+1. ChatGPT seul (recommandé pour la plupart des gens)
+``` sh
+# Télécharger le projet
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+# Configurer le proxy outre-mer et la clé API OpenAI
+Modifier le fichier config.py avec n'importe quel éditeur de texte
+# Installer
+docker build -t gpt-academic .
+# Exécuter
+docker run --rm -it --net=host gpt-academic
+
+# Tester les modules de fonction
+## Tester la fonction modèle des modules (requiert la réponse de GPT à "qu'est-ce qui s'est passé dans l'histoire aujourd'hui ?"), vous pouvez utiliser cette fonction en tant que modèle pour implémenter des fonctions plus complexes.
+Cliquez sur "[Exemple de modèle de module] Histoire d'aujourd'hui"
+## Tester le résumé écrit pour le projet LaTeX
+Dans la zone de saisie, tapez ./crazy_functions/test_project/latex/attention, puis cliquez sur "Lire le résumé de l'article de recherche LaTeX"
+## Tester l'analyse du projet Python
+Dans la zone de saisie, tapez ./crazy_functions/test_project/python/dqn, puis cliquez sur "Analyser l'ensemble du projet Python"
+
+D'autres fonctions sont disponibles dans la liste déroulante des modules de fonction.
+```
+
+2. ChatGPT+ChatGLM (nécessite une grande connaissance de docker et une configuration informatique suffisamment puissante)
+``` sh
+# Modifier le dockerfile
+cd docs && nano Dockerfile+ChatGLM
+# Comment construire | 如何构建 (Dockerfile+ChatGLM在docs路径下,请先cd docs)
+docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
+# Comment exécuter | 如何运行 (1) Directement exécuter :
+docker run --rm -it --net=host --gpus=all gpt-academic
+# Comment exécuter | 如何运行 (2) Je veux effectuer quelques ajustements dans le conteneur avant de lancer :
+docker run --rm -it --net=host --gpus=all gpt-academic bash
+```
+
+## Installation - Méthode 3 : Autres méthodes de déploiement
+
+1. Déploiement sur un cloud serveur distant
+Veuillez consulter le [wiki de déploiement-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+
+2. Utilisation de WSL2 (Windows Subsystem for Linux)
+Veuillez consulter le [wiki de déploiement-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+
+
+## Configuration de la procuration de l'installation
+### Méthode 1 : Méthode conventionnelle
+[Configuration de la procuration](https://github.com/binary-husky/chatgpt_academic/issues/1)
+
+### Méthode 2 : Tutoriel pour débutant pur
+[Tutoriel pour débutant pur](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
+
+
+---
+
+## Personnalisation des nouveaux boutons pratiques (personnalisation des raccourcis académiques)
+Ouvrez le fichier `core_functional.py` avec n'importe quel éditeur de texte, ajoutez les éléments suivants, puis redémarrez le programme. (Si le bouton a déjà été ajouté avec succès et est visible, le préfixe et le suffixe pris en charge peuvent être modifiés à chaud sans avoir besoin de redémarrer le programme.)
+Par exemple:
+```
+"Traduction Français-Chinois": {
+ # Préfixe, qui sera ajouté avant votre saisie. Par exemple, pour décrire votre demande, telle que la traduction, le débogage de code, l'amélioration, etc.
+ "Prefix": "Veuillez traduire le contenu ci-dessous en chinois, puis expliquer chaque terme propre mentionné dans un tableau Markdown :\n\n",
+
+ # Suffixe, qui sera ajouté après votre saisie. Par exemple, en combinaison avec un préfixe, vous pouvez mettre le contenu de votre saisie entre guillemets.
+ "Suffix": "",
+},
+```
+
+
+
+
+
+
+---
+
+
+## Présentation de certaines fonctionnalités
+
+### Affichage des images:
+
+
+
+
+
+
+
+### Si un programme peut comprendre et décomposer lui-même :
+
+
+
+
+
+
+
+
+
+
+
+
+### Analyse de tout projet Python/Cpp quelconque :
+
+
+
+
+
+
+
+
+
+
+### Lecture et résumé générés automatiquement pour les articles en Latex
+
+
+
+
+
+### Génération de rapports automatique
+
+
+
+
+
+
+
+### Conception de fonctionnalités modulaires
+
+
+
+
+
+
+
+
+
+### Traduction de code source en anglais
+
+
+
+
+
+
+
+## À faire et planification de version :
+- version 3.2+ (à faire) : Prise en charge de plus de paramètres d'interface de plugin de fonction
+- version 3.1 : Prise en charge de l'interrogation simultanée de plusieurs modèles GPT ! Prise en charge de l'API2d, prise en charge de la répartition de charge de plusieurs clés API
+- version 3.0 : Prise en charge de chatglm et d'autres petits llm
+- version 2.6 : Réorganisation de la structure du plugin, amélioration de l'interactivité, ajout de plus de plugins
+- version 2.5 : Mise à jour automatique, résolution du problème de dépassement de jeton et de texte trop long lors de la compilation du code source complet
+- version 2.4 : (1) Ajout de la fonctionnalité de traduction intégrale de PDF ; (2) Ajout d'une fonctionnalité de changement de position de zone de saisie ; (3) Ajout d'une option de disposition verticale ; (4) Optimisation du plugin de fonction multi-thread.
