@@ -84,45 +81,43 @@ chat分析报告生成 | [实验性功能] 运行后自动生成总结汇报
## 直接运行 (Windows, Linux or MacOS)
-下载项目
-
+### 1. 下载项目
```sh
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-我们建议将`config.py`复制为`config_private.py`并将后者用作个性化配置文件以避免`config.py`中的变更影响你的使用或不小心将包含你的OpenAI API KEY的`config.py`提交至本项目。
+### 2. 配置API_KEY和代理设置
-```sh
-cp config.py config_private.py
+在`config.py`中,配置 海外Proxy 和 OpenAI API KEY,说明如下
```
-
-在`config_private.py`中,配置 海外Proxy 和 OpenAI API KEY
-```
-1. 如果你在国内,需要设置海外代理才能够使用 OpenAI API,你可以通过 config.py 文件来进行设置。
+1. 如果你在国内,需要设置海外代理才能够顺利使用 OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
2. 配置 OpenAI API KEY。你需要在 OpenAI 官网上注册并获取 API KEY。一旦你拿到了 API KEY,在 config.py 文件里配置好即可。
+3. 与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
```
-安装依赖
+(P.S. 程序运行时会优先检查是否存在名为`config_private.py`的私密配置文件,并用其中的配置覆盖`config.py`的同名配置。因此,如果您能理解我们的配置读取逻辑,我们强烈建议您在`config.py`旁边创建一个名为`config_private.py`的新配置文件,并把`config.py`中的配置转移(复制)到`config_private.py`中。`config_private.py`不受git管控,可以让您的隐私信息更加安全。)
+
+### 3. 安装依赖
```sh
-python -m pip install -r requirements.txt
+# (选择一)推荐
+python -m pip install -r requirements.txt
+
+# (选择二)如果您使用anaconda,步骤也是类似的:
+# (选择二.1)conda create -n gptac_venv python=3.11
+# (选择二.2)conda activate gptac_venv
+# (选择二.3)python -m pip install -r requirements.txt
+
+# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:
+# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
```
-或者,如果你希望使用`conda`
-
-```sh
-conda create -n gptac 'gradio>=3.23' requests
-conda activate gptac
-python3 -m pip install mdtex2html
-```
-
-运行
-
+### 4. 运行
```sh
python main.py
```
-测试实验性功能
+### 5. 测试实验性功能
```
- 测试C++项目头文件分析
input区域 输入 `./crazy_functions/test_project/cpp/libJPG` , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
@@ -136,8 +131,6 @@ python main.py
点击 "[实验] 实验功能函数模板"
```
-与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
-
## 使用docker (Linux)
``` sh
@@ -145,7 +138,7 @@ python main.py
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
# 配置 海外Proxy 和 OpenAI API KEY
-config.py
+用任意文本编辑器编辑 config.py
# 安装
docker build -t gpt-academic .
# 运行
@@ -166,20 +159,12 @@ input区域 输入 ./crazy_functions/test_project/python/dqn , 然后点击 "[
```
-## 使用WSL2(Windows Subsystem for Linux 子系统)
-选择这种方式默认您已经具备一定基本知识,因此不再赘述多余步骤。如果不是这样,您可以从[这里](https://learn.microsoft.com/zh-cn/windows/wsl/about)或GPT处获取更多关于子系统的信息。
+## 其他部署方式
+- 使用WSL2(Windows Subsystem for Linux 子系统)
+请访问[部署wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
-WSL2可以配置使用Windows侧的代理上网,前置步骤可以参考[这里](https://www.cnblogs.com/tuilk/p/16287472.html)
-由于Windows相对WSL2的IP会发生变化,我们需要每次启动前先获取这个IP来保证顺利访问,将config.py中设置proxies的部分更改为如下代码:
-```python
-import subprocess
-cmd_get_ip = 'grep -oP "(\d+\.)+(\d+)" /etc/resolv.conf'
-ip_proxy = subprocess.run(
- cmd_get_ip, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True
- ).stdout.strip() # 获取windows的IP
-proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请自行修改
-```
-在启动main.py后,可以在windows浏览器中访问服务。至此测试、使用与上面其他方法无异。
+- nginx远程部署
+请访问[部署wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E7%9A%84%E6%8C%87%E5%AF%BC)
## 自定义新的便捷按钮(学术快捷键自定义)
@@ -204,7 +189,7 @@ proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请
如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests!
## 配置代理
-
+### 方法一:常规方法
在```config.py```中修改端口与代理软件对应
@@ -216,6 +201,8 @@ proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请
```
python check_proxy.py
```
+### 方法二:纯新手教程
+[纯新手教程](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
## 兼容性测试
@@ -259,13 +246,44 @@ python check_proxy.py
### 模块化功能设计
-## Todo:
-- (Top Priority) 调用另一个开源项目text-generation-webui的web接口,使用其他llm模型
-- 总结大工程源代码时,文本过长、token溢出的问题(目前的方法是直接二分丢弃处理溢出,过于粗暴,有效信息大量丢失)
-- UI不够美观
+### 源代码转译英文
+
+
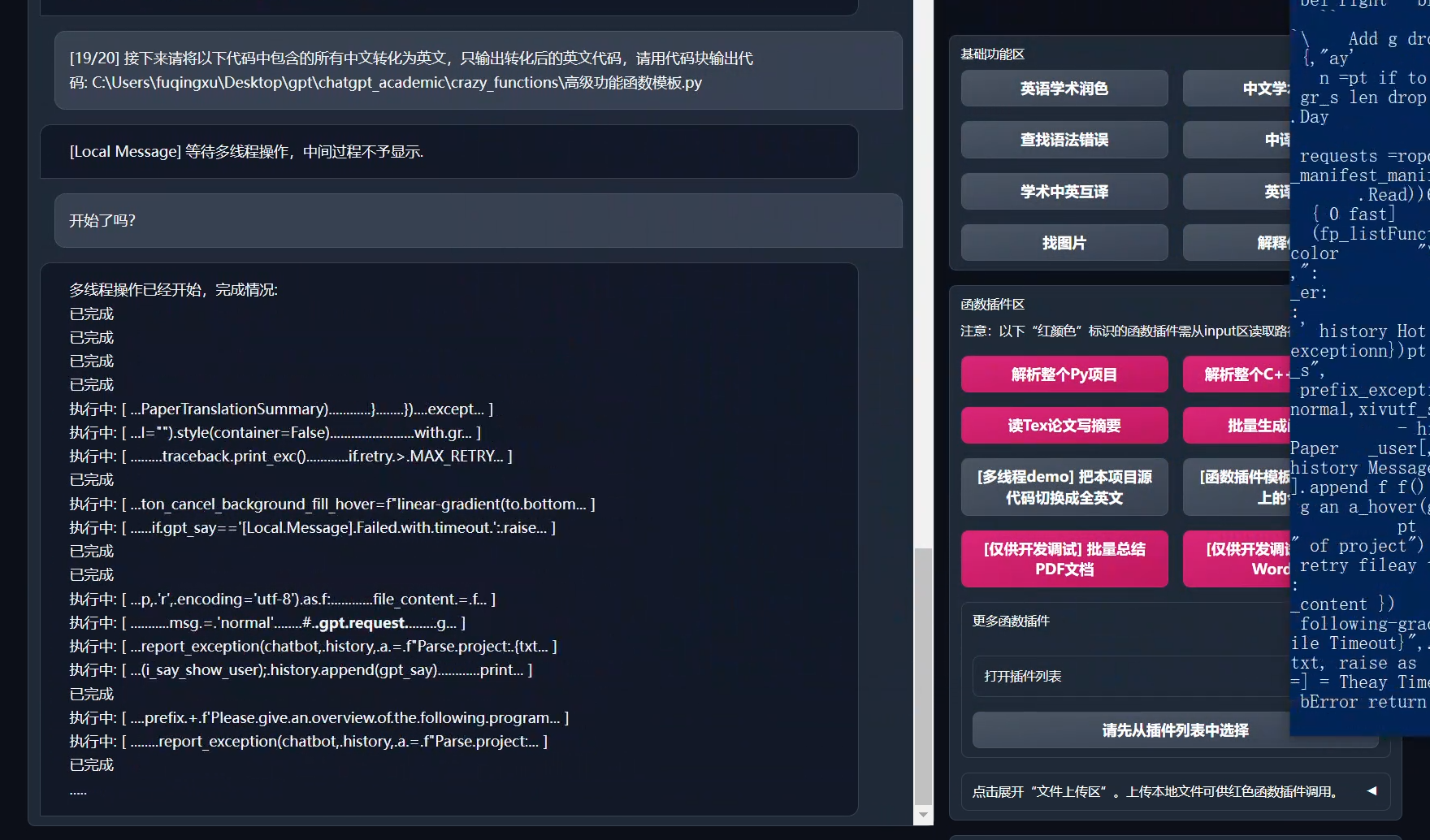
+
+
+## Todo 与 版本规划:
+
+- version 3 (Todo):
+- - 支持gpt4和其他更多llm
+- version 2.4+ (Todo):
+- - 总结大工程源代码时文本过长、token溢出的问题
+- - 实现项目打包部署
+- - 函数插件参数接口优化
+- - 自更新
+- version 2.4: (1)新增PDF全文翻译功能; (2)新增输入区切换位置的功能; (3)新增垂直布局选项; (4)多线程函数插件优化。
+- version 2.3: 增强多线程交互性
+- version 2.2: 函数插件支持热重载
+- version 2.1: 可折叠式布局
+- version 2.0: 引入模块化函数插件
+- version 1.0: 基础功能
+
+## 参考与学习
+
+
+```
+代码中参考了很多其他优秀项目中的设计,主要包括:
+
+# 借鉴项目1:借鉴了ChuanhuChatGPT中读取OpenAI json的方法、记录历史问询记录的方法以及gradio queue的使用技巧
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# 借鉴项目2:借鉴了mdtex2html中公式处理的方法
+https://github.com/polarwinkel/mdtex2html
+
+
+```
diff --git a/check_proxy.py b/check_proxy.py
index a6919dd..95a439e 100644
--- a/check_proxy.py
+++ b/check_proxy.py
@@ -3,7 +3,8 @@ def check_proxy(proxies):
import requests
proxies_https = proxies['https'] if proxies is not None else '无'
try:
- response = requests.get("https://ipapi.co/json/", proxies=proxies, timeout=4)
+ response = requests.get("https://ipapi.co/json/",
+ proxies=proxies, timeout=4)
data = response.json()
print(f'查询代理的地理位置,返回的结果是{data}')
if 'country_name' in data:
@@ -19,9 +20,36 @@ def check_proxy(proxies):
return result
+def auto_update():
+ from toolbox import get_conf
+ import requests
+ import time
+ import json
+ proxies, = get_conf('proxies')
+ response = requests.get("https://raw.githubusercontent.com/binary-husky/chatgpt_academic/master/version",
+ proxies=proxies, timeout=1)
+ remote_json_data = json.loads(response.text)
+ remote_version = remote_json_data['version']
+ if remote_json_data["show_feature"]:
+ new_feature = "新功能:" + remote_json_data["new_feature"]
+ else:
+ new_feature = ""
+ with open('./version', 'r', encoding='utf8') as f:
+ current_version = f.read()
+ current_version = json.loads(current_version)['version']
+ if (remote_version - current_version) >= 0.05:
+ print(
+ f'\n新版本可用。新版本:{remote_version},当前版本:{current_version}。{new_feature}')
+ print('Github更新地址:\nhttps://github.com/binary-husky/chatgpt_academic\n')
+ time.sleep(3)
+ return
+ else:
+ return
+
+
if __name__ == '__main__':
- import os; os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
+ import os
+ os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
from toolbox import get_conf
proxies, = get_conf('proxies')
check_proxy(proxies)
-
\ No newline at end of file
diff --git a/config.py b/config.py
index 7fc73db..f94f183 100644
--- a/config.py
+++ b/config.py
@@ -1,23 +1,31 @@
-# API_KEY = "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" 此key无效
+# [step 1]>> 例如: API_KEY = "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" (此key无效)
API_KEY = "sk-此处填API密钥"
-API_URL = "https://api.openai.com/v1/chat/completions"
-# 改为True应用代理
+# [step 2]>> 改为True应用代理,如果直接在海外服务器部署,此处不修改
USE_PROXY = False
if USE_PROXY:
-
- # 填写格式是 [协议]:// [地址] :[端口] ,
+ # 填写格式是 [协议]:// [地址] :[端口],填写之前不要忘记把USE_PROXY改成True,如果直接在海外服务器部署,此处不修改
# 例如 "socks5h://localhost:11284"
- # [协议] 常见协议无非socks5h/http,例如 v2*** 和 s** 的默认本地协议是socks5h,cl**h 的默认本地协议是http
+ # [协议] 常见协议无非socks5h/http; 例如 v2**y 和 ss* 的默认本地协议是socks5h; 而cl**h 的默认本地协议是http
# [地址] 懂的都懂,不懂就填localhost或者127.0.0.1肯定错不了(localhost意思是代理软件安装在本机上)
- # [端口] 在代理软件的设置里,不同的代理软件界面不一样,但端口号都应该在最显眼的位置上
+ # [端口] 在代理软件的设置里找。虽然不同的代理软件界面不一样,但端口号都应该在最显眼的位置上
# 代理网络的地址,打开你的科学上网软件查看代理的协议(socks5/http)、地址(localhost)和端口(11284)
- proxies = { "http": "socks5h://localhost:11284", "https": "socks5h://localhost:11284", }
- print('网络代理状态:运行。')
+ proxies = {
+ # [协议]:// [地址] :[端口]
+ "http": "socks5h://localhost:11284",
+ "https": "socks5h://localhost:11284",
+ }
else:
proxies = None
- print('网络代理状态:未配置。无代理状态下很可能无法访问。')
+
+
+# [step 3]>> 以下配置可以优化体验,但大部分场合下并不需要修改
+# 对话窗的高度
+CHATBOT_HEIGHT = 1115
+
+# 窗口布局
+LAYOUT = "LEFT-RIGHT" # "LEFT-RIGHT"(左右布局) # "TOP-DOWN"(上下布局)
# 发送请求到OpenAI后,等待多久判定为超时
TIMEOUT_SECONDS = 25
@@ -28,11 +36,15 @@ WEB_PORT = -1
# 如果OpenAI不响应(网络卡顿、代理失败、KEY失效),重试的次数限制
MAX_RETRY = 2
-# 选择的OpenAI模型是(gpt4现在只对申请成功的人开放)
+# OpenAI模型选择是(gpt4现在只对申请成功的人开放)
LLM_MODEL = "gpt-3.5-turbo"
+# OpenAI的API_URL
+API_URL = "https://api.openai.com/v1/chat/completions"
+
# 设置并行使用的线程数
CONCURRENT_COUNT = 100
-# 设置用户名和密码
-AUTHENTICATION = [] # [("username", "password"), ("username2", "password2"), ...]
+# 设置用户名和密码(相关功能不稳定,与gradio版本和网络都相关,如果本地使用不建议加这个)
+# [("username", "password"), ("username2", "password2"), ...]