+- version 2.3 : Amélioration de l'interactivité multi-thread
+- version 2.2 : Prise en charge du rechargement à chaud du plugin de fonction
+- version 2.1 : Mise en page pliable
+- version 2.0 : Introduction du plugin de fonction modulaire
+- version 1.0 : Fonctionnalité de base
+
+## Références et apprentissage
+
+```
+De nombreux designs d'autres projets exceptionnels ont été utilisés pour référence dans le code, notamment :
+
+# Projet 1 : De nombreuses astuces ont été empruntées à ChuanhuChatGPT
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# Projet 2 : ChatGLM-6B de Tsinghua :
+https://github.com/THUDM/ChatGLM-6B
+```
+
diff --git a/docs/README_JP.md b/docs/README_JP.md
new file mode 100644
index 0000000..c08c27b
--- /dev/null
+++ b/docs/README_JP.md
@@ -0,0 +1,294 @@
+> **Note**
+>
+> このReadmeファイルは、このプロジェクトのmarkdown翻訳プラグインによって自動的に生成されたもので、100%正確ではない可能性があります。
+>
+
+#
+
+
+機能 | 説明
+--- | ---
+一键修正 | 一键で論文の文法エラーを検索・修正できます
+一键日英翻訳 | 一键で英日の相互翻訳ができます。
+コードの自動解釈 | コードが正しく表示され、解釈できます。
+[カスタムショートカット](https://www.bilibili.com/video/BV14s4y1E7jN) | カスタムショートカットがサポートされます。
+[プロキシサーバーの設定](https://www.bilibili.com/video/BV1rc411W7Dr) | プロキシサーバーの設定ができます。
+モジュール化されたデザイン | 任意の高次の関数プラグインと[関数プラグイン]がカスタムされ、プラグインは[ホットアップデート](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)をサポートします。
+[自己解析プログラム](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン][一键分析](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)はこのプロジェクトのソースコードを解析することができます。
+[プログラムの解析](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン] 一件で他のPython/C/C++/Java/Lua/...プロジェクトツリーを解析できます。
+論文の読解 | [関数プラグイン] 一件でLaTeX論文全文を解読し、要旨を生成できます。
+LaTeX全文翻訳、修正 | [関数プラグイン] 一键でLaTeX論文を翻訳または修正できます。
+一括コードコメント生成 | [関数プラグイン] 一件で関数コメントを自動生成できます。
+chatレポートの自動生成 | [関数プラグイン] 実行後、自動的にサマリーレポートを生成します。
+[arxivアシスタント](https://www.bilibili.com/video/BV1LM4y1279X) | [関数プラグイン] arxiv記事URLを入力すると、要約を自動翻訳+PDFをダウンロードできます。
+[PDF論文全文翻訳機能](https://www.bilibili.com/video/BV1KT411x7Wn) | [関数プラグイン] PDF論文のタイトルと要旨を抽出しながら、全文を翻訳できます(マルチスレッド)。
+[Google Scholar統合アシスタント](https://www.bilibili.com/video/BV19L411U7ia) | [関数プラグイン] Google Scholarの検索ページURLを入力すると、gptが興味深い記事を選択します。
+数式、画像、表の表示 | 数式のtex形式とレンダリング形式を同時に表示し、公式、コードのハイライトがサポートされます。
+マルチスレッド関数プラグインサポート | chatgptのマルチスレッド呼び出しがサポートされ、大量のテキストまたはプログラムを一括で処理できます。
+Dark gradioスタイルの起動(https://github.com/binary-husky/chatgpt_academic/issues/173) | ブラウザのURLに```/?__dark-theme=true```を追加すると、ダークテーマに切り替えることができます。
+[多数のLLMモデル](https://www.bilibili.com/video/BV1wT411p7yf)のサポート、[API2D](https://api2d.com/)インターフェースのサポート | 同時に、GPT3.5、GPT4、[清華ChatGLM](https://github.com/THUDM/ChatGLM-6B)がサポートされている感覚は、きっと素晴らしいはずですね?
+huggingfaceが提供する科学技術ウェブ[体験版](https://huggingface.co/spaces/qingxu98/gpt-academic) | huggingfaceにログインした後[このスペース](https://huggingface.co/spaces/qingxu98/gpt-academic)をコピーしてください。
+…… | ……
+
+
+
+- 新しいインターフェース(config.pyのLAYOUTオプションを変更すると、左右のレイアウトと上下のレイアウトを切り替えることができます)。
+
+
+
+
+
+
+- All buttons are dynamically generated by reading functional.py, and custom functions can be added, freeing up the clipboard.