+AUTHENTICATION = []
diff --git a/functional.py b/core_functional.py
similarity index 56%
rename from functional.py
rename to core_functional.py
index 2ed1507..722abc1 100644
--- a/functional.py
+++ b/core_functional.py
@@ -4,29 +4,38 @@
# 默认按钮颜色是 secondary
from toolbox import clear_line_break
-def get_functionals():
+
+def get_core_functions():
return {
"英语学术润色": {
# 前言
"Prefix": r"Below is a paragraph from an academic paper. Polish the writing to meet the academic style, " +
- r"improve the spelling, grammar, clarity, concision and overall readability. When neccessary, rewrite the whole sentence. " +
+ r"improve the spelling, grammar, clarity, concision and overall readability. When necessary, rewrite the whole sentence. " +
r"Furthermore, list all modification and explain the reasons to do so in markdown table." + "\n\n",
- # 后语
+ # 后语
"Suffix": r"",
"Color": r"secondary", # 按钮颜色
},
"中文学术润色": {
- "Prefix": r"作为一名中文学术论文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性," +
+ "Prefix": r"作为一名中文学术论文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性," +
r"同时分解长句,减少重复,并提供改进建议。请只提供文本的更正版本,避免包括解释。请编辑以下文本" + "\n\n",
"Suffix": r"",
},
"查找语法错误": {
- "Prefix": r"Below is a paragraph from an academic paper. " +
- r"Can you help me ensure that the grammar and the spelling is correct? " +
- r"Do not try to polish the text, if no mistake is found, tell me that this paragraph is good." +
- r"If you find grammar or spelling mistakes, please list mistakes you find in a two-column markdown table, " +
+ "Prefix": r"Can you help me ensure that the grammar and the spelling is correct? " +
+ r"Do not try to polish the text, if no mistake is found, tell me that this paragraph is good." +
+ r"If you find grammar or spelling mistakes, please list mistakes you find in a two-column markdown table, " +
r"put the original text the first column, " +
- r"put the corrected text in the second column and highlight the key words you fixed." + "\n\n",
+ r"put the corrected text in the second column and highlight the key words you fixed.""\n"
+ r"Example:""\n"
+ r"Paragraph: How is you? Do you knows what is it?""\n"
+ r"| Original sentence | Corrected sentence |""\n"
+ r"| :--- | :--- |""\n"
+ r"| How **is** you? | How **are** you? |""\n"
+ r"| Do you **knows** what **is** **it**? | Do you **know** what **it** **is** ? |""\n"
+ r"Below is a paragraph from an academic paper. "
+ r"You need to report all grammar and spelling mistakes as the example before."
+ + "\n\n",
"Suffix": r"",
"PreProcess": clear_line_break, # 预处理:清除换行符
},
@@ -34,9 +43,17 @@ def get_functionals():
"Prefix": r"Please translate following sentence to English:" + "\n\n",
"Suffix": r"",
},
- "学术中译英": {
- "Prefix": r"Please translate following sentence to English with academic writing, and provide some related authoritative examples:" + "\n\n",
- "Suffix": r"",
+ "学术中英互译": {
+ "Prefix": r"I want you to act as a scientific English-Chinese translator, " +
+ r"I will provide you with some paragraphs in one language " +
+ r"and your task is to accurately and academically translate the paragraphs only into the other language. " +
+ r"Do not repeat the original provided paragraphs after translation. " +
+ r"You should use artificial intelligence tools, " +
+ r"such as natural language processing, and rhetorical knowledge " +
+ r"and experience about effective writing techniques to reply. " +
+ r"I'll give you my paragraphs as follows, tell me what language it is written in, and then translate:" + "\n\n",
+ "Suffix": "",
+ "Color": "secondary",
},
"英译中": {
"Prefix": r"请翻译成中文:" + "\n\n",
diff --git a/crazy_functional.py b/crazy_functional.py
new file mode 100644
index 0000000..3e53f54
--- /dev/null
+++ b/crazy_functional.py
@@ -0,0 +1,115 @@
+from toolbox import HotReload # HotReload 的意思是热更新,修改函数插件后,不需要重启程序,代码直接生效
+
+
+def get_crazy_functions():
+ ###################### 第一组插件 ###########################
+ # [第一组插件]: 最早期编写的项目插件和一些demo
+ from crazy_functions.读文章写摘要 import 读文章写摘要
+ from crazy_functions.生成函数注释 import 批量生成函数注释
+ from crazy_functions.解析项目源代码 import 解析项目本身
+ from crazy_functions.解析项目源代码 import 解析一个Python项目
+ from crazy_functions.解析项目源代码 import 解析一个C项目的头文件
+ from crazy_functions.解析项目源代码 import 解析一个C项目
+ from crazy_functions.解析项目源代码 import 解析一个Golang项目
+ from crazy_functions.解析项目源代码 import 解析一个Java项目
+ from crazy_functions.解析项目源代码 import 解析一个Rect项目
+ from crazy_functions.高级功能函数模板 import 高阶功能模板函数
+ from crazy_functions.代码重写为全英文_多线程 import 全项目切换英文
+
+ function_plugins = {
+ "请解析并解构此项目本身(源码自译解)": {
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(解析项目本身)
+ },
+ "解析整个Python项目": {
+ "Color": "stop", # 按钮颜色
+ "Function": HotReload(解析一个Python项目)
+ },
+ "解析整个C++项目头文件": {
+ "Color": "stop", # 按钮颜色
+ "Function": HotReload(解析一个C项目的头文件)
+ },
+ "解析整个C++项目(.cpp/.h)": {
+ "Color": "stop", # 按钮颜色
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(解析一个C项目)
+ },
+ "解析整个Go项目": {
+ "Color": "stop", # 按钮颜色
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(解析一个Golang项目)
+ },
+ "解析整个Java项目": {
+ "Color": "stop", # 按钮颜色
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(解析一个Java项目)
+ },
+ "解析整个React项目": {
+ "Color": "stop", # 按钮颜色
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(解析一个Rect项目)
+ },
+ "读Tex论文写摘要": {
+ "Color": "stop", # 按钮颜色
+ "Function": HotReload(读文章写摘要)
+ },
+ "批量生成函数注释": {
+ "Color": "stop", # 按钮颜色
+ "Function": HotReload(批量生成函数注释)
+ },
+ "[多线程demo] 把本项目源代码切换成全英文": {
+ # HotReload 的意思是热更新,修改函数插件代码后,不需要重启程序,代码直接生效
+ "Function": HotReload(全项目切换英文)
+ },
+ "[函数插件模板demo] 历史上的今天": {
+ # HotReload 的意思是热更新,修改函数插件代码后,不需要重启程序,代码直接生效
+ "Function": HotReload(高阶功能模板函数)
+ },
+ }
+ ###################### 第二组插件 ###########################
+ # [第二组插件]: 经过充分测试,但功能上距离达到完美状态还差一点点
+ from crazy_functions.批量总结PDF文档 import 批量总结PDF文档
+ from crazy_functions.批量总结PDF文档pdfminer import 批量总结PDF文档pdfminer
+ from crazy_functions.总结word文档 import 总结word文档
+ from crazy_functions.批量翻译PDF文档_多线程 import 批量翻译PDF文档
+
+ function_plugins.update({
+ "批量翻译PDF文档(多线程)": {
+ "Color": "stop",
+ "AsButton": True, # 加入下拉菜单中
+ "Function": HotReload(批量翻译PDF文档)
+ },
+ "[仅供开发调试] 批量总结PDF文档": {
+ "Color": "stop",
+ "AsButton": False, # 加入下拉菜单中
+ # HotReload 的意思是热更新,修改函数插件代码后,不需要重启程序,代码直接生效
+ "Function": HotReload(批量总结PDF文档)
+ },
+ "[仅供开发调试] 批量总结PDF文档pdfminer": {
+ "Color": "stop",
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(批量总结PDF文档pdfminer)
+ },
+ "批量总结Word文档": {
+ "Color": "stop",
+ "Function": HotReload(总结word文档)
+ },
+ })
+
+ ###################### 第三组插件 ###########################
+ # [第三组插件]: 尚未充分测试的函数插件,放在这里
+ try:
+ from crazy_functions.下载arxiv论文翻译摘要 import 下载arxiv论文并翻译摘要
+ function_plugins.update({
+ "一键下载arxiv论文并翻译摘要(先在input输入编号,如1812.10695)": {
+ "Color": "stop",
+ "AsButton": False, # 加入下拉菜单中
+ "Function": HotReload(下载arxiv论文并翻译摘要)
+ }
+ })
+
+ except Exception as err:
+ print(f'[下载arxiv论文并翻译摘要] 插件导入失败 {str(err)}')
+
+ ###################### 第n组插件 ###########################
+ return function_plugins
diff --git a/crazy_functions/__init__.py b/crazy_functions/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/crazy_functions/crazy_utils.py b/crazy_functions/crazy_utils.py
new file mode 100644
index 0000000..bdd6e2b
--- /dev/null
+++ b/crazy_functions/crazy_utils.py
@@ -0,0 +1,153 @@
+
+
+def request_gpt_model_in_new_thread_with_ui_alive(inputs, inputs_show_user, top_p, temperature, chatbot, history, sys_prompt, refresh_interval=0.2):
+ import time
+ from concurrent.futures import ThreadPoolExecutor
+ from request_llm.bridge_chatgpt import predict_no_ui_long_connection
+ # 用户反馈
+ chatbot.append([inputs_show_user, ""])
+ msg = '正常'
+ yield chatbot, [], msg
+ executor = ThreadPoolExecutor(max_workers=16)
+ mutable = ["", time.time()]
+ future = executor.submit(lambda:
+ predict_no_ui_long_connection(
+ inputs=inputs, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt, observe_window=mutable)
+ )
+ while True:
+ # yield一次以刷新前端页面
+ time.sleep(refresh_interval)
+ # “喂狗”(看门狗)
+ mutable[1] = time.time()
+ if future.done():
+ break
+ chatbot[-1] = [chatbot[-1][0], mutable[0]]
+ msg = "正常"
+ yield chatbot, [], msg
+ return future.result()
+
+
+def request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency(inputs_array, inputs_show_user_array, top_p, temperature, chatbot, history_array, sys_prompt_array, refresh_interval=0.2, max_workers=10, scroller_max_len=30):
+ import time
+ from concurrent.futures import ThreadPoolExecutor
+ from request_llm.bridge_chatgpt import predict_no_ui_long_connection
+ assert len(inputs_array) == len(history_array)
+ assert len(inputs_array) == len(sys_prompt_array)
+ executor = ThreadPoolExecutor(max_workers=max_workers)
+ n_frag = len(inputs_array)
+ # 用户反馈
+ chatbot.append(["请开始多线程操作。", ""])
+ msg = '正常'
+ yield chatbot, [], msg
+ # 异步原子
+ mutable = [["", time.time()] for _ in range(n_frag)]
+
+ def _req_gpt(index, inputs, history, sys_prompt):
+ gpt_say = predict_no_ui_long_connection(
+ inputs=inputs, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt, observe_window=mutable[
+ index]
+ )
+ return gpt_say
+ # 异步任务开始
+ futures = [executor.submit(_req_gpt, index, inputs, history, sys_prompt) for index, inputs, history, sys_prompt in zip(
+ range(len(inputs_array)), inputs_array, history_array, sys_prompt_array)]
+ cnt = 0
+ while True:
+ # yield一次以刷新前端页面
+ time.sleep(refresh_interval)
+ cnt += 1
+ worker_done = [h.done() for h in futures]
+ if all(worker_done):
+ executor.shutdown()
+ break
+ # 更好的UI视觉效果
+ observe_win = []
+ # 每个线程都要“喂狗”(看门狗)
+ for thread_index, _ in enumerate(worker_done):
+ mutable[thread_index][1] = time.time()
+ # 在前端打印些好玩的东西
+ for thread_index, _ in enumerate(worker_done):
+ print_something_really_funny = "[ ...`"+mutable[thread_index][0][-scroller_max_len:].\
+ replace('\n', '').replace('```', '...').replace(
+ ' ', '.').replace('
', '.....').replace('$', '.')+"`... ]"
+ observe_win.append(print_something_really_funny)
+ stat_str = ''.join([f'执行中: {obs}\n\n' if not done else '已完成\n\n' for done, obs in zip(
+ worker_done, observe_win)])
+ chatbot[-1] = [chatbot[-1][0],
+ f'多线程操作已经开始,完成情况: \n\n{stat_str}' + ''.join(['.']*(cnt % 10+1))]
+ msg = "正常"
+ yield chatbot, [], msg
+ # 异步任务结束
+ gpt_response_collection = []
+ for inputs_show_user, f in zip(inputs_show_user_array, futures):
+ gpt_res = f.result()
+ gpt_response_collection.extend([inputs_show_user, gpt_res])
+ return gpt_response_collection
+
+
+def breakdown_txt_to_satisfy_token_limit(txt, get_token_fn, limit):
+ def cut(txt_tocut, must_break_at_empty_line): # 递归
+ if get_token_fn(txt_tocut) <= limit:
+ return [txt_tocut]
+ else:
+ lines = txt_tocut.split('\n')
+ estimated_line_cut = limit / get_token_fn(txt_tocut) * len(lines)
+ estimated_line_cut = int(estimated_line_cut)
+ for cnt in reversed(range(estimated_line_cut)):
+ if must_break_at_empty_line:
+ if lines[cnt] != "":
+ continue
+ print(cnt)
+ prev = "\n".join(lines[:cnt])
+ post = "\n".join(lines[cnt:])
+ if get_token_fn(prev) < limit:
+ break
+ if cnt == 0:
+ print('what the fuck ?')
+ raise RuntimeError("存在一行极长的文本!")
+ # print(len(post))
+ # 列表递归接龙
+ result = [prev]
+ result.extend(cut(post, must_break_at_empty_line))
+ return result
+ try:
+ return cut(txt, must_break_at_empty_line=True)
+ except RuntimeError:
+ return cut(txt, must_break_at_empty_line=False)
+
+
+def breakdown_txt_to_satisfy_token_limit_for_pdf(txt, get_token_fn, limit):
+ def cut(txt_tocut, must_break_at_empty_line): # 递归
+ if get_token_fn(txt_tocut) <= limit:
+ return [txt_tocut]
+ else:
+ lines = txt_tocut.split('\n')
+ estimated_line_cut = limit / get_token_fn(txt_tocut) * len(lines)
+ estimated_line_cut = int(estimated_line_cut)
+ cnt = 0
+ for cnt in reversed(range(estimated_line_cut)):
+ if must_break_at_empty_line:
+ if lines[cnt] != "":
+ continue
+ print(cnt)
+ prev = "\n".join(lines[:cnt])
+ post = "\n".join(lines[cnt:])
+ if get_token_fn(prev) < limit:
+ break
+ if cnt == 0:
+ # print('what the fuck ? 存在一行极长的文本!')
+ raise RuntimeError("存在一行极长的文本!")
+ # print(len(post))
+ # 列表递归接龙
+ result = [prev]
+ result.extend(cut(post, must_break_at_empty_line))
+ return result
+ try:
+ return cut(txt, must_break_at_empty_line=True)
+ except RuntimeError:
+ try:
+ return cut(txt, must_break_at_empty_line=False)
+ except RuntimeError:
+ # 这个中文的句号是故意的,作为一个标识而存在
+ res = cut(txt.replace('.', '。\n'), must_break_at_empty_line=False)
+ return [r.replace('。\n', '.') for r in res]
diff --git a/crazy_functions/test_project/cpp/longcode/jpgd.cpp b/crazy_functions/test_project/cpp/longcode/jpgd.cpp
new file mode 100644
index 0000000..36d06c8
--- /dev/null
+++ b/crazy_functions/test_project/cpp/longcode/jpgd.cpp
@@ -0,0 +1,3276 @@
+// jpgd.cpp - C++ class for JPEG decompression.
+// Public domain, Rich Geldreich
+// Last updated Apr. 16, 2011
+// Alex Evans: Linear memory allocator (taken from jpge.h).
+//
+// Supports progressive and baseline sequential JPEG image files, and the most common chroma subsampling factors: Y, H1V1, H2V1, H1V2, and H2V2.
+//
+// Chroma upsampling quality: H2V2 is upsampled in the frequency domain, H2V1 and H1V2 are upsampled using point sampling.
+// Chroma upsampling reference: "Fast Scheme for Image Size Change in the Compressed Domain"
+// http://vision.ai.uiuc.edu/~dugad/research/dct/index.html
+
+#include "jpgd.h"
+#include
+
+#include
+// BEGIN EPIC MOD
+#define JPGD_ASSERT(x) { assert(x); CA_ASSUME(x); } (void)0
+// END EPIC MOD
+
+#ifdef _MSC_VER
+#pragma warning (disable : 4611) // warning C4611: interaction between '_setjmp' and C++ object destruction is non-portable
+#endif
+
+// Set to 1 to enable freq. domain chroma upsampling on images using H2V2 subsampling (0=faster nearest neighbor sampling).
+// This is slower, but results in higher quality on images with highly saturated colors.
+#define JPGD_SUPPORT_FREQ_DOMAIN_UPSAMPLING 1
+
+#define JPGD_TRUE (1)
+#define JPGD_FALSE (0)
+
+#define JPGD_MAX(a,b) (((a)>(b)) ? (a) : (b))
+#define JPGD_MIN(a,b) (((a)<(b)) ? (a) : (b))
+
+namespace jpgd {
+
+ static inline void *jpgd_malloc(size_t nSize) { return FMemory::Malloc(nSize); }
+ static inline void jpgd_free(void *p) { FMemory::Free(p); }
+
+// BEGIN EPIC MOD
+//@UE3 - use UE3 BGRA encoding instead of assuming RGBA
+ // stolen from IImageWrapper.h
+ enum ERGBFormatJPG
+ {
+ Invalid = -1,
+ RGBA = 0,
+ BGRA = 1,
+ Gray = 2,
+ };
+ static ERGBFormatJPG jpg_format;
+// END EPIC MOD
+
+ // DCT coefficients are stored in this sequence.
+ static int g_ZAG[64] = { 0,1,8,16,9,2,3,10,17,24,32,25,18,11,4,5,12,19,26,33,40,48,41,34,27,20,13,6,7,14,21,28,35,42,49,56,57,50,43,36,29,22,15,23,30,37,44,51,58,59,52,45,38,31,39,46,53,60,61,54,47,55,62,63 };
+
+ enum JPEG_MARKER
+ {
+ M_SOF0 = 0xC0, M_SOF1 = 0xC1, M_SOF2 = 0xC2, M_SOF3 = 0xC3, M_SOF5 = 0xC5, M_SOF6 = 0xC6, M_SOF7 = 0xC7, M_JPG = 0xC8,
+ M_SOF9 = 0xC9, M_SOF10 = 0xCA, M_SOF11 = 0xCB, M_SOF13 = 0xCD, M_SOF14 = 0xCE, M_SOF15 = 0xCF, M_DHT = 0xC4, M_DAC = 0xCC,
+ M_RST0 = 0xD0, M_RST1 = 0xD1, M_RST2 = 0xD2, M_RST3 = 0xD3, M_RST4 = 0xD4, M_RST5 = 0xD5, M_RST6 = 0xD6, M_RST7 = 0xD7,
+ M_SOI = 0xD8, M_EOI = 0xD9, M_SOS = 0xDA, M_DQT = 0xDB, M_DNL = 0xDC, M_DRI = 0xDD, M_DHP = 0xDE, M_EXP = 0xDF,
+ M_APP0 = 0xE0, M_APP15 = 0xEF, M_JPG0 = 0xF0, M_JPG13 = 0xFD, M_COM = 0xFE, M_TEM = 0x01, M_ERROR = 0x100, RST0 = 0xD0
+ };
+
+ enum JPEG_SUBSAMPLING { JPGD_GRAYSCALE = 0, JPGD_YH1V1, JPGD_YH2V1, JPGD_YH1V2, JPGD_YH2V2 };
+
+#define CONST_BITS 13
+#define PASS1_BITS 2
+#define SCALEDONE ((int32)1)
+
+#define FIX_0_298631336 ((int32)2446) /* FIX(0.298631336) */
+#define FIX_0_390180644 ((int32)3196) /* FIX(0.390180644) */
+#define FIX_0_541196100 ((int32)4433) /* FIX(0.541196100) */
+#define FIX_0_765366865 ((int32)6270) /* FIX(0.765366865) */
+#define FIX_0_899976223 ((int32)7373) /* FIX(0.899976223) */
+#define FIX_1_175875602 ((int32)9633) /* FIX(1.175875602) */
+#define FIX_1_501321110 ((int32)12299) /* FIX(1.501321110) */
+#define FIX_1_847759065 ((int32)15137) /* FIX(1.847759065) */
+#define FIX_1_961570560 ((int32)16069) /* FIX(1.961570560) */
+#define FIX_2_053119869 ((int32)16819) /* FIX(2.053119869) */
+#define FIX_2_562915447 ((int32)20995) /* FIX(2.562915447) */
+#define FIX_3_072711026 ((int32)25172) /* FIX(3.072711026) */
+
+#define DESCALE(x,n) (((x) + (SCALEDONE << ((n)-1))) >> (n))
+#define DESCALE_ZEROSHIFT(x,n) (((x) + (128 << (n)) + (SCALEDONE << ((n)-1))) >> (n))
+
+#define MULTIPLY(var, cnst) ((var) * (cnst))
+
+#define CLAMP(i) ((static_cast(i) > 255) ? (((~i) >> 31) & 0xFF) : (i))
+
+ // Compiler creates a fast path 1D IDCT for X non-zero columns
+ template
+ struct Row
+ {
+ static void idct(int* pTemp, const jpgd_block_t* pSrc)
+ {
+ // ACCESS_COL() will be optimized at compile time to either an array access, or 0.
+#define ACCESS_COL(x) (((x) < NONZERO_COLS) ? (int)pSrc[x] : 0)
+
+ const int z2 = ACCESS_COL(2), z3 = ACCESS_COL(6);
+
+ const int z1 = MULTIPLY(z2 + z3, FIX_0_541196100);
+ const int tmp2 = z1 + MULTIPLY(z3, - FIX_1_847759065);
+ const int tmp3 = z1 + MULTIPLY(z2, FIX_0_765366865);
+
+ const int tmp0 = (ACCESS_COL(0) + ACCESS_COL(4)) << CONST_BITS;
+ const int tmp1 = (ACCESS_COL(0) - ACCESS_COL(4)) << CONST_BITS;
+
+ const int tmp10 = tmp0 + tmp3, tmp13 = tmp0 - tmp3, tmp11 = tmp1 + tmp2, tmp12 = tmp1 - tmp2;
+
+ const int atmp0 = ACCESS_COL(7), atmp1 = ACCESS_COL(5), atmp2 = ACCESS_COL(3), atmp3 = ACCESS_COL(1);
+
+ const int bz1 = atmp0 + atmp3, bz2 = atmp1 + atmp2, bz3 = atmp0 + atmp2, bz4 = atmp1 + atmp3;
+ const int bz5 = MULTIPLY(bz3 + bz4, FIX_1_175875602);
+
+ const int az1 = MULTIPLY(bz1, - FIX_0_899976223);
+ const int az2 = MULTIPLY(bz2, - FIX_2_562915447);
+ const int az3 = MULTIPLY(bz3, - FIX_1_961570560) + bz5;
+ const int az4 = MULTIPLY(bz4, - FIX_0_390180644) + bz5;
+
+ const int btmp0 = MULTIPLY(atmp0, FIX_0_298631336) + az1 + az3;
+ const int btmp1 = MULTIPLY(atmp1, FIX_2_053119869) + az2 + az4;
+ const int btmp2 = MULTIPLY(atmp2, FIX_3_072711026) + az2 + az3;
+ const int btmp3 = MULTIPLY(atmp3, FIX_1_501321110) + az1 + az4;
+
+ pTemp[0] = DESCALE(tmp10 + btmp3, CONST_BITS-PASS1_BITS);
+ pTemp[7] = DESCALE(tmp10 - btmp3, CONST_BITS-PASS1_BITS);
+ pTemp[1] = DESCALE(tmp11 + btmp2, CONST_BITS-PASS1_BITS);
+ pTemp[6] = DESCALE(tmp11 - btmp2, CONST_BITS-PASS1_BITS);
+ pTemp[2] = DESCALE(tmp12 + btmp1, CONST_BITS-PASS1_BITS);
+ pTemp[5] = DESCALE(tmp12 - btmp1, CONST_BITS-PASS1_BITS);
+ pTemp[3] = DESCALE(tmp13 + btmp0, CONST_BITS-PASS1_BITS);
+ pTemp[4] = DESCALE(tmp13 - btmp0, CONST_BITS-PASS1_BITS);
+ }
+ };
+
+ template <>
+ struct Row<0>
+ {
+ static void idct(int* pTemp, const jpgd_block_t* pSrc)
+ {
+#ifdef _MSC_VER
+ pTemp; pSrc;
+#endif
+ }
+ };
+
+ template <>
+ struct Row<1>
+ {
+ static void idct(int* pTemp, const jpgd_block_t* pSrc)
+ {
+ const int dcval = (pSrc[0] << PASS1_BITS);
+
+ pTemp[0] = dcval;
+ pTemp[1] = dcval;
+ pTemp[2] = dcval;
+ pTemp[3] = dcval;
+ pTemp[4] = dcval;
+ pTemp[5] = dcval;
+ pTemp[6] = dcval;
+ pTemp[7] = dcval;
+ }
+ };
+
+ // Compiler creates a fast path 1D IDCT for X non-zero rows
+ template
+ struct Col
+ {
+ static void idct(uint8* pDst_ptr, const int* pTemp)
+ {
+ // ACCESS_ROW() will be optimized at compile time to either an array access, or 0.
+#define ACCESS_ROW(x) (((x) < NONZERO_ROWS) ? pTemp[x * 8] : 0)
+
+ const int z2 = ACCESS_ROW(2);
+ const int z3 = ACCESS_ROW(6);
+
+ const int z1 = MULTIPLY(z2 + z3, FIX_0_541196100);
+ const int tmp2 = z1 + MULTIPLY(z3, - FIX_1_847759065);
+ const int tmp3 = z1 + MULTIPLY(z2, FIX_0_765366865);
+
+ const int tmp0 = (ACCESS_ROW(0) + ACCESS_ROW(4)) << CONST_BITS;
+ const int tmp1 = (ACCESS_ROW(0) - ACCESS_ROW(4)) << CONST_BITS;
+
+ const int tmp10 = tmp0 + tmp3, tmp13 = tmp0 - tmp3, tmp11 = tmp1 + tmp2, tmp12 = tmp1 - tmp2;
+
+ const int atmp0 = ACCESS_ROW(7), atmp1 = ACCESS_ROW(5), atmp2 = ACCESS_ROW(3), atmp3 = ACCESS_ROW(1);
+
+ const int bz1 = atmp0 + atmp3, bz2 = atmp1 + atmp2, bz3 = atmp0 + atmp2, bz4 = atmp1 + atmp3;
+ const int bz5 = MULTIPLY(bz3 + bz4, FIX_1_175875602);
+
+ const int az1 = MULTIPLY(bz1, - FIX_0_899976223);
+ const int az2 = MULTIPLY(bz2, - FIX_2_562915447);
+ const int az3 = MULTIPLY(bz3, - FIX_1_961570560) + bz5;
+ const int az4 = MULTIPLY(bz4, - FIX_0_390180644) + bz5;
+
+ const int btmp0 = MULTIPLY(atmp0, FIX_0_298631336) + az1 + az3;
+ const int btmp1 = MULTIPLY(atmp1, FIX_2_053119869) + az2 + az4;
+ const int btmp2 = MULTIPLY(atmp2, FIX_3_072711026) + az2 + az3;
+ const int btmp3 = MULTIPLY(atmp3, FIX_1_501321110) + az1 + az4;
+
+ int i = DESCALE_ZEROSHIFT(tmp10 + btmp3, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*0] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp10 - btmp3, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*7] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp11 + btmp2, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*1] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp11 - btmp2, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*6] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp12 + btmp1, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*2] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp12 - btmp1, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*5] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp13 + btmp0, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*3] = (uint8)CLAMP(i);
+
+ i = DESCALE_ZEROSHIFT(tmp13 - btmp0, CONST_BITS+PASS1_BITS+3);
+ pDst_ptr[8*4] = (uint8)CLAMP(i);
+ }
+ };
+
+ template <>
+ struct Col<1>
+ {
+ static void idct(uint8* pDst_ptr, const int* pTemp)
+ {
+ int dcval = DESCALE_ZEROSHIFT(pTemp[0], PASS1_BITS+3);
+ const uint8 dcval_clamped = (uint8)CLAMP(dcval);
+ pDst_ptr[0*8] = dcval_clamped;
+ pDst_ptr[1*8] = dcval_clamped;
+ pDst_ptr[2*8] = dcval_clamped;
+ pDst_ptr[3*8] = dcval_clamped;
+ pDst_ptr[4*8] = dcval_clamped;
+ pDst_ptr[5*8] = dcval_clamped;
+ pDst_ptr[6*8] = dcval_clamped;
+ pDst_ptr[7*8] = dcval_clamped;
+ }
+ };
+
+ static const uint8 s_idct_row_table[] =
+ {
+ 1,0,0,0,0,0,0,0, 2,0,0,0,0,0,0,0, 2,1,0,0,0,0,0,0, 2,1,1,0,0,0,0,0, 2,2,1,0,0,0,0,0, 3,2,1,0,0,0,0,0, 4,2,1,0,0,0,0,0, 4,3,1,0,0,0,0,0,
+ 4,3,2,0,0,0,0,0, 4,3,2,1,0,0,0,0, 4,3,2,1,1,0,0,0, 4,3,2,2,1,0,0,0, 4,3,3,2,1,0,0,0, 4,4,3,2,1,0,0,0, 5,4,3,2,1,0,0,0, 6,4,3,2,1,0,0,0,
+ 6,5,3,2,1,0,0,0, 6,5,4,2,1,0,0,0, 6,5,4,3,1,0,0,0, 6,5,4,3,2,0,0,0, 6,5,4,3,2,1,0,0, 6,5,4,3,2,1,1,0, 6,5,4,3,2,2,1,0, 6,5,4,3,3,2,1,0,
+ 6,5,4,4,3,2,1,0, 6,5,5,4,3,2,1,0, 6,6,5,4,3,2,1,0, 7,6,5,4,3,2,1,0, 8,6,5,4,3,2,1,0, 8,7,5,4,3,2,1,0, 8,7,6,4,3,2,1,0, 8,7,6,5,3,2,1,0,
+ 8,7,6,5,4,2,1,0, 8,7,6,5,4,3,1,0, 8,7,6,5,4,3,2,0, 8,7,6,5,4,3,2,1, 8,7,6,5,4,3,2,2, 8,7,6,5,4,3,3,2, 8,7,6,5,4,4,3,2, 8,7,6,5,5,4,3,2,
+ 8,7,6,6,5,4,3,2, 8,7,7,6,5,4,3,2, 8,8,7,6,5,4,3,2, 8,8,8,6,5,4,3,2, 8,8,8,7,5,4,3,2, 8,8,8,7,6,4,3,2, 8,8,8,7,6,5,3,2, 8,8,8,7,6,5,4,2,
+ 8,8,8,7,6,5,4,3, 8,8,8,7,6,5,4,4, 8,8,8,7,6,5,5,4, 8,8,8,7,6,6,5,4, 8,8,8,7,7,6,5,4, 8,8,8,8,7,6,5,4, 8,8,8,8,8,6,5,4, 8,8,8,8,8,7,5,4,
+ 8,8,8,8,8,7,6,4, 8,8,8,8,8,7,6,5, 8,8,8,8,8,7,6,6, 8,8,8,8,8,7,7,6, 8,8,8,8,8,8,7,6, 8,8,8,8,8,8,8,6, 8,8,8,8,8,8,8,7, 8,8,8,8,8,8,8,8,