+
+
+
+
+
+- Polishing/Error Correction
+
+
+
+
+
+- If the output contains formulas, it will be displayed in both tex form and rendering form at the same time for easy copying and reading.
+
+
+
+
+
+- Tired of looking at the project code? Just show chatgpt's mouth the whole project
+
+
+
+
+
+- Various large language models are mixed and called (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
+
+
+
+
+
+Multiple large language models mixed call [huggingface beta](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta) (huggingface version does not support chatglm)
+
+
+---
+
+## Installation-Method 1: Run Directly (Windows, Linux or MacOS)
+
+1. Download the project
+```sh
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+```
+
+2. Configure API_KEY and proxy settings
+
+In `config.py`, configure the overseas proxy and OpenAI API KEY, as explained below.
+```
+1. If you are in China, you need to set up overseas proxies to use the OpenAI API smoothly. Please read config.py carefully for the setting method (1. Change USE_PROXY to True; 2. Modify the proxies according to the instructions).
+2. Configure OpenAI API KEY. You need to register and obtain the API KEY on the OpenAI official website. Once you have the API KEY, configure it in the config.py file.
+3. Issues related to proxy networks (network timeout, proxies not working) are summarized at https://github.com/binary-husky/chatgpt_academic/issues/1
+```
+(P.S. When the program is running, it will first check whether there is a private configuration file named `config_private.py` and use the configuration therein to override the same-named configuration in `config.py`. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file named `config_private.py` next to `config.py` and transfer (copy) the configuration in `config.py` to `config_private.py`. `config_private.py` is not controlled by git, which can make your privacy information more secure.)
+
+3. Install dependencies
+```sh
+# (Option 1) Recommended
+python -m pip install -r requirements.txt
+
+# (Option 2) If you use anaconda, the steps are similar:
+# (Option 2.1) conda create -n gptac_venv python=3.11
+# (Option 2.2) conda activate gptac_venv
+# (Option 2.3) python -m pip install -r requirements.txt
+
+# Note: Use the official pip source or Ali pip source. Other pip sources (such as some universities' pip) may have problems. Temporary switching source method:
+# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+```
+
+If you need to support Tsinghua ChatGLM, you need to install more dependencies separately (if you are not familiar with Python or your computer configuration is not good, it is not recommended to try):
+```sh
+python -m pip install -r request_llm/requirements_chatglm.txt
+```
+
+4. Run
+```sh
+python main.py
+```
+
+5. Test function plugin
+```
+- Test Python project analysis
+ In the input area, enter `./crazy_functions/test_project/python/dqn`, and then click "Analyze the Entire Python Project"
+- Test self-code interpretation
+ Click "[Multi-threaded Demo] Analyze this Project Itself (Self-Translating Source Code)"
+- Test experimental functional template function (requires gpt to answer what happened in history today), you can use this function as a template to implement more complex functions
+ Click "[Function Plugin Template Demo] In History Today"
+- There are more features to choose from in the function plugin dropdown menu
+```
+
+## Installation-Method 2: Using Docker (Linux)
+
+
+あなたは、プロの学術論文翻訳者です。
+
+1. ChatGPTのみを使用(一般的にはこのオプションが推奨されます)
+``` sh
+# プロジェクトをダウンロードします
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+# 海外ProxyとOpenAI API KEYを構成する
+config.pyをテキストエディタで開いて編集します。
+# インストール
+docker build -t gpt-academic .