+ };
+
+ static const uint8 s_idct_col_table[] = { 1, 1, 2, 3, 3, 3, 3, 3, 3, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8 };
+
+ void idct(const jpgd_block_t* pSrc_ptr, uint8* pDst_ptr, int block_max_zag)
+ {
+ JPGD_ASSERT(block_max_zag >= 1);
+ JPGD_ASSERT(block_max_zag <= 64);
+
+ if (block_max_zag == 1)
+ {
+ int k = ((pSrc_ptr[0] + 4) >> 3) + 128;
+ k = CLAMP(k);
+ k = k | (k<<8);
+ k = k | (k<<16);
+
+ for (int i = 8; i > 0; i--)
+ {
+ *(int*)&pDst_ptr[0] = k;
+ *(int*)&pDst_ptr[4] = k;
+ pDst_ptr += 8;
+ }
+ return;
+ }
+
+ int temp[64];
+
+ const jpgd_block_t* pSrc = pSrc_ptr;
+ int* pTemp = temp;
+
+ const uint8* pRow_tab = &s_idct_row_table[(block_max_zag - 1) * 8];
+ int i;
+ for (i = 8; i > 0; i--, pRow_tab++)
+ {
+ switch (*pRow_tab)
+ {
+ case 0: Row<0>::idct(pTemp, pSrc); break;
+ case 1: Row<1>::idct(pTemp, pSrc); break;
+ case 2: Row<2>::idct(pTemp, pSrc); break;
+ case 3: Row<3>::idct(pTemp, pSrc); break;
+ case 4: Row<4>::idct(pTemp, pSrc); break;
+ case 5: Row<5>::idct(pTemp, pSrc); break;
+ case 6: Row<6>::idct(pTemp, pSrc); break;
+ case 7: Row<7>::idct(pTemp, pSrc); break;
+ case 8: Row<8>::idct(pTemp, pSrc); break;
+ }
+
+ pSrc += 8;
+ pTemp += 8;
+ }
+
+ pTemp = temp;
+
+ const int nonzero_rows = s_idct_col_table[block_max_zag - 1];
+ for (i = 8; i > 0; i--)
+ {
+ switch (nonzero_rows)
+ {
+ case 1: Col<1>::idct(pDst_ptr, pTemp); break;
+ case 2: Col<2>::idct(pDst_ptr, pTemp); break;
+ case 3: Col<3>::idct(pDst_ptr, pTemp); break;
+ case 4: Col<4>::idct(pDst_ptr, pTemp); break;
+ case 5: Col<5>::idct(pDst_ptr, pTemp); break;
+ case 6: Col<6>::idct(pDst_ptr, pTemp); break;
+ case 7: Col<7>::idct(pDst_ptr, pTemp); break;
+ case 8: Col<8>::idct(pDst_ptr, pTemp); break;
+ }
+
+ pTemp++;
+ pDst_ptr++;
+ }
+ }
+
+ void idct_4x4(const jpgd_block_t* pSrc_ptr, uint8* pDst_ptr)
+ {
+ int temp[64];
+ int* pTemp = temp;
+ const jpgd_block_t* pSrc = pSrc_ptr;
+
+ for (int i = 4; i > 0; i--)
+ {
+ Row<4>::idct(pTemp, pSrc);
+ pSrc += 8;
+ pTemp += 8;
+ }
+
+ pTemp = temp;
+ for (int i = 8; i > 0; i--)
+ {
+ Col<4>::idct(pDst_ptr, pTemp);
+ pTemp++;
+ pDst_ptr++;
+ }
+ }
+
+ // Retrieve one character from the input stream.
+ inline uint jpeg_decoder::get_char()
+ {
+ // Any bytes remaining in buffer?
+ if (!m_in_buf_left)
+ {
+ // Try to get more bytes.
+ prep_in_buffer();
+ // Still nothing to get?
+ if (!m_in_buf_left)
+ {
+ // Pad the end of the stream with 0xFF 0xD9 (EOI marker)
+ int t = m_tem_flag;
+ m_tem_flag ^= 1;
+ if (t)
+ return 0xD9;
+ else
+ return 0xFF;
+ }
+ }
+
+ uint c = *m_pIn_buf_ofs++;
+ m_in_buf_left--;
+
+ return c;
+ }
+
+ // Same as previous method, except can indicate if the character is a pad character or not.
+ inline uint jpeg_decoder::get_char(bool *pPadding_flag)
+ {
+ if (!m_in_buf_left)
+ {
+ prep_in_buffer();
+ if (!m_in_buf_left)
+ {
+ *pPadding_flag = true;
+ int t = m_tem_flag;
+ m_tem_flag ^= 1;
+ if (t)
+ return 0xD9;
+ else
+ return 0xFF;
+ }
+ }
+
+ *pPadding_flag = false;
+
+ uint c = *m_pIn_buf_ofs++;
+ m_in_buf_left--;
+
+ return c;
+ }
+
+ // Inserts a previously retrieved character back into the input buffer.
+ inline void jpeg_decoder::stuff_char(uint8 q)
+ {
+ *(--m_pIn_buf_ofs) = q;
+ m_in_buf_left++;
+ }
+
+ // Retrieves one character from the input stream, but does not read past markers. Will continue to return 0xFF when a marker is encountered.
+ inline uint8 jpeg_decoder::get_octet()
+ {
+ bool padding_flag;
+ int c = get_char(&padding_flag);
+
+ if (c == 0xFF)
+ {
+ if (padding_flag)
+ return 0xFF;
+
+ c = get_char(&padding_flag);
+ if (padding_flag)
+ {
+ stuff_char(0xFF);
+ return 0xFF;
+ }
+
+ if (c == 0x00)
+ return 0xFF;
+ else
+ {
+ stuff_char(static_cast(c));
+ stuff_char(0xFF);
+ return 0xFF;
+ }
+ }
+
+ return static_cast(c);
+ }
+
+ // Retrieves a variable number of bits from the input stream. Does not recognize markers.
+ inline uint jpeg_decoder::get_bits(int num_bits)
+ {
+ if (!num_bits)
+ return 0;
+
+ uint i = m_bit_buf >> (32 - num_bits);
+
+ if ((m_bits_left -= num_bits) <= 0)
+ {
+ m_bit_buf <<= (num_bits += m_bits_left);
+
+ uint c1 = get_char();
+ uint c2 = get_char();
+ m_bit_buf = (m_bit_buf & 0xFFFF0000) | (c1 << 8) | c2;
+
+ m_bit_buf <<= -m_bits_left;
+
+ m_bits_left += 16;
+
+ JPGD_ASSERT(m_bits_left >= 0);
+ }
+ else
+ m_bit_buf <<= num_bits;
+
+ return i;
+ }
+
+ // Retrieves a variable number of bits from the input stream. Markers will not be read into the input bit buffer. Instead, an infinite number of all 1's will be returned when a marker is encountered.
+ inline uint jpeg_decoder::get_bits_no_markers(int num_bits)
+ {
+ if (!num_bits)
+ return 0;
+
+ uint i = m_bit_buf >> (32 - num_bits);
+
+ if ((m_bits_left -= num_bits) <= 0)
+ {
+ m_bit_buf <<= (num_bits += m_bits_left);
+
+ if ((m_in_buf_left < 2) || (m_pIn_buf_ofs[0] == 0xFF) || (m_pIn_buf_ofs[1] == 0xFF))
+ {
+ uint c1 = get_octet();
+ uint c2 = get_octet();
+ m_bit_buf |= (c1 << 8) | c2;
+ }
+ else
+ {
+ m_bit_buf |= ((uint)m_pIn_buf_ofs[0] << 8) | m_pIn_buf_ofs[1];
+ m_in_buf_left -= 2;
+ m_pIn_buf_ofs += 2;
+ }
+
+ m_bit_buf <<= -m_bits_left;
+
+ m_bits_left += 16;
+
+ JPGD_ASSERT(m_bits_left >= 0);
+ }
+ else
+ m_bit_buf <<= num_bits;
+
+ return i;
+ }
+
+ // Decodes a Huffman encoded symbol.
+ inline int jpeg_decoder::huff_decode(huff_tables *pH)
+ {
+ int symbol;
+
+ // Check first 8-bits: do we have a complete symbol?
+ if ((symbol = pH->look_up[m_bit_buf >> 24]) < 0)
+ {
+ // Decode more bits, use a tree traversal to find symbol.
+ int ofs = 23;
+ do
+ {
+ symbol = pH->tree[-(int)(symbol + ((m_bit_buf >> ofs) & 1))];
+ ofs--;
+ } while (symbol < 0);
+
+ get_bits_no_markers(8 + (23 - ofs));
+ }
+ else
+ get_bits_no_markers(pH->code_size[symbol]);
+
+ return symbol;
+ }
+
+ // Decodes a Huffman encoded symbol.
+ inline int jpeg_decoder::huff_decode(huff_tables *pH, int& extra_bits)
+ {
+ int symbol;
+
+ // Check first 8-bits: do we have a complete symbol?
+ if ((symbol = pH->look_up2[m_bit_buf >> 24]) < 0)
+ {
+ // Use a tree traversal to find symbol.
+ int ofs = 23;
+ do
+ {
+ symbol = pH->tree[-(int)(symbol + ((m_bit_buf >> ofs) & 1))];
+ ofs--;
+ } while (symbol < 0);
+
+ get_bits_no_markers(8 + (23 - ofs));
+
+ extra_bits = get_bits_no_markers(symbol & 0xF);
+ }
+ else
+ {
+ JPGD_ASSERT(((symbol >> 8) & 31) == pH->code_size[symbol & 255] + ((symbol & 0x8000) ? (symbol & 15) : 0));
+
+ if (symbol & 0x8000)
+ {
+ get_bits_no_markers((symbol >> 8) & 31);
+ extra_bits = symbol >> 16;
+ }
+ else
+ {
+ int code_size = (symbol >> 8) & 31;
+ int num_extra_bits = symbol & 0xF;
+ int bits = code_size + num_extra_bits;
+ if (bits <= (m_bits_left + 16))
+ extra_bits = get_bits_no_markers(bits) & ((1 << num_extra_bits) - 1);
+ else
+ {
+ get_bits_no_markers(code_size);
+ extra_bits = get_bits_no_markers(num_extra_bits);
+ }
+ }
+
+ symbol &= 0xFF;
+ }
+
+ return symbol;
+ }
+
+ // Tables and macro used to fully decode the DPCM differences.
+ static const int s_extend_test[16] = { 0, 0x0001, 0x0002, 0x0004, 0x0008, 0x0010, 0x0020, 0x0040, 0x0080, 0x0100, 0x0200, 0x0400, 0x0800, 0x1000, 0x2000, 0x4000 };
+ static const int s_extend_offset[16] = { 0, -1, -3, -7, -15, -31, -63, -127, -255, -511, -1023, -2047, -4095, -8191, -16383, -32767 };
+ static const int s_extend_mask[] = { 0, (1<<0), (1<<1), (1<<2), (1<<3), (1<<4), (1<<5), (1<<6), (1<<7), (1<<8), (1<<9), (1<<10), (1<<11), (1<<12), (1<<13), (1<<14), (1<<15), (1<<16) };
+#define HUFF_EXTEND(x,s) ((x) < s_extend_test[s] ? (x) + s_extend_offset[s] : (x))
+
+ // Clamps a value between 0-255.
+ inline uint8 jpeg_decoder::clamp(int i)
+ {
+ if (static_cast(i) > 255)
+ i = (((~i) >> 31) & 0xFF);
+
+ return static_cast(i);
+ }
+
+ namespace DCT_Upsample
+ {
+ struct Matrix44
+ {
+ typedef int Element_Type;
+ enum { NUM_ROWS = 4, NUM_COLS = 4 };
+
+ Element_Type v[NUM_ROWS][NUM_COLS];
+
+ inline int rows() const { return NUM_ROWS; }
+ inline int cols() const { return NUM_COLS; }
+
+ inline const Element_Type & at(int r, int c) const { return v[r][c]; }
+ inline Element_Type & at(int r, int c) { return v[r][c]; }
+
+ inline Matrix44() { }
+
+ inline Matrix44& operator += (const Matrix44& a)
+ {
+ for (int r = 0; r < NUM_ROWS; r++)
+ {
+ at(r, 0) += a.at(r, 0);
+ at(r, 1) += a.at(r, 1);
+ at(r, 2) += a.at(r, 2);
+ at(r, 3) += a.at(r, 3);
+ }
+ return *this;
+ }
+
+ inline Matrix44& operator -= (const Matrix44& a)
+ {
+ for (int r = 0; r < NUM_ROWS; r++)
+ {
+ at(r, 0) -= a.at(r, 0);
+ at(r, 1) -= a.at(r, 1);
+ at(r, 2) -= a.at(r, 2);
+ at(r, 3) -= a.at(r, 3);
+ }
+ return *this;
+ }
+
+ friend inline Matrix44 operator + (const Matrix44& a, const Matrix44& b)
+ {
+ Matrix44 ret;
+ for (int r = 0; r < NUM_ROWS; r++)
+ {
+ ret.at(r, 0) = a.at(r, 0) + b.at(r, 0);
+ ret.at(r, 1) = a.at(r, 1) + b.at(r, 1);
+ ret.at(r, 2) = a.at(r, 2) + b.at(r, 2);
+ ret.at(r, 3) = a.at(r, 3) + b.at(r, 3);
+ }
+ return ret;
+ }
+
+ friend inline Matrix44 operator - (const Matrix44& a, const Matrix44& b)
+ {
+ Matrix44 ret;
+ for (int r = 0; r < NUM_ROWS; r++)
+ {
+ ret.at(r, 0) = a.at(r, 0) - b.at(r, 0);
+ ret.at(r, 1) = a.at(r, 1) - b.at(r, 1);
+ ret.at(r, 2) = a.at(r, 2) - b.at(r, 2);
+ ret.at(r, 3) = a.at(r, 3) - b.at(r, 3);
+ }
+ return ret;
+ }
+
+ static inline void add_and_store(jpgd_block_t* pDst, const Matrix44& a, const Matrix44& b)
+ {
+ for (int r = 0; r < 4; r++)
+ {
+ pDst[0*8 + r] = static_cast(a.at(r, 0) + b.at(r, 0));
+ pDst[1*8 + r] = static_cast(a.at(r, 1) + b.at(r, 1));
+ pDst[2*8 + r] = static_cast(a.at(r, 2) + b.at(r, 2));
+ pDst[3*8 + r] = static_cast(a.at(r, 3) + b.at(r, 3));
+ }
+ }
+
+ static inline void sub_and_store(jpgd_block_t* pDst, const Matrix44& a, const Matrix44& b)
+ {
+ for (int r = 0; r < 4; r++)
+ {
+ pDst[0*8 + r] = static_cast(a.at(r, 0) - b.at(r, 0));
+ pDst[1*8 + r] = static_cast(a.at(r, 1) - b.at(r, 1));
+ pDst[2*8 + r] = static_cast(a.at(r, 2) - b.at(r, 2));
+ pDst[3*8 + r] = static_cast(a.at(r, 3) - b.at(r, 3));
+ }
+ }
+ };
+
+ const int FRACT_BITS = 10;
+ const int SCALE = 1 << FRACT_BITS;
+
+ typedef int Temp_Type;
+#define D(i) (((i) + (SCALE >> 1)) >> FRACT_BITS)
+#define F(i) ((int)((i) * SCALE + .5f))
+
+ // Any decent C++ compiler will optimize this at compile time to a 0, or an array access.
+#define AT(c, r) ((((c)>=NUM_COLS)||((r)>=NUM_ROWS)) ? 0 : pSrc[(c)+(r)*8])
+
+ // NUM_ROWS/NUM_COLS = # of non-zero rows/cols in input matrix
+ template
+ struct P_Q
+ {
+ static void calc(Matrix44& P, Matrix44& Q, const jpgd_block_t* pSrc)
+ {
+ // 4x8 = 4x8 times 8x8, matrix 0 is constant
+ const Temp_Type X000 = AT(0, 0);
+ const Temp_Type X001 = AT(0, 1);
+ const Temp_Type X002 = AT(0, 2);
+ const Temp_Type X003 = AT(0, 3);
+ const Temp_Type X004 = AT(0, 4);
+ const Temp_Type X005 = AT(0, 5);
+ const Temp_Type X006 = AT(0, 6);
+ const Temp_Type X007 = AT(0, 7);
+ const Temp_Type X010 = D(F(0.415735f) * AT(1, 0) + F(0.791065f) * AT(3, 0) + F(-0.352443f) * AT(5, 0) + F(0.277785f) * AT(7, 0));
+ const Temp_Type X011 = D(F(0.415735f) * AT(1, 1) + F(0.791065f) * AT(3, 1) + F(-0.352443f) * AT(5, 1) + F(0.277785f) * AT(7, 1));
+ const Temp_Type X012 = D(F(0.415735f) * AT(1, 2) + F(0.791065f) * AT(3, 2) + F(-0.352443f) * AT(5, 2) + F(0.277785f) * AT(7, 2));
+ const Temp_Type X013 = D(F(0.415735f) * AT(1, 3) + F(0.791065f) * AT(3, 3) + F(-0.352443f) * AT(5, 3) + F(0.277785f) * AT(7, 3));
+ const Temp_Type X014 = D(F(0.415735f) * AT(1, 4) + F(0.791065f) * AT(3, 4) + F(-0.352443f) * AT(5, 4) + F(0.277785f) * AT(7, 4));
+ const Temp_Type X015 = D(F(0.415735f) * AT(1, 5) + F(0.791065f) * AT(3, 5) + F(-0.352443f) * AT(5, 5) + F(0.277785f) * AT(7, 5));
+ const Temp_Type X016 = D(F(0.415735f) * AT(1, 6) + F(0.791065f) * AT(3, 6) + F(-0.352443f) * AT(5, 6) + F(0.277785f) * AT(7, 6));
+ const Temp_Type X017 = D(F(0.415735f) * AT(1, 7) + F(0.791065f) * AT(3, 7) + F(-0.352443f) * AT(5, 7) + F(0.277785f) * AT(7, 7));
+ const Temp_Type X020 = AT(4, 0);
+ const Temp_Type X021 = AT(4, 1);
+ const Temp_Type X022 = AT(4, 2);
+ const Temp_Type X023 = AT(4, 3);
+ const Temp_Type X024 = AT(4, 4);
+ const Temp_Type X025 = AT(4, 5);
+ const Temp_Type X026 = AT(4, 6);
+ const Temp_Type X027 = AT(4, 7);
+ const Temp_Type X030 = D(F(0.022887f) * AT(1, 0) + F(-0.097545f) * AT(3, 0) + F(0.490393f) * AT(5, 0) + F(0.865723f) * AT(7, 0));
+ const Temp_Type X031 = D(F(0.022887f) * AT(1, 1) + F(-0.097545f) * AT(3, 1) + F(0.490393f) * AT(5, 1) + F(0.865723f) * AT(7, 1));
+ const Temp_Type X032 = D(F(0.022887f) * AT(1, 2) + F(-0.097545f) * AT(3, 2) + F(0.490393f) * AT(5, 2) + F(0.865723f) * AT(7, 2));
+ const Temp_Type X033 = D(F(0.022887f) * AT(1, 3) + F(-0.097545f) * AT(3, 3) + F(0.490393f) * AT(5, 3) + F(0.865723f) * AT(7, 3));
+ const Temp_Type X034 = D(F(0.022887f) * AT(1, 4) + F(-0.097545f) * AT(3, 4) + F(0.490393f) * AT(5, 4) + F(0.865723f) * AT(7, 4));
+ const Temp_Type X035 = D(F(0.022887f) * AT(1, 5) + F(-0.097545f) * AT(3, 5) + F(0.490393f) * AT(5, 5) + F(0.865723f) * AT(7, 5));
+ const Temp_Type X036 = D(F(0.022887f) * AT(1, 6) + F(-0.097545f) * AT(3, 6) + F(0.490393f) * AT(5, 6) + F(0.865723f) * AT(7, 6));
+ const Temp_Type X037 = D(F(0.022887f) * AT(1, 7) + F(-0.097545f) * AT(3, 7) + F(0.490393f) * AT(5, 7) + F(0.865723f) * AT(7, 7));
+
+ // 4x4 = 4x8 times 8x4, matrix 1 is constant
+ P.at(0, 0) = X000;
+ P.at(0, 1) = D(X001 * F(0.415735f) + X003 * F(0.791065f) + X005 * F(-0.352443f) + X007 * F(0.277785f));
+ P.at(0, 2) = X004;
+ P.at(0, 3) = D(X001 * F(0.022887f) + X003 * F(-0.097545f) + X005 * F(0.490393f) + X007 * F(0.865723f));
+ P.at(1, 0) = X010;
+ P.at(1, 1) = D(X011 * F(0.415735f) + X013 * F(0.791065f) + X015 * F(-0.352443f) + X017 * F(0.277785f));
+ P.at(1, 2) = X014;
+ P.at(1, 3) = D(X011 * F(0.022887f) + X013 * F(-0.097545f) + X015 * F(0.490393f) + X017 * F(0.865723f));
+ P.at(2, 0) = X020;
+ P.at(2, 1) = D(X021 * F(0.415735f) + X023 * F(0.791065f) + X025 * F(-0.352443f) + X027 * F(0.277785f));
+ P.at(2, 2) = X024;
+ P.at(2, 3) = D(X021 * F(0.022887f) + X023 * F(-0.097545f) + X025 * F(0.490393f) + X027 * F(0.865723f));
+ P.at(3, 0) = X030;
+ P.at(3, 1) = D(X031 * F(0.415735f) + X033 * F(0.791065f) + X035 * F(-0.352443f) + X037 * F(0.277785f));
+ P.at(3, 2) = X034;
+ P.at(3, 3) = D(X031 * F(0.022887f) + X033 * F(-0.097545f) + X035 * F(0.490393f) + X037 * F(0.865723f));
+ // 40 muls 24 adds
+
+ // 4x4 = 4x8 times 8x4, matrix 1 is constant
+ Q.at(0, 0) = D(X001 * F(0.906127f) + X003 * F(-0.318190f) + X005 * F(0.212608f) + X007 * F(-0.180240f));
+ Q.at(0, 1) = X002;
+ Q.at(0, 2) = D(X001 * F(-0.074658f) + X003 * F(0.513280f) + X005 * F(0.768178f) + X007 * F(-0.375330f));
+ Q.at(0, 3) = X006;
+ Q.at(1, 0) = D(X011 * F(0.906127f) + X013 * F(-0.318190f) + X015 * F(0.212608f) + X017 * F(-0.180240f));
+ Q.at(1, 1) = X012;
+ Q.at(1, 2) = D(X011 * F(-0.074658f) + X013 * F(0.513280f) + X015 * F(0.768178f) + X017 * F(-0.375330f));
+ Q.at(1, 3) = X016;
+ Q.at(2, 0) = D(X021 * F(0.906127f) + X023 * F(-0.318190f) + X025 * F(0.212608f) + X027 * F(-0.180240f));
+ Q.at(2, 1) = X022;
+ Q.at(2, 2) = D(X021 * F(-0.074658f) + X023 * F(0.513280f) + X025 * F(0.768178f) + X027 * F(-0.375330f));
+ Q.at(2, 3) = X026;
+ Q.at(3, 0) = D(X031 * F(0.906127f) + X033 * F(-0.318190f) + X035 * F(0.212608f) + X037 * F(-0.180240f));
+ Q.at(3, 1) = X032;
+ Q.at(3, 2) = D(X031 * F(-0.074658f) + X033 * F(0.513280f) + X035 * F(0.768178f) + X037 * F(-0.375330f));
+ Q.at(3, 3) = X036;
+ // 40 muls 24 adds
+ }
+ };
+
+ template
+ struct R_S
+ {
+ static void calc(Matrix44& R, Matrix44& S, const jpgd_block_t* pSrc)
+ {
+ // 4x8 = 4x8 times 8x8, matrix 0 is constant
+ const Temp_Type X100 = D(F(0.906127f) * AT(1, 0) + F(-0.318190f) * AT(3, 0) + F(0.212608f) * AT(5, 0) + F(-0.180240f) * AT(7, 0));
+ const Temp_Type X101 = D(F(0.906127f) * AT(1, 1) + F(-0.318190f) * AT(3, 1) + F(0.212608f) * AT(5, 1) + F(-0.180240f) * AT(7, 1));
+ const Temp_Type X102 = D(F(0.906127f) * AT(1, 2) + F(-0.318190f) * AT(3, 2) + F(0.212608f) * AT(5, 2) + F(-0.180240f) * AT(7, 2));
+ const Temp_Type X103 = D(F(0.906127f) * AT(1, 3) + F(-0.318190f) * AT(3, 3) + F(0.212608f) * AT(5, 3) + F(-0.180240f) * AT(7, 3));
+ const Temp_Type X104 = D(F(0.906127f) * AT(1, 4) + F(-0.318190f) * AT(3, 4) + F(0.212608f) * AT(5, 4) + F(-0.180240f) * AT(7, 4));
+ const Temp_Type X105 = D(F(0.906127f) * AT(1, 5) + F(-0.318190f) * AT(3, 5) + F(0.212608f) * AT(5, 5) + F(-0.180240f) * AT(7, 5));
+ const Temp_Type X106 = D(F(0.906127f) * AT(1, 6) + F(-0.318190f) * AT(3, 6) + F(0.212608f) * AT(5, 6) + F(-0.180240f) * AT(7, 6));
+ const Temp_Type X107 = D(F(0.906127f) * AT(1, 7) + F(-0.318190f) * AT(3, 7) + F(0.212608f) * AT(5, 7) + F(-0.180240f) * AT(7, 7));
+ const Temp_Type X110 = AT(2, 0);
+ const Temp_Type X111 = AT(2, 1);
+ const Temp_Type X112 = AT(2, 2);
+ const Temp_Type X113 = AT(2, 3);
+ const Temp_Type X114 = AT(2, 4);
+ const Temp_Type X115 = AT(2, 5);
+ const Temp_Type X116 = AT(2, 6);
+ const Temp_Type X117 = AT(2, 7);
+ const Temp_Type X120 = D(F(-0.074658f) * AT(1, 0) + F(0.513280f) * AT(3, 0) + F(0.768178f) * AT(5, 0) + F(-0.375330f) * AT(7, 0));
+ const Temp_Type X121 = D(F(-0.074658f) * AT(1, 1) + F(0.513280f) * AT(3, 1) + F(0.768178f) * AT(5, 1) + F(-0.375330f) * AT(7, 1));
+ const Temp_Type X122 = D(F(-0.074658f) * AT(1, 2) + F(0.513280f) * AT(3, 2) + F(0.768178f) * AT(5, 2) + F(-0.375330f) * AT(7, 2));
+ const Temp_Type X123 = D(F(-0.074658f) * AT(1, 3) + F(0.513280f) * AT(3, 3) + F(0.768178f) * AT(5, 3) + F(-0.375330f) * AT(7, 3));
+ const Temp_Type X124 = D(F(-0.074658f) * AT(1, 4) + F(0.513280f) * AT(3, 4) + F(0.768178f) * AT(5, 4) + F(-0.375330f) * AT(7, 4));
+ const Temp_Type X125 = D(F(-0.074658f) * AT(1, 5) + F(0.513280f) * AT(3, 5) + F(0.768178f) * AT(5, 5) + F(-0.375330f) * AT(7, 5));
+ const Temp_Type X126 = D(F(-0.074658f) * AT(1, 6) + F(0.513280f) * AT(3, 6) + F(0.768178f) * AT(5, 6) + F(-0.375330f) * AT(7, 6));
+ const Temp_Type X127 = D(F(-0.074658f) * AT(1, 7) + F(0.513280f) * AT(3, 7) + F(0.768178f) * AT(5, 7) + F(-0.375330f) * AT(7, 7));
+ const Temp_Type X130 = AT(6, 0);
+ const Temp_Type X131 = AT(6, 1);
+ const Temp_Type X132 = AT(6, 2);
+ const Temp_Type X133 = AT(6, 3);
+ const Temp_Type X134 = AT(6, 4);
+ const Temp_Type X135 = AT(6, 5);
+ const Temp_Type X136 = AT(6, 6);
+ const Temp_Type X137 = AT(6, 7);
+ // 80 muls 48 adds
+
+ // 4x4 = 4x8 times 8x4, matrix 1 is constant
+ R.at(0, 0) = X100;
+ R.at(0, 1) = D(X101 * F(0.415735f) + X103 * F(0.791065f) + X105 * F(-0.352443f) + X107 * F(0.277785f));
+ R.at(0, 2) = X104;
+ R.at(0, 3) = D(X101 * F(0.022887f) + X103 * F(-0.097545f) + X105 * F(0.490393f) + X107 * F(0.865723f));
+ R.at(1, 0) = X110;
+ R.at(1, 1) = D(X111 * F(0.415735f) + X113 * F(0.791065f) + X115 * F(-0.352443f) + X117 * F(0.277785f));
+ R.at(1, 2) = X114;
+ R.at(1, 3) = D(X111 * F(0.022887f) + X113 * F(-0.097545f) + X115 * F(0.490393f) + X117 * F(0.865723f));
+ R.at(2, 0) = X120;
+ R.at(2, 1) = D(X121 * F(0.415735f) + X123 * F(0.791065f) + X125 * F(-0.352443f) + X127 * F(0.277785f));
+ R.at(2, 2) = X124;
+ R.at(2, 3) = D(X121 * F(0.022887f) + X123 * F(-0.097545f) + X125 * F(0.490393f) + X127 * F(0.865723f));
+ R.at(3, 0) = X130;
+ R.at(3, 1) = D(X131 * F(0.415735f) + X133 * F(0.791065f) + X135 * F(-0.352443f) + X137 * F(0.277785f));
+ R.at(3, 2) = X134;
+ R.at(3, 3) = D(X131 * F(0.022887f) + X133 * F(-0.097545f) + X135 * F(0.490393f) + X137 * F(0.865723f));
+ // 40 muls 24 adds
+ // 4x4 = 4x8 times 8x4, matrix 1 is constant
+ S.at(0, 0) = D(X101 * F(0.906127f) + X103 * F(-0.318190f) + X105 * F(0.212608f) + X107 * F(-0.180240f));
+ S.at(0, 1) = X102;
+ S.at(0, 2) = D(X101 * F(-0.074658f) + X103 * F(0.513280f) + X105 * F(0.768178f) + X107 * F(-0.375330f));
+ S.at(0, 3) = X106;
+ S.at(1, 0) = D(X111 * F(0.906127f) + X113 * F(-0.318190f) + X115 * F(0.212608f) + X117 * F(-0.180240f));
+ S.at(1, 1) = X112;
+ S.at(1, 2) = D(X111 * F(-0.074658f) + X113 * F(0.513280f) + X115 * F(0.768178f) + X117 * F(-0.375330f));
+ S.at(1, 3) = X116;
+ S.at(2, 0) = D(X121 * F(0.906127f) + X123 * F(-0.318190f) + X125 * F(0.212608f) + X127 * F(-0.180240f));
+ S.at(2, 1) = X122;
+ S.at(2, 2) = D(X121 * F(-0.074658f) + X123 * F(0.513280f) + X125 * F(0.768178f) + X127 * F(-0.375330f));
+ S.at(2, 3) = X126;
+ S.at(3, 0) = D(X131 * F(0.906127f) + X133 * F(-0.318190f) + X135 * F(0.212608f) + X137 * F(-0.180240f));
+ S.at(3, 1) = X132;
+ S.at(3, 2) = D(X131 * F(-0.074658f) + X133 * F(0.513280f) + X135 * F(0.768178f) + X137 * F(-0.375330f));
+ S.at(3, 3) = X136;
+ // 40 muls 24 adds
+ }
+ };
+ } // end namespace DCT_Upsample
+
+ // Unconditionally frees all allocated m_blocks.