+# 実行
+docker run --rm -it --net=host gpt-academic
+
+# 関数プラグインのテスト
+## 関数プラグインテンプレート関数をテストします(gptが「今日の歴史で何が起こったか」と答えるように要求します)。この関数をテンプレートとして使用して、より複雑な機能を実装できます。
+[関数プラグインテンプレートDemo]をクリックしてください。
+## LaTexプロジェクトの要約を書くテスト
+入力エリアに./crazy_functions/test_project/latex/attentionを入力し、「LaTex論文を読んで要約を書く」をクリックします。
+## Pythonプロジェクトの解析をテストする
+入力エリアに./crazy_functions/test_project/python/dqnを入力して、「Pythonプロジェクトを解析する」をクリックします。
+
+より多くの機能が関数プラグインエリアのドロップダウンメニューで利用可能です。
+```
+
+2. ChatGPT+ChatGLMを使用する(Dockerに非常に詳しい必要があります + コンピュータの構成が十分に強力な必要があります)
+
+``` sh
+# dockerfileを変更する
+cd docs && nano Dockerfile+ChatGLM
+# How to build | 構築方法(Dockerfile+ChatGLMはdocsのパスにありますので、まずcd docsを実行してください)
+docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
+# How to run | 実行方法 (1) 直接実行:
+docker run --rm -it --net=host --gpus=all gpt-academic
+# How to run | 実行方法 (2) コンテナに入って調整することを予め行いたい場合:
+docker run --rm -it --net=host --gpus=all gpt-academic bash
+```
+
+
+## Installation-Method 3: その他のデプロイ方法
+
+1. クラウドサーバーにリモートでインストールする
+[デプロイwiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+
+2. WSL2を使用する(Windows Subsystem for Linuxサブシステム)
+[デプロイwiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+
+
+## Installation-プロキシ構成
+### 方法1: 標準的な方法
+[プロキシの構成](https://github.com/binary-husky/chatgpt_academic/issues/1)
+
+### 方法2:初心者向けのチュートリアル
+[初心者向けチュートリアル](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
+
+
+---
+
+## カスタムコンビニエンスボタンの作成方法(学術用ショートカットキーをカスタマイズする)
+任意のテキストエディタで`core_functional.py`を開き、以下のエントリを追加し、プログラムを再起動します。 (ボタンが正常に追加されて表示されている場合、プレフィックスとサフィックスは両方ともリアルタイムで変更できるため、プログラムを再起動する必要はありません。)
+例えば
+```
+"超级英译中": {
+ # プレフィックス、あなたの要求を説明するために使用されます。翻訳、コードの解析、精緻化など。
+ "Prefix": "以下の内容を中国語に翻訳し、専門用語が含まれる場合はマークダウン表で1つずつ説明してください:\n\n",
+
+ #サフィックス、プレフィックスと組み合わせて、入力内容を引用符で囲むことができます。
+ "Suffix": "",
+},
+```
+
+
+
+
+
+---
+
+
+## 一部の機能のデモ
+
+### 画像表示:
+
+
+
+
+
+
+
+### プログラムが自分自身を読み取り、分解できる場合:
+
+
+
+
+
+
+
+
+
+
+
+
+### 他のPython/Cppプロジェクトの分析:
+
+
+
+
+
+
+
+
+
+
+### LaTeX論文の読解と要約の自動生成
+
+
+
+
+
+### 自動レポート生成
+
+
+
+
+
+
+
+### モジュール化された機能設計
+
+
+
+
+
+
+
+
+
+### ソースコードを英語に変換する
+
+
+
+
+
+
+
+## タスクとバージョン計画:
+- version 3.2+ (todo): 関数プラグインがより多くのパラメーターインターフェースをサポート
+- version 3.1: 複数のgptモデルを同時に問い合わせるサポート! api2dをサポートし、複数のapikeyの負荷分散をサポート
+- version 3.0: chatglmおよびその他の小規模llmのサポート
+- version 2.6: プラグイン構造を再構築し、対話性を強化し、さらに多くのプラグインを追加
+- version 2.5: 自動更新、長い文章、トークンのオーバーフローを解決する
+- version 2.4: (1) PDF全文翻訳機能を追加。 (2)位置の切り替え機能を追加。 (3)垂直レイアウトオプションを追加。 (4)マルチスレッド関数プラグインの最適化。
+- version 2.3: マルチスレッドの相互作用の強化
+- version 2.2: 関数プラグインのホットリロードをサポート
+- version 2.1: 折りたたみ式レイアウト
+- version 2.0: モジュール化された関数プラグインを導入
+- version 1.0: 基本機能
+
+## 参考と学習
+
+```
+多くの優れたプロジェクトの設計を参考にしています:
+
+# 参考プロジェクト1:ChuanhuChatGPTから多くの技術を借りました
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# 参考プロジェクト2:清華ChatGLM-6B:
+https://github.com/THUDM/ChatGLM-6B
+```
+
+
diff --git a/docs/README_RS.md b/docs/README_RS.md
new file mode 100644
index 0000000..f8d925a
--- /dev/null
+++ b/docs/README_RS.md
@@ -0,0 +1,291 @@
+> **Note**
+>
+> Этот файл самовыражения автоматически генерируется модулем перевода markdown в этом проекте и может быть не на 100% правильным.
+>
+
+#
+
+
+Функция | Описание
+--- | ---
+Редактирование одним кликом | Поддержка редактирования одним кликом, поиск грамматических ошибок в академических статьях
+Переключение языков "Английский-Китайский" одним кликом | Одним кликом переключайте языки "Английский-Китайский"
+Разъяснение программного кода одним кликом | Вы можете правильно отобразить и объяснить программный код.