+ void jpeg_decoder::free_all_blocks()
+ {
+ m_pStream = NULL;
+ for (mem_block *b = m_pMem_blocks; b; )
+ {
+ mem_block *n = b->m_pNext;
+ jpgd_free(b);
+ b = n;
+ }
+ m_pMem_blocks = NULL;
+ }
+
+ // This method handles all errors.
+ // It could easily be changed to use C++ exceptions.
+ void jpeg_decoder::stop_decoding(jpgd_status status)
+ {
+ m_error_code = status;
+ free_all_blocks();
+ longjmp(m_jmp_state, status);
+
+ // we shouldn't get here as longjmp shouldn't return, but we put it here to make it explicit
+ // that this function doesn't return, otherwise we get this error:
+ //
+ // error : function declared 'noreturn' should not return
+ exit(1);
+ }
+
+ void *jpeg_decoder::alloc(size_t nSize, bool zero)
+ {
+ nSize = (JPGD_MAX(nSize, 1) + 3) & ~3;
+ char *rv = NULL;
+ for (mem_block *b = m_pMem_blocks; b; b = b->m_pNext)
+ {
+ if ((b->m_used_count + nSize) <= b->m_size)
+ {
+ rv = b->m_data + b->m_used_count;
+ b->m_used_count += nSize;
+ break;
+ }
+ }
+ if (!rv)
+ {
+ int capacity = JPGD_MAX(32768 - 256, (nSize + 2047) & ~2047);
+ mem_block *b = (mem_block*)jpgd_malloc(sizeof(mem_block) + capacity);
+ if (!b) stop_decoding(JPGD_NOTENOUGHMEM);
+ b->m_pNext = m_pMem_blocks; m_pMem_blocks = b;
+ b->m_used_count = nSize;
+ b->m_size = capacity;
+ rv = b->m_data;
+ }
+ if (zero) memset(rv, 0, nSize);
+ return rv;
+ }
+
+ void jpeg_decoder::word_clear(void *p, uint16 c, uint n)
+ {
+ uint8 *pD = (uint8*)p;
+ const uint8 l = c & 0xFF, h = (c >> 8) & 0xFF;
+ while (n)
+ {
+ pD[0] = l; pD[1] = h; pD += 2;
+ n--;
+ }
+ }
+
+ // Refill the input buffer.
+ // This method will sit in a loop until (A) the buffer is full or (B)
+ // the stream's read() method reports and end of file condition.
+ void jpeg_decoder::prep_in_buffer()
+ {
+ m_in_buf_left = 0;
+ m_pIn_buf_ofs = m_in_buf;
+
+ if (m_eof_flag)
+ return;
+
+ do
+ {
+ int bytes_read = m_pStream->read(m_in_buf + m_in_buf_left, JPGD_IN_BUF_SIZE - m_in_buf_left, &m_eof_flag);
+ if (bytes_read == -1)
+ stop_decoding(JPGD_STREAM_READ);
+
+ m_in_buf_left += bytes_read;
+ } while ((m_in_buf_left < JPGD_IN_BUF_SIZE) && (!m_eof_flag));
+
+ m_total_bytes_read += m_in_buf_left;
+
+ // Pad the end of the block with M_EOI (prevents the decompressor from going off the rails if the stream is invalid).
+ // (This dates way back to when this decompressor was written in C/asm, and the all-asm Huffman decoder did some fancy things to increase perf.)
+ word_clear(m_pIn_buf_ofs + m_in_buf_left, 0xD9FF, 64);
+ }
+
+ // Read a Huffman code table.
+ void jpeg_decoder::read_dht_marker()
+ {
+ int i, index, count;
+ uint8 huff_num[17];
+ uint8 huff_val[256];
+
+ uint num_left = get_bits(16);
+
+ if (num_left < 2)
+ stop_decoding(JPGD_BAD_DHT_MARKER);
+
+ num_left -= 2;
+
+ while (num_left)
+ {
+ index = get_bits(8);
+
+ huff_num[0] = 0;
+
+ count = 0;
+
+ for (i = 1; i <= 16; i++)
+ {
+ huff_num[i] = static_cast(get_bits(8));
+ count += huff_num[i];
+ }
+
+ if (count > 255)
+ stop_decoding(JPGD_BAD_DHT_COUNTS);
+
+ for (i = 0; i < count; i++)
+ huff_val[i] = static_cast(get_bits(8));
+
+ i = 1 + 16 + count;
+
+ if (num_left < (uint)i)
+ stop_decoding(JPGD_BAD_DHT_MARKER);
+
+ num_left -= i;
+
+ if ((index & 0x10) > 0x10)
+ stop_decoding(JPGD_BAD_DHT_INDEX);
+
+ index = (index & 0x0F) + ((index & 0x10) >> 4) * (JPGD_MAX_HUFF_TABLES >> 1);
+
+ if (index >= JPGD_MAX_HUFF_TABLES)
+ stop_decoding(JPGD_BAD_DHT_INDEX);
+
+ if (!m_huff_num[index])
+ m_huff_num[index] = (uint8 *)alloc(17);
+
+ if (!m_huff_val[index])
+ m_huff_val[index] = (uint8 *)alloc(256);
+
+ m_huff_ac[index] = (index & 0x10) != 0;
+ memcpy(m_huff_num[index], huff_num, 17);
+ memcpy(m_huff_val[index], huff_val, 256);
+ }
+ }
+
+ // Read a quantization table.
+ void jpeg_decoder::read_dqt_marker()
+ {
+ int n, i, prec;
+ uint num_left;
+ uint temp;
+
+ num_left = get_bits(16);
+
+ if (num_left < 2)
+ stop_decoding(JPGD_BAD_DQT_MARKER);
+
+ num_left -= 2;
+
+ while (num_left)
+ {
+ n = get_bits(8);
+ prec = n >> 4;
+ n &= 0x0F;
+
+ if (n >= JPGD_MAX_QUANT_TABLES)
+ stop_decoding(JPGD_BAD_DQT_TABLE);
+
+ if (!m_quant[n])
+ m_quant[n] = (jpgd_quant_t *)alloc(64 * sizeof(jpgd_quant_t));
+
+ // read quantization entries, in zag order
+ for (i = 0; i < 64; i++)
+ {
+ temp = get_bits(8);
+
+ if (prec)
+ temp = (temp << 8) + get_bits(8);
+
+ m_quant[n][i] = static_cast(temp);
+ }
+
+ i = 64 + 1;
+
+ if (prec)
+ i += 64;
+
+ if (num_left < (uint)i)
+ stop_decoding(JPGD_BAD_DQT_LENGTH);
+
+ num_left -= i;
+ }
+ }
+
+ // Read the start of frame (SOF) marker.
+ void jpeg_decoder::read_sof_marker()
+ {
+ int i;
+ uint num_left;
+
+ num_left = get_bits(16);
+
+ if (get_bits(8) != 8) /* precision: sorry, only 8-bit precision is supported right now */
+ stop_decoding(JPGD_BAD_PRECISION);
+
+ m_image_y_size = get_bits(16);
+
+ if ((m_image_y_size < 1) || (m_image_y_size > JPGD_MAX_HEIGHT))
+ stop_decoding(JPGD_BAD_HEIGHT);
+
+ m_image_x_size = get_bits(16);
+
+ if ((m_image_x_size < 1) || (m_image_x_size > JPGD_MAX_WIDTH))
+ stop_decoding(JPGD_BAD_WIDTH);
+
+ m_comps_in_frame = get_bits(8);
+
+ if (m_comps_in_frame > JPGD_MAX_COMPONENTS)
+ stop_decoding(JPGD_TOO_MANY_COMPONENTS);
+
+ if (num_left != (uint)(m_comps_in_frame * 3 + 8))
+ stop_decoding(JPGD_BAD_SOF_LENGTH);
+
+ for (i = 0; i < m_comps_in_frame; i++)
+ {
+ m_comp_ident[i] = get_bits(8);
+ m_comp_h_samp[i] = get_bits(4);
+ m_comp_v_samp[i] = get_bits(4);
+ m_comp_quant[i] = get_bits(8);
+ }
+ }
+
+ // Used to skip unrecognized markers.
+ void jpeg_decoder::skip_variable_marker()
+ {
+ uint num_left;
+
+ num_left = get_bits(16);
+
+ if (num_left < 2)
+ stop_decoding(JPGD_BAD_VARIABLE_MARKER);
+
+ num_left -= 2;
+
+ while (num_left)
+ {
+ get_bits(8);
+ num_left--;
+ }
+ }
+
+ // Read a define restart interval (DRI) marker.
+ void jpeg_decoder::read_dri_marker()
+ {
+ if (get_bits(16) != 4)
+ stop_decoding(JPGD_BAD_DRI_LENGTH);
+
+ m_restart_interval = get_bits(16);
+ }
+
+ // Read a start of scan (SOS) marker.
+ void jpeg_decoder::read_sos_marker()
+ {
+ uint num_left;
+ int i, ci, n, c, cc;
+
+ num_left = get_bits(16);
+
+ n = get_bits(8);
+
+ m_comps_in_scan = n;
+
+ num_left -= 3;
+
+ if ( (num_left != (uint)(n * 2 + 3)) || (n < 1) || (n > JPGD_MAX_COMPS_IN_SCAN) )
+ stop_decoding(JPGD_BAD_SOS_LENGTH);
+
+ for (i = 0; i < n; i++)
+ {
+ cc = get_bits(8);
+ c = get_bits(8);
+ num_left -= 2;
+
+ for (ci = 0; ci < m_comps_in_frame; ci++)
+ if (cc == m_comp_ident[ci])
+ break;
+
+ if (ci >= m_comps_in_frame)
+ stop_decoding(JPGD_BAD_SOS_COMP_ID);
+
+ m_comp_list[i] = ci;
+ m_comp_dc_tab[ci] = (c >> 4) & 15;
+ m_comp_ac_tab[ci] = (c & 15) + (JPGD_MAX_HUFF_TABLES >> 1);
+ }
+
+ m_spectral_start = get_bits(8);
+ m_spectral_end = get_bits(8);
+ m_successive_high = get_bits(4);
+ m_successive_low = get_bits(4);
+
+ if (!m_progressive_flag)
+ {
+ m_spectral_start = 0;
+ m_spectral_end = 63;
+ }
+
+ num_left -= 3;
+
+ while (num_left) /* read past whatever is num_left */
+ {
+ get_bits(8);
+ num_left--;
+ }
+ }
+
+ // Finds the next marker.
+ int jpeg_decoder::next_marker()
+ {
+ uint c, bytes;
+
+ bytes = 0;
+
+ do
+ {
+ do
+ {
+ bytes++;
+ c = get_bits(8);
+ } while (c != 0xFF);
+
+ do
+ {
+ c = get_bits(8);
+ } while (c == 0xFF);
+
+ } while (c == 0);
+
+ // If bytes > 0 here, there where extra bytes before the marker (not good).
+
+ return c;
+ }
+
+ // Process markers. Returns when an SOFx, SOI, EOI, or SOS marker is
+ // encountered.
+ int jpeg_decoder::process_markers()
+ {
+ int c;
+
+ for ( ; ; )
+ {
+ c = next_marker();
+
+ switch (c)
+ {
+ case M_SOF0:
+ case M_SOF1:
+ case M_SOF2:
+ case M_SOF3:
+ case M_SOF5:
+ case M_SOF6:
+ case M_SOF7:
+ // case M_JPG:
+ case M_SOF9:
+ case M_SOF10:
+ case M_SOF11:
+ case M_SOF13:
+ case M_SOF14:
+ case M_SOF15:
+ case M_SOI:
+ case M_EOI:
+ case M_SOS:
+ {
+ return c;
+ }
+ case M_DHT:
+ {
+ read_dht_marker();
+ break;
+ }
+ // No arithmitic support - dumb patents!
+ case M_DAC:
+ {
+ stop_decoding(JPGD_NO_ARITHMITIC_SUPPORT);
+ break;
+ }
+ case M_DQT:
+ {
+ read_dqt_marker();
+ break;
+ }
+ case M_DRI:
+ {
+ read_dri_marker();
+ break;
+ }
+ //case M_APP0: /* no need to read the JFIF marker */
+
+ case M_JPG:
+ case M_RST0: /* no parameters */
+ case M_RST1:
+ case M_RST2:
+ case M_RST3:
+ case M_RST4:
+ case M_RST5:
+ case M_RST6:
+ case M_RST7:
+ case M_TEM:
+ {
+ stop_decoding(JPGD_UNEXPECTED_MARKER);
+ break;
+ }
+ default: /* must be DNL, DHP, EXP, APPn, JPGn, COM, or RESn or APP0 */
+ {
+ skip_variable_marker();
+ break;
+ }
+ }
+ }
+ }
+
+ // Finds the start of image (SOI) marker.
+ // This code is rather defensive: it only checks the first 512 bytes to avoid
+ // false positives.