+[Настраиваемые сочетания клавиш](https://www.bilibili.com/video/BV14s4y1E7jN) | Поддержка настраиваемых сочетаний клавиш
+[Настройка сервера-прокси](https://www.bilibili.com/video/BV1rc411W7Dr) | Поддержка настройки сервера-прокси
+Модульный дизайн | Поддержка настраиваемых функциональных плагинов высших порядков и функциональных плагинов, поддерживающих [горячее обновление](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
+[Автоанализ программы](https://www.bilibili.com/video/BV1cj411A7VW) | [Функциональный плагин] [Прочтение в один клик](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) кода программы проекта
+[Анализ программы](https://www.bilibili.com/video/BV1cj411A7VW) | [Функциональный плагин] Один клик для проанализирования дерева других проектов Python/C/C++/Java/Lua/...
+Чтение статей| [Функциональный плагин] Одним кликом прочитайте весь латех (LaTex) текст статьи и сгенерируйте краткое описание
+Перевод и редактирование всех статей из LaTex | [Функциональный плагин] Перевод или редактирование LaTex-статьи всего одним нажатием кнопки
+Генерация комментариев в пакетном режиме | [Функциональный плагин] Одним кликом сгенерируйте комментарии к функциям в пакетном режиме
+Генерация отчетов пакета CHAT | [Функциональный плагин] Автоматически создавайте сводные отчеты после выполнения
+[Помощник по arxiv](https://www.bilibili.com/video/BV1LM4y1279X) | [Функциональный плагин] Введите URL статьи arxiv, чтобы легко перевести резюме и загрузить PDF-файл
+[Перевод полного текста статьи в формате PDF](https://www.bilibili.com/video/BV1KT411x7Wn) | [Функциональный плагин] Извлеките заголовок статьи, резюме и переведите весь текст статьи (многопоточно)
+[Помощник интеграции Google Scholar](https://www.bilibili.com/video/BV19L411U7ia) | [Функциональный плагин] Дайте GPT выбрать для вас интересные статьи на любой странице поиска Google Scholar.
+Отображение формул/изображений/таблиц | Одновременно отображается tex-форма и рендер-форма формул, поддержка формул, высокоскоростных кодов
+Поддержка функциональных плагинов многопоточности | Поддержка многопоточной работы с плагинами, обрабатывайте огромные объемы текста или программы одним кликом
+Запуск темной темы gradio[подробнее](https://github.com/binary-husky/chatgpt_academic/issues/173) | Добавьте / ?__dark-theme=true в конец URL браузера, чтобы переключиться на темную тему.
+[Поддержка нескольких моделей LLM](https://www.bilibili.com/video/BV1wT411p7yf), поддержка API2D | Находиться между GPT3.5, GPT4 и [清华ChatGLM](https://github.com/THUDM/ChatGLM-6B) должно быть очень приятно, не так ли?
+Альтернатива huggingface без использования научной сети [Онлайн-эксперимент](https://huggingface.co/spaces/qingxu98/gpt-academic) | Войдите в систему, скопируйте пространство [этот пространственный URL](https://huggingface.co/spaces/qingxu98/gpt-academic)
+…… | ……
+
+
+
+
+- Новый интерфейс (вы можете изменить настройку LAYOUT в config.py, чтобы переключаться между "горизонтальным расположением" и "вертикальным расположением")
+
+
+
+
+
+Вы профессиональный переводчик научных статей.
+
+- Все кнопки генерируются динамически путем чтения functional.py и могут быть легко настроены под пользовательские потребности, освобождая буфер обмена.
+
+
+
+
+
+- Редактирование/корректирование
+
+
+
+
+
+- Если вывод содержит формулы, они отображаются одновременно как в формате tex, так и в рендеринговом формате для удобства копирования и чтения.
+
+
+
+
+
+- Лень смотреть код проекта? Просто покажите chatgpt.
+
+
+
+
+
+- Несколько моделей больших языковых моделей смешиваются (ChatGLM + OpenAI-GPT3.5 + [API2D] (https://api2d.com/) -GPT4)
+
+
+
+
+
+Несколько моделей больших языковых моделей смешиваются в [бета-версии huggingface] (https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta) (huggingface-версия не поддерживает chatglm).
+
+
+---
+
+## Установка - Метод 1: Запуск (Windows, Linux или MacOS)
+
+1. Скачайте проект
+```sh
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+```
+
+2. Настройка API_KEY и настройки прокси
+
+В файле `config.py` настройте зарубежный прокси и OpenAI API KEY, пояснения ниже
+```
+1. Если вы находитесь в Китае, вам нужно настроить зарубежный прокси, чтобы использовать OpenAI API. Пожалуйста, внимательно прочитайте config.py для получения инструкций (1. Измените USE_PROXY на True; 2. Измените прокси в соответствии с инструкциями).
+2. Настройка API KEY OpenAI. Вам необходимо зарегистрироваться на сайте OpenAI и получить API KEY. После получения API KEY настройте его в файле config.py.
+3. Вопросы, связанные с сетевыми проблемами (тайм-аут сети, прокси не работает), можно найти здесь: https://github.com/binary-husky/chatgpt_academic/issues/1
+```
+(Примечание: при запуске программы будет проверяться наличие конфиденциального файла конфигурации с именем `config_private.py` и использоваться в нем конфигурация параметров, которая перезаписывает параметры с такими же именами в `config.py`. Поэтому, если вы понимаете логику чтения нашей конфигурации, мы настоятельно рекомендуем вам создать новый файл конфигурации с именем `config_private.py` рядом с `config.py` и переместить (скопировать) настройки из `config.py` в `config_private.py`. `config_private.py` не подвергается контролю git, что делает конфиденциальную информацию более безопасной.)
+
+
+3. Установить зависимости
+```sh
+# (Выбор 1) Рекомендуется
+python -m pip install -r requirements.txt
+
+# (Выбор 2) Если вы используете anaconda, то шаги будут аналогичны:
+# (Шаг 2.1) conda create -n gptac_venv python=3.11
+# (Шаг 2.2) conda activate gptac_venv
+# (Шаг 2.3) python -m pip install -r requirements.txt
+
+# Примечание: используйте официальный источник pip или источник pip.aliyun.com. Другие источники pip могут вызывать проблемы. временный метод замены источника:
+# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+```
+
+Если требуется поддержка TUNA ChatGLM, необходимо установить дополнительные зависимости (если вы неудобны с python, необходимо иметь хорошую конфигурацию компьютера):
+```sh
+python -m pip install -r request_llm/requirements_chatglm.txt
+```
+
+4. Запустите
+```sh
+python main.py
+```
+
+5. Тестовые функции плагина
+```
+- Тестирвоание анализа проекта Python
+ В основной области введите `./crazy_functions/test_project/python/dqn` , а затем нажмите "Анализировать весь проект Python"
+- Тестирование самостоятельного чтения кода
+ Щелкните " [Демонстрационный режим многопоточности] Проанализируйте сам проект (расшифровка источника кода)"
+- Тестирование функций шаблонного плагина (вы можете использовать эту функцию как шаблон для более сложных функций, требующих ответа от gpt в связи с тем, что произошло сегодня в истории)
+ Щелкните " [Функции шаблонного плагина] День в истории"
+- На нижней панели дополнительные функции для выбора
+```
+
+## Установка - Метод 2: Использование docker (Linux)
+
+
+1. Только ChatGPT (рекомендуется для большинства пользователей):
+``` sh
+# Скачать проект
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+# Настроить прокси за границей и OpenAI API KEY
+Отредактируйте файл config.py в любом текстовом редакторе.
+# Установка
+docker build -t gpt-academic .
+# Запустить
+docker run --rm -it --net=host gpt-academic
+
+# Проверка функциональности плагина
+## Проверка шаблонной функции плагина (требуется, чтобы gpt ответил, что произошло "в истории на этот день"), вы можете использовать эту функцию в качестве шаблона для реализации более сложных функций.
+Нажмите "[Шаблонный демонстрационный плагин] История на этот день".
+## Тест абстрактного резюме для проекта на Latex
+В области ввода введите ./crazy_functions/test_project/latex/attention, а затем нажмите "Чтение реферата о тезисах статьи на LaTeX".
+## Тестовый анализ проекта на Python
+Введите в область ввода ./crazy_functions/test_project/python/dqn, затем нажмите "Проанализировать весь проект на Python".
+
+Выбирайте больше функциональных плагинов в нижнем выпадающем меню.
+```
+
+2. ChatGPT + ChatGLM (требуется глубокое знание Docker и достаточно мощное компьютерное оборудование):
+
+``` sh
+# Изменение Dockerfile
+cd docs && nano Dockerfile+ChatGLM
+# Как построить | Как запустить (Dockerfile+ChatGLM в пути docs, сначала перейдите в папку с помощью cd docs)
+docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
+# Как запустить | Как запустить (2) я хочу войти в контейнер и сделать какие-то настройки до запуска:
+docker run --rm -it --net=host --gpus=all gpt-academic bash
+```
+
+
+## Установка-Метод 3: Другие способы развертывания
+
+1. Развертывание на удаленном облачном сервере
+Пожалуйста, посетите [Deploy Wiki-1] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+
+2. Использование WSL2 (Windows Subsystem for Linux)
+Пожалуйста, посетите [Deploy Wiki-2] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+
+
+## Установка-Настройки прокси
+### Метод 1: Обычный способ
+[Конфигурация прокси] (https://github.com/binary-husky/chatgpt_academic/issues/1)
+
+### Метод 2: Руководство новичка
+[Руководство новичка] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
+
+
+---
+
+## Настройка новой удобной кнопки (настройка быстрой клавиши для научной работы)
+Откройте `core_functional.py` любым текстовым редактором, добавьте элементы, как показано ниже, затем перезапустите программу. (Если кнопка уже успешно добавлена и видна, то префикс и суффикс поддерживают горячее изменение, чтобы они оказались в действии, не нужно перезапускать программу.)