+ void jpeg_decoder::locate_soi_marker()
+ {
+ uint lastchar, thischar;
+ uint bytesleft;
+
+ lastchar = get_bits(8);
+
+ thischar = get_bits(8);
+
+ /* ok if it's a normal JPEG file without a special header */
+
+ if ((lastchar == 0xFF) && (thischar == M_SOI))
+ return;
+
+ bytesleft = 4096; //512;
+
+ for ( ; ; )
+ {
+ if (--bytesleft == 0)
+ stop_decoding(JPGD_NOT_JPEG);
+
+ lastchar = thischar;
+
+ thischar = get_bits(8);
+
+ if (lastchar == 0xFF)
+ {
+ if (thischar == M_SOI)
+ break;
+ else if (thischar == M_EOI) // get_bits will keep returning M_EOI if we read past the end
+ stop_decoding(JPGD_NOT_JPEG);
+ }
+ }
+
+ // Check the next character after marker: if it's not 0xFF, it can't be the start of the next marker, so the file is bad.
+ thischar = (m_bit_buf >> 24) & 0xFF;
+
+ if (thischar != 0xFF)
+ stop_decoding(JPGD_NOT_JPEG);
+ }
+
+ // Find a start of frame (SOF) marker.
+ void jpeg_decoder::locate_sof_marker()
+ {
+ locate_soi_marker();
+
+ int c = process_markers();
+
+ switch (c)
+ {
+ case M_SOF2:
+ m_progressive_flag = JPGD_TRUE;
+ case M_SOF0: /* baseline DCT */
+ case M_SOF1: /* extended sequential DCT */
+ {
+ read_sof_marker();
+ break;
+ }
+ case M_SOF9: /* Arithmitic coding */
+ {
+ stop_decoding(JPGD_NO_ARITHMITIC_SUPPORT);
+ break;
+ }
+ default:
+ {
+ stop_decoding(JPGD_UNSUPPORTED_MARKER);
+ break;
+ }
+ }
+ }
+
+ // Find a start of scan (SOS) marker.
+ int jpeg_decoder::locate_sos_marker()
+ {
+ int c;
+
+ c = process_markers();
+
+ if (c == M_EOI)
+ return JPGD_FALSE;
+ else if (c != M_SOS)
+ stop_decoding(JPGD_UNEXPECTED_MARKER);
+
+ read_sos_marker();
+
+ return JPGD_TRUE;
+ }
+
+ // Reset everything to default/uninitialized state.
+ void jpeg_decoder::init(jpeg_decoder_stream *pStream)
+ {
+ m_pMem_blocks = NULL;
+ m_error_code = JPGD_SUCCESS;
+ m_ready_flag = false;
+ m_image_x_size = m_image_y_size = 0;
+ m_pStream = pStream;
+ m_progressive_flag = JPGD_FALSE;
+
+ memset(m_huff_ac, 0, sizeof(m_huff_ac));
+ memset(m_huff_num, 0, sizeof(m_huff_num));
+ memset(m_huff_val, 0, sizeof(m_huff_val));
+ memset(m_quant, 0, sizeof(m_quant));
+
+ m_scan_type = 0;
+ m_comps_in_frame = 0;
+
+ memset(m_comp_h_samp, 0, sizeof(m_comp_h_samp));
+ memset(m_comp_v_samp, 0, sizeof(m_comp_v_samp));
+ memset(m_comp_quant, 0, sizeof(m_comp_quant));
+ memset(m_comp_ident, 0, sizeof(m_comp_ident));
+ memset(m_comp_h_blocks, 0, sizeof(m_comp_h_blocks));
+ memset(m_comp_v_blocks, 0, sizeof(m_comp_v_blocks));
+
+ m_comps_in_scan = 0;
+ memset(m_comp_list, 0, sizeof(m_comp_list));
+ memset(m_comp_dc_tab, 0, sizeof(m_comp_dc_tab));
+ memset(m_comp_ac_tab, 0, sizeof(m_comp_ac_tab));
+
+ m_spectral_start = 0;
+ m_spectral_end = 0;
+ m_successive_low = 0;
+ m_successive_high = 0;
+ m_max_mcu_x_size = 0;
+ m_max_mcu_y_size = 0;
+ m_blocks_per_mcu = 0;
+ m_max_blocks_per_row = 0;
+ m_mcus_per_row = 0;
+ m_mcus_per_col = 0;
+ m_expanded_blocks_per_component = 0;
+ m_expanded_blocks_per_mcu = 0;
+ m_expanded_blocks_per_row = 0;
+ m_freq_domain_chroma_upsample = false;
+
+ memset(m_mcu_org, 0, sizeof(m_mcu_org));
+
+ m_total_lines_left = 0;
+ m_mcu_lines_left = 0;
+ m_real_dest_bytes_per_scan_line = 0;
+ m_dest_bytes_per_scan_line = 0;
+ m_dest_bytes_per_pixel = 0;
+
+ memset(m_pHuff_tabs, 0, sizeof(m_pHuff_tabs));
+
+ memset(m_dc_coeffs, 0, sizeof(m_dc_coeffs));
+ memset(m_ac_coeffs, 0, sizeof(m_ac_coeffs));
+ memset(m_block_y_mcu, 0, sizeof(m_block_y_mcu));
+
+ m_eob_run = 0;
+
+ memset(m_block_y_mcu, 0, sizeof(m_block_y_mcu));
+
+ m_pIn_buf_ofs = m_in_buf;
+ m_in_buf_left = 0;
+ m_eof_flag = false;
+ m_tem_flag = 0;
+
+ memset(m_in_buf_pad_start, 0, sizeof(m_in_buf_pad_start));
+ memset(m_in_buf, 0, sizeof(m_in_buf));
+ memset(m_in_buf_pad_end, 0, sizeof(m_in_buf_pad_end));
+
+ m_restart_interval = 0;
+ m_restarts_left = 0;
+ m_next_restart_num = 0;
+
+ m_max_mcus_per_row = 0;
+ m_max_blocks_per_mcu = 0;
+ m_max_mcus_per_col = 0;
+
+ memset(m_last_dc_val, 0, sizeof(m_last_dc_val));
+ m_pMCU_coefficients = NULL;
+ m_pSample_buf = NULL;
+
+ m_total_bytes_read = 0;
+
+ m_pScan_line_0 = NULL;
+ m_pScan_line_1 = NULL;
+
+ // Ready the input buffer.
+ prep_in_buffer();
+
+ // Prime the bit buffer.
+ m_bits_left = 16;
+ m_bit_buf = 0;
+
+ get_bits(16);
+ get_bits(16);
+
+ for (int i = 0; i < JPGD_MAX_BLOCKS_PER_MCU; i++)
+ m_mcu_block_max_zag[i] = 64;
+ }
+
+#define SCALEBITS 16
+#define ONE_HALF ((int) 1 << (SCALEBITS-1))
+#define FIX(x) ((int) ((x) * (1L<> SCALEBITS;
+ m_cbb[i] = ( FIX(1.77200f) * k + ONE_HALF) >> SCALEBITS;
+ m_crg[i] = (-FIX(0.71414f)) * k;
+ m_cbg[i] = (-FIX(0.34414f)) * k + ONE_HALF;
+ }
+ }
+
+ // This method throws back into the stream any bytes that where read
+ // into the bit buffer during initial marker scanning.
+ void jpeg_decoder::fix_in_buffer()
+ {
+ // In case any 0xFF's where pulled into the buffer during marker scanning.
+ JPGD_ASSERT((m_bits_left & 7) == 0);
+
+ if (m_bits_left == 16)
+ stuff_char( (uint8)(m_bit_buf & 0xFF));
+
+ if (m_bits_left >= 8)
+ stuff_char( (uint8)((m_bit_buf >> 8) & 0xFF));
+
+ stuff_char((uint8)((m_bit_buf >> 16) & 0xFF));
+ stuff_char((uint8)((m_bit_buf >> 24) & 0xFF));
+
+ m_bits_left = 16;
+ get_bits_no_markers(16);
+ get_bits_no_markers(16);
+ }
+
+ void jpeg_decoder::transform_mcu(int mcu_row)
+ {
+ jpgd_block_t* pSrc_ptr = m_pMCU_coefficients;
+ uint8* pDst_ptr = m_pSample_buf + mcu_row * m_blocks_per_mcu * 64;
+
+ for (int mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++)
+ {
+ idct(pSrc_ptr, pDst_ptr, m_mcu_block_max_zag[mcu_block]);
+ pSrc_ptr += 64;
+ pDst_ptr += 64;
+ }
+ }
+
+ static const uint8 s_max_rc[64] =
+ {
+ 17, 18, 34, 50, 50, 51, 52, 52, 52, 68, 84, 84, 84, 84, 85, 86, 86, 86, 86, 86,
+ 102, 118, 118, 118, 118, 118, 118, 119, 120, 120, 120, 120, 120, 120, 120, 136,
+ 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136,
+ 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136
+ };
+
+ void jpeg_decoder::transform_mcu_expand(int mcu_row)
+ {
+ jpgd_block_t* pSrc_ptr = m_pMCU_coefficients;
+ uint8* pDst_ptr = m_pSample_buf + mcu_row * m_expanded_blocks_per_mcu * 64;
+
+ // Y IDCT
+ int mcu_block;
+ for (mcu_block = 0; mcu_block < m_expanded_blocks_per_component; mcu_block++)
+ {
+ idct(pSrc_ptr, pDst_ptr, m_mcu_block_max_zag[mcu_block]);
+ pSrc_ptr += 64;
+ pDst_ptr += 64;
+ }
+
+ // Chroma IDCT, with upsampling
+ jpgd_block_t temp_block[64];
+
+ for (int i = 0; i < 2; i++)
+ {
+ DCT_Upsample::Matrix44 P, Q, R, S;
+
+ JPGD_ASSERT(m_mcu_block_max_zag[mcu_block] >= 1);
+ JPGD_ASSERT(m_mcu_block_max_zag[mcu_block] <= 64);
+
+ switch (s_max_rc[m_mcu_block_max_zag[mcu_block++] - 1])
+ {
+ case 1*16+1:
+ DCT_Upsample::P_Q<1, 1>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<1, 1>::calc(R, S, pSrc_ptr);
+ break;
+ case 1*16+2:
+ DCT_Upsample::P_Q<1, 2>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<1, 2>::calc(R, S, pSrc_ptr);
+ break;
+ case 2*16+2:
+ DCT_Upsample::P_Q<2, 2>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<2, 2>::calc(R, S, pSrc_ptr);
+ break;
+ case 3*16+2:
+ DCT_Upsample::P_Q<3, 2>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<3, 2>::calc(R, S, pSrc_ptr);
+ break;
+ case 3*16+3:
+ DCT_Upsample::P_Q<3, 3>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<3, 3>::calc(R, S, pSrc_ptr);
+ break;
+ case 3*16+4:
+ DCT_Upsample::P_Q<3, 4>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<3, 4>::calc(R, S, pSrc_ptr);
+ break;
+ case 4*16+4:
+ DCT_Upsample::P_Q<4, 4>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<4, 4>::calc(R, S, pSrc_ptr);
+ break;
+ case 5*16+4:
+ DCT_Upsample::P_Q<5, 4>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<5, 4>::calc(R, S, pSrc_ptr);
+ break;
+ case 5*16+5:
+ DCT_Upsample::P_Q<5, 5>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<5, 5>::calc(R, S, pSrc_ptr);
+ break;
+ case 5*16+6:
+ DCT_Upsample::P_Q<5, 6>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<5, 6>::calc(R, S, pSrc_ptr);
+ break;
+ case 6*16+6:
+ DCT_Upsample::P_Q<6, 6>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<6, 6>::calc(R, S, pSrc_ptr);
+ break;
+ case 7*16+6:
+ DCT_Upsample::P_Q<7, 6>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<7, 6>::calc(R, S, pSrc_ptr);
+ break;
+ case 7*16+7:
+ DCT_Upsample::P_Q<7, 7>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<7, 7>::calc(R, S, pSrc_ptr);
+ break;
+ case 7*16+8:
+ DCT_Upsample::P_Q<7, 8>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<7, 8>::calc(R, S, pSrc_ptr);
+ break;
+ case 8*16+8:
+ DCT_Upsample::P_Q<8, 8>::calc(P, Q, pSrc_ptr);
+ DCT_Upsample::R_S<8, 8>::calc(R, S, pSrc_ptr);
+ break;
+ default:
+ JPGD_ASSERT(false);
+ }
+
+ DCT_Upsample::Matrix44 a(P + Q); P -= Q;
+ DCT_Upsample::Matrix44& b = P;
+ DCT_Upsample::Matrix44 c(R + S); R -= S;
+ DCT_Upsample::Matrix44& d = R;
+
+ DCT_Upsample::Matrix44::add_and_store(temp_block, a, c);
+ idct_4x4(temp_block, pDst_ptr);
+ pDst_ptr += 64;
+
+ DCT_Upsample::Matrix44::sub_and_store(temp_block, a, c);
+ idct_4x4(temp_block, pDst_ptr);
+ pDst_ptr += 64;
+
+ DCT_Upsample::Matrix44::add_and_store(temp_block, b, d);
+ idct_4x4(temp_block, pDst_ptr);
+ pDst_ptr += 64;
+
+ DCT_Upsample::Matrix44::sub_and_store(temp_block, b, d);
+ idct_4x4(temp_block, pDst_ptr);
+ pDst_ptr += 64;
+
+ pSrc_ptr += 64;
+ }
+ }
+
+ // Loads and dequantizes the next row of (already decoded) coefficients.
+ // Progressive images only.
+ void jpeg_decoder::load_next_row()
+ {
+ int i;
+ jpgd_block_t *p;
+ jpgd_quant_t *q;
+ int mcu_row, mcu_block, row_block = 0;
+ int component_num, component_id;
+ int block_x_mcu[JPGD_MAX_COMPONENTS];
+
+ memset(block_x_mcu, 0, JPGD_MAX_COMPONENTS * sizeof(int));
+
+ for (mcu_row = 0; mcu_row < m_mcus_per_row; mcu_row++)
+ {
+ int block_x_mcu_ofs = 0, block_y_mcu_ofs = 0;
+
+ for (mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++)
+ {
+ component_id = m_mcu_org[mcu_block];
+ q = m_quant[m_comp_quant[component_id]];
+
+ p = m_pMCU_coefficients + 64 * mcu_block;
+
+ jpgd_block_t* pAC = coeff_buf_getp(m_ac_coeffs[component_id], block_x_mcu[component_id] + block_x_mcu_ofs, m_block_y_mcu[component_id] + block_y_mcu_ofs);
+ jpgd_block_t* pDC = coeff_buf_getp(m_dc_coeffs[component_id], block_x_mcu[component_id] + block_x_mcu_ofs, m_block_y_mcu[component_id] + block_y_mcu_ofs);
+ p[0] = pDC[0];
+ memcpy(&p[1], &pAC[1], 63 * sizeof(jpgd_block_t));
+
+ for (i = 63; i > 0; i--)
+ if (p[g_ZAG[i]])
+ break;
+
+ m_mcu_block_max_zag[mcu_block] = i + 1;
+
+ for ( ; i >= 0; i--)
+ if (p[g_ZAG[i]])
+ p[g_ZAG[i]] = static_cast(p[g_ZAG[i]] * q[i]);
+
+ row_block++;
+
+ if (m_comps_in_scan == 1)
+ block_x_mcu[component_id]++;
+ else
+ {
+ if (++block_x_mcu_ofs == m_comp_h_samp[component_id])
+ {
+ block_x_mcu_ofs = 0;
+
+ if (++block_y_mcu_ofs == m_comp_v_samp[component_id])
+ {
+ block_y_mcu_ofs = 0;
+
+ block_x_mcu[component_id] += m_comp_h_samp[component_id];
+ }
+ }
+ }
+ }
+
+ if (m_freq_domain_chroma_upsample)
+ transform_mcu_expand(mcu_row);
+ else
+ transform_mcu(mcu_row);
+ }
+
+ if (m_comps_in_scan == 1)
+ m_block_y_mcu[m_comp_list[0]]++;
+ else
+ {
+ for (component_num = 0; component_num < m_comps_in_scan; component_num++)
+ {
+ component_id = m_comp_list[component_num];
+
+ m_block_y_mcu[component_id] += m_comp_v_samp[component_id];
+ }
+ }
+ }
+
+ // Restart interval processing.