+например
+```
+"Супер анг-рус": {
+ # Префикс, будет добавлен перед вашим вводом. Например, используется для описания ваших потребностей, таких как перевод, кодинг, редактирование и т. д.
+ "Prefix": "Пожалуйста, переведите этот фрагмент на русский язык, а затем создайте пошаговую таблицу в markdown, чтобы объяснить все специализированные термины, которые встречаются в тексте:\n\n",
+
+ # Суффикс, будет добавлен после вашего ввода. Например, совместно с префиксом можно обрамить ваш ввод в кавычки.
+ "Suffix": "",
+},
+```
+
+
+
+
+
+---
+
+
+## Демонстрация некоторых возможностей
+
+### Отображение изображений:
+
+
+
+
+
+
+
+### Если программа может понимать и разбирать сама себя:
+
+
+
+
+
+
+
+
+
+
+
+
+### Анализ других проектов на Python/Cpp:
+
+
+
+
+
+
+
+
+
+
+### Генерация понимания и абстрактов с помощью Латех статей в один клик
+
+
+
+
+
+### Автоматическое создание отчетов
+
+
+
+
+
+
+
+### Модульный дизайн функций
+
+
+
+
+
+
+
+
+
+### Трансляция исходного кода на английский язык
+
+
+
+
+
+
+
+## Todo и планирование версий:
+- version 3.2+ (todo): функция плагины поддерживают более многочисленные интерфейсы параметров
+- version 3.1: поддержка одновременного опроса нескольких моделей gpt! Поддержка api2d, поддержка балансировки нагрузки множества apikey.
+- version 3.0: поддержка chatglm и других маленьких llm
+- version 2.6: реструктурировал структуру плагинов, повысил интерактивность, добавил больше плагинов
+- version 2.5: само обновление, решение проблемы слишком длинного текста и переполнения токена при переводе всего проекта исходного кода
+- version 2.4: (1) добавлена функция перевода всего PDF-документа; (2) добавлена функция изменения положения входной области; (3) добавлена опция вертикального макета; (4) оптимизация функций многопоточности плагина.
+- version 2.3: улучшение многопоточной интерактивности
+- version 2.2: функция плагинов поддерживает горячую перезагрузку
+- version 2.1: блочная раскладка
+- version 2.0: модульный дизайн функций плагина
+- version 1.0: основные функции
+
+## Ссылки на изучение и обучение
+
+```
+В коде использовано много хороших дизайнерских решений из других отличных проектов, в том числе:
+
+# Project1: использование многих приемов из ChuanhuChatGPT
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# Project2: ChatGLM-6B в Тхуде:
+https://github.com/THUDM/ChatGLM-6B
+```
+
From 205a6952a2b0926f583d2fcf432301f193b414d1 Mon Sep 17 00:00:00 2001
From: Your Name
+
機能 | 説明
--- | ---
-一键修正 | 一键で論文の文法エラーを検索・修正できます
-一键日英翻訳 | 一键で英日の相互翻訳ができます。
-コードの自動解釈 | コードが正しく表示され、解釈できます。
-[カスタムショートカット](https://www.bilibili.com/video/BV14s4y1E7jN) | カスタムショートカットがサポートされます。
-[プロキシサーバーの設定](https://www.bilibili.com/video/BV1rc411W7Dr) | プロキシサーバーの設定ができます。
-モジュール化されたデザイン | 任意の高次の関数プラグインと[関数プラグイン]がカスタムされ、プラグインは[ホットアップデート](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)をサポートします。
-[自己解析プログラム](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン][一键分析](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)はこのプロジェクトのソースコードを解析することができます。
-[プログラムの解析](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン] 一件で他のPython/C/C++/Java/Lua/...プロジェクトツリーを解析できます。
-論文の読解 | [関数プラグイン] 一件でLaTeX論文全文を解読し、要旨を生成できます。
-LaTeX全文翻訳、修正 | [関数プラグイン] 一键でLaTeX論文を翻訳または修正できます。
-一括コードコメント生成 | [関数プラグイン] 一件で関数コメントを自動生成できます。
-chatレポートの自動生成 | [関数プラグイン] 実行後、自動的にサマリーレポートを生成します。
-[arxivアシスタント](https://www.bilibili.com/video/BV1LM4y1279X) | [関数プラグイン] arxiv記事URLを入力すると、要約を自動翻訳+PDFをダウンロードできます。
-[PDF論文全文翻訳機能](https://www.bilibili.com/video/BV1KT411x7Wn) | [関数プラグイン] PDF論文のタイトルと要旨を抽出しながら、全文を翻訳できます(マルチスレッド)。
-[Google Scholar統合アシスタント](https://www.bilibili.com/video/BV19L411U7ia) | [関数プラグイン] Google Scholarの検索ページURLを入力すると、gptが興味深い記事を選択します。
-数式、画像、表の表示 | 数式のtex形式とレンダリング形式を同時に表示し、公式、コードのハイライトがサポートされます。
-マルチスレッド関数プラグインサポート | chatgptのマルチスレッド呼び出しがサポートされ、大量のテキストまたはプログラムを一括で処理できます。
-Dark gradioスタイルの起動(https://github.com/binary-husky/chatgpt_academic/issues/173) | ブラウザのURLに```/?__dark-theme=true```を追加すると、ダークテーマに切り替えることができます。
-[多数のLLMモデル](https://www.bilibili.com/video/BV1wT411p7yf)のサポート、[API2D](https://api2d.com/)インターフェースのサポート | 同時に、GPT3.5、GPT4、[清華ChatGLM](https://github.com/THUDM/ChatGLM-6B)がサポートされている感覚は、きっと素晴らしいはずですね?
-huggingfaceが提供する科学技術ウェブ[体験版](https://huggingface.co/spaces/qingxu98/gpt-academic) | huggingfaceにログインした後[このスペース](https://huggingface.co/spaces/qingxu98/gpt-academic)をコピーしてください。
-…… | ……
+ワンクリック整形 | 論文の文法エラーを一括で正確に修正できます。
+ワンクリック日英翻訳 | 日英翻訳には、ワンクリックで対応できます。
+ワンクリックコード説明 | コードの正しい表示と説明が可能です。
+[カスタムショートカットキー](https://www.bilibili.com/video/BV14s4y1E7jN) | カスタムショートカットキーをサポートします。
+[プロキシサーバーの設定](https://www.bilibili.com/video/BV1rc411W7Dr) | プロキシサーバーの設定をサポートします。
+モジュラーデザイン | カスタム高階関数プラグインと[関数プラグイン]、プラグイン[ホット更新]のサポートが可能です。詳細は[こちら](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
+[自己プログラム解析](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン][ワンクリック理解](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)このプロジェクトのソースコード
+[プログラム解析機能](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン] ワンクリックで別のPython/C/C++/Java/Lua/...プロジェクトツリーを解析できます。
+論文読解 | [関数プラグイン] LaTeX論文の全文をワンクリックで解読し、要約を生成します。
+LaTeX全文翻訳、整形 | [関数プラグイン] ワンクリックでLaTeX論文を翻訳または整形できます。
+注釈生成 | [関数プラグイン] ワンクリックで関数の注釈を大量に生成できます。
+チャット分析レポート生成 | [関数プラグイン] 実行後、まとめレポートを自動生成します。
+[arxivヘルパー](https://www.bilibili.com/video/BV1LM4y1279X) | [関数プラグイン] 入力したarxivの記事URLで要約をワンクリック翻訳+PDFダウンロードができます。
+[PDF論文全文翻訳機能](https://www.bilibili.com/video/BV1KT411x7Wn) | [関数プラグイン] PDF論文タイトルと要約を抽出し、全文を翻訳します(マルチスレッド)。
+[Google Scholar Integratorヘルパー](https://www.bilibili.com/video/BV19L411U7ia) | [関数プラグイン] 任意のGoogle Scholar検索ページURLを指定すると、gptが興味深い記事を選択します。
+数式/画像/テーブル表示 | 数式のTex形式とレンダリング形式を同時に表示できます。数式、コードのハイライトをサポートしています。
+マルチスレッド関数プラグインサポート | ChatGPTをマルチスレッドで呼び出すことができ、大量のテキストやプログラムを簡単に処理できます。
+ダークグラジオ[テーマ](https://github.com/binary-husky/chatgpt_academic/issues/173)の起動 | 「/?__dark-theme=true」というURLをブラウザに追加することで、ダークテーマに切り替えることができます。
+[多数のLLMモデル](https://www.bilibili.com/video/BV1wT411p7yf)をサポート、[API2D](https://api2d.com/)インターフェースをサポート | GPT3.5、GPT4、[清華ChatGLM](https://github.com/THUDM/ChatGLM-6B)による同時サポートは、とても素晴らしいですね!
+huggingface免科学上网[オンライン版](https://huggingface.co/spaces/qingxu98/gpt-academic) | huggingfaceにログイン後、[このスペース](https://huggingface.co/spaces/qingxu98/gpt-academic)をコピーしてください。
+...... | ......
+
-- 新しいインターフェース(config.pyのLAYOUTオプションを変更すると、左右のレイアウトと上下のレイアウトを切り替えることができます)。
+- 新しいインターフェース(config.pyのLAYOUTオプションを変更するだけで、「左右レイアウト」と「上下レイアウト」を切り替えることができます)
@@ -231,8 +234,8 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
-### LaTeX論文の読解と要約の自動生成
+### Latex論文の一括読解と要約生成
+