+ void jpeg_decoder::process_restart()
+ {
+ int i;
+ int c = 0;
+
+ // Align to a byte boundry
+ // FIXME: Is this really necessary? get_bits_no_markers() never reads in markers!
+ //get_bits_no_markers(m_bits_left & 7);
+
+ // Let's scan a little bit to find the marker, but not _too_ far.
+ // 1536 is a "fudge factor" that determines how much to scan.
+ for (i = 1536; i > 0; i--)
+ if (get_char() == 0xFF)
+ break;
+
+ if (i == 0)
+ stop_decoding(JPGD_BAD_RESTART_MARKER);
+
+ for ( ; i > 0; i--)
+ if ((c = get_char()) != 0xFF)
+ break;
+
+ if (i == 0)
+ stop_decoding(JPGD_BAD_RESTART_MARKER);
+
+ // Is it the expected marker? If not, something bad happened.
+ if (c != (m_next_restart_num + M_RST0))
+ stop_decoding(JPGD_BAD_RESTART_MARKER);
+
+ // Reset each component's DC prediction values.
+ memset(&m_last_dc_val, 0, m_comps_in_frame * sizeof(uint));
+
+ m_eob_run = 0;
+
+ m_restarts_left = m_restart_interval;
+
+ m_next_restart_num = (m_next_restart_num + 1) & 7;
+
+ // Get the bit buffer going again...
+
+ m_bits_left = 16;
+ get_bits_no_markers(16);
+ get_bits_no_markers(16);
+ }
+
+ static inline int dequantize_ac(int c, int q) { c *= q; return c; }
+
+ // Decodes and dequantizes the next row of coefficients.
+ void jpeg_decoder::decode_next_row()
+ {
+ int row_block = 0;
+
+ for (int mcu_row = 0; mcu_row < m_mcus_per_row; mcu_row++)
+ {
+ if ((m_restart_interval) && (m_restarts_left == 0))
+ process_restart();
+
+ jpgd_block_t* p = m_pMCU_coefficients;
+ for (int mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++, p += 64)
+ {
+ int component_id = m_mcu_org[mcu_block];
+ jpgd_quant_t* q = m_quant[m_comp_quant[component_id]];
+
+ int r, s;
+ s = huff_decode(m_pHuff_tabs[m_comp_dc_tab[component_id]], r);
+ s = HUFF_EXTEND(r, s);
+
+ m_last_dc_val[component_id] = (s += m_last_dc_val[component_id]);
+
+ p[0] = static_cast(s * q[0]);
+
+ int prev_num_set = m_mcu_block_max_zag[mcu_block];
+
+ huff_tables *pH = m_pHuff_tabs[m_comp_ac_tab[component_id]];
+
+ int k;
+ for (k = 1; k < 64; k++)
+ {
+ int extra_bits;
+ s = huff_decode(pH, extra_bits);
+
+ r = s >> 4;
+ s &= 15;
+
+ if (s)
+ {
+ if (r)
+ {
+ if ((k + r) > 63)
+ stop_decoding(JPGD_DECODE_ERROR);
+
+ if (k < prev_num_set)
+ {
+ int n = JPGD_MIN(r, prev_num_set - k);
+ int kt = k;
+ while (n--)
+ p[g_ZAG[kt++]] = 0;
+ }
+
+ k += r;
+ }
+
+ s = HUFF_EXTEND(extra_bits, s);
+
+ JPGD_ASSERT(k < 64);
+
+ p[g_ZAG[k]] = static_cast(dequantize_ac(s, q[k])); //s * q[k];
+ }
+ else
+ {
+ if (r == 15)
+ {
+ if ((k + 16) > 64)
+ stop_decoding(JPGD_DECODE_ERROR);
+
+ if (k < prev_num_set)
+ {
+ int n = JPGD_MIN(16, prev_num_set - k);
+ int kt = k;
+ while (n--)
+ {
+ JPGD_ASSERT(kt <= 63);
+ p[g_ZAG[kt++]] = 0;
+ }
+ }
+
+ k += 16 - 1; // - 1 because the loop counter is k
+ // BEGIN EPIC MOD
+ JPGD_ASSERT(k < 64 && p[g_ZAG[k]] == 0);
+ // END EPIC MOD
+ }
+ else
+ break;
+ }
+ }
+
+ if (k < prev_num_set)
+ {
+ int kt = k;
+ while (kt < prev_num_set)
+ p[g_ZAG[kt++]] = 0;
+ }
+
+ m_mcu_block_max_zag[mcu_block] = k;
+
+ row_block++;
+ }
+
+ if (m_freq_domain_chroma_upsample)
+ transform_mcu_expand(mcu_row);
+ else
+ transform_mcu(mcu_row);
+
+ m_restarts_left--;
+ }
+ }
+
+ // YCbCr H1V1 (1x1:1:1, 3 m_blocks per MCU) to RGB
+ void jpeg_decoder::H1V1Convert()
+ {
+ int row = m_max_mcu_y_size - m_mcu_lines_left;
+ uint8 *d = m_pScan_line_0;
+ uint8 *s = m_pSample_buf + row * 8;
+
+ for (int i = m_max_mcus_per_row; i > 0; i--)
+ {
+ for (int j = 0; j < 8; j++)
+ {
+ int y = s[j];
+ int cb = s[64+j];
+ int cr = s[128+j];
+
+ if (jpg_format == ERGBFormatJPG::BGRA)
+ {
+ d[0] = clamp(y + m_cbb[cb]);
+ d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
+ d[2] = clamp(y + m_crr[cr]);
+ d[3] = 255;
+ }
+ else
+ {
+ d[0] = clamp(y + m_crr[cr]);
+ d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
+ d[2] = clamp(y + m_cbb[cb]);
+ d[3] = 255;
+ }
+ d += 4;
+ }
+
+ s += 64*3;
+ }
+ }
+
+ // YCbCr H2V1 (2x1:1:1, 4 m_blocks per MCU) to RGB
+ void jpeg_decoder::H2V1Convert()
+ {
+ int row = m_max_mcu_y_size - m_mcu_lines_left;
+ uint8 *d0 = m_pScan_line_0;
+ uint8 *y = m_pSample_buf + row * 8;
+ uint8 *c = m_pSample_buf + 2*64 + row * 8;
+
+ for (int i = m_max_mcus_per_row; i > 0; i--)
+ {
+ for (int l = 0; l < 2; l++)
+ {
+ for (int j = 0; j < 4; j++)
+ {
+ int cb = c[0];
+ int cr = c[64];
+
+ int rc = m_crr[cr];
+ int gc = ((m_crg[cr] + m_cbg[cb]) >> 16);
+ int bc = m_cbb[cb];
+
+ int yy = y[j<<1];
+ if (jpg_format == ERGBFormatJPG::BGRA)
+ {
+ d0[0] = clamp(yy+bc);
+ d0[1] = clamp(yy+gc);
+ d0[2] = clamp(yy+rc);
+ d0[3] = 255;
+ yy = y[(j<<1)+1];
+ d0[4] = clamp(yy+bc);
+ d0[5] = clamp(yy+gc);
+ d0[6] = clamp(yy+rc);
+ d0[7] = 255;
+ }
+ else
+ {
+ d0[0] = clamp(yy+rc);
+ d0[1] = clamp(yy+gc);
+ d0[2] = clamp(yy+bc);
+ d0[3] = 255;
+ yy = y[(j<<1)+1];
+ d0[4] = clamp(yy+rc);
+ d0[5] = clamp(yy+gc);
+ d0[6] = clamp(yy+bc);
+ d0[7] = 255;
+ }
+
+ d0 += 8;
+
+ c++;
+ }
+ y += 64;
+ }
+
+ y += 64*4 - 64*2;
+ c += 64*4 - 8;
+ }
+ }
+
+ // YCbCr H2V1 (1x2:1:1, 4 m_blocks per MCU) to RGB
+ void jpeg_decoder::H1V2Convert()
+ {
+ int row = m_max_mcu_y_size - m_mcu_lines_left;
+ uint8 *d0 = m_pScan_line_0;
+ uint8 *d1 = m_pScan_line_1;
+ uint8 *y;
+ uint8 *c;
+
+ if (row < 8)
+ y = m_pSample_buf + row * 8;
+ else
+ y = m_pSample_buf + 64*1 + (row & 7) * 8;
+
+ c = m_pSample_buf + 64*2 + (row >> 1) * 8;
+
+ for (int i = m_max_mcus_per_row; i > 0; i--)
+ {
+ for (int j = 0; j < 8; j++)
+ {
+ int cb = c[0+j];
+ int cr = c[64+j];
+
+ int rc = m_crr[cr];
+ int gc = ((m_crg[cr] + m_cbg[cb]) >> 16);
+ int bc = m_cbb[cb];
+
+ int yy = y[j];
+ if (jpg_format == ERGBFormatJPG::BGRA)
+ {
+ d0[0] = clamp(yy+bc);
+ d0[1] = clamp(yy+gc);
+ d0[2] = clamp(yy+rc);
+ d0[3] = 255;
+ yy = y[8+j];
+ d1[0] = clamp(yy+bc);
+ d1[1] = clamp(yy+gc);
+ d1[2] = clamp(yy+rc);
+ d1[3] = 255;
+ }
+ else
+ {
+ d0[0] = clamp(yy+rc);
+ d0[1] = clamp(yy+gc);
+ d0[2] = clamp(yy+bc);
+ d0[3] = 255;
+ yy = y[8+j];
+ d1[0] = clamp(yy+rc);
+ d1[1] = clamp(yy+gc);
+ d1[2] = clamp(yy+bc);
+ d1[3] = 255;
+ }
+
+ d0 += 4;
+ d1 += 4;
+ }
+
+ y += 64*4;
+ c += 64*4;
+ }
+ }
+
+ // YCbCr H2V2 (2x2:1:1, 6 m_blocks per MCU) to RGB
+ void jpeg_decoder::H2V2Convert()
+ {
+ int row = m_max_mcu_y_size - m_mcu_lines_left;
+ uint8 *d0 = m_pScan_line_0;
+ uint8 *d1 = m_pScan_line_1;
+ uint8 *y;
+ uint8 *c;
+
+ if (row < 8)
+ y = m_pSample_buf + row * 8;
+ else
+ y = m_pSample_buf + 64*2 + (row & 7) * 8;
+
+ c = m_pSample_buf + 64*4 + (row >> 1) * 8;
+
+ for (int i = m_max_mcus_per_row; i > 0; i--)
+ {
+ for (int l = 0; l < 2; l++)
+ {
+ for (int j = 0; j < 8; j += 2)
+ {
+ int cb = c[0];
+ int cr = c[64];
+
+ int rc = m_crr[cr];
+ int gc = ((m_crg[cr] + m_cbg[cb]) >> 16);
+ int bc = m_cbb[cb];
+
+ int yy = y[j];
+ if (jpg_format == ERGBFormatJPG::BGRA)
+ {
+ d0[0] = clamp(yy+bc);
+ d0[1] = clamp(yy+gc);
+ d0[2] = clamp(yy+rc);
+ d0[3] = 255;
+ yy = y[j+1];
+ d0[4] = clamp(yy+bc);
+ d0[5] = clamp(yy+gc);
+ d0[6] = clamp(yy+rc);
+ d0[7] = 255;
+ yy = y[j+8];
+ d1[0] = clamp(yy+bc);
+ d1[1] = clamp(yy+gc);
+ d1[2] = clamp(yy+rc);
+ d1[3] = 255;
+ yy = y[j+8+1];
+ d1[4] = clamp(yy+bc);
+ d1[5] = clamp(yy+gc);
+ d1[6] = clamp(yy+rc);
+ d1[7] = 255;
+ }
+ else
+ {
+ d0[0] = clamp(yy+rc);
+ d0[1] = clamp(yy+gc);
+ d0[2] = clamp(yy+bc);
+ d0[3] = 255;
+ yy = y[j+1];
+ d0[4] = clamp(yy+rc);
+ d0[5] = clamp(yy+gc);
+ d0[6] = clamp(yy+bc);
+ d0[7] = 255;
+ yy = y[j+8];
+ d1[0] = clamp(yy+rc);
+ d1[1] = clamp(yy+gc);
+ d1[2] = clamp(yy+bc);
+ d1[3] = 255;
+ yy = y[j+8+1];
+ d1[4] = clamp(yy+rc);
+ d1[5] = clamp(yy+gc);
+ d1[6] = clamp(yy+bc);
+ d1[7] = 255;
+ }
+
+ d0 += 8;
+ d1 += 8;
+
+ c++;
+ }
+ y += 64;
+ }
+
+ y += 64*6 - 64*2;
+ c += 64*6 - 8;
+ }
+ }
+
+ // Y (1 block per MCU) to 8-bit grayscale
+ void jpeg_decoder::gray_convert()
+ {
+ int row = m_max_mcu_y_size - m_mcu_lines_left;
+ uint8 *d = m_pScan_line_0;
+ uint8 *s = m_pSample_buf + row * 8;
+
+ for (int i = m_max_mcus_per_row; i > 0; i--)
+ {
+ *(uint *)d = *(uint *)s;
+ *(uint *)(&d[4]) = *(uint *)(&s[4]);
+
+ s += 64;
+ d += 8;
+ }
+ }
+
+ void jpeg_decoder::expanded_convert()
+ {
+ int row = m_max_mcu_y_size - m_mcu_lines_left;
+
+ uint8* Py = m_pSample_buf + (row / 8) * 64 * m_comp_h_samp[0] + (row & 7) * 8;
+
+ uint8* d = m_pScan_line_0;
+
+ for (int i = m_max_mcus_per_row; i > 0; i--)
+ {
+ for (int k = 0; k < m_max_mcu_x_size; k += 8)
+ {
+ const int Y_ofs = k * 8;
+ const int Cb_ofs = Y_ofs + 64 * m_expanded_blocks_per_component;
+ const int Cr_ofs = Y_ofs + 64 * m_expanded_blocks_per_component * 2;
+ for (int j = 0; j < 8; j++)
+ {
+ int y = Py[Y_ofs + j];
+ int cb = Py[Cb_ofs + j];
+ int cr = Py[Cr_ofs + j];
+
+ if (jpg_format == ERGBFormatJPG::BGRA)
+ {
+ d[0] = clamp(y + m_cbb[cb]);
+ d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
+ d[2] = clamp(y + m_crr[cr]);
+ d[3] = 255;
+ }
+ else
+ {
+ d[0] = clamp(y + m_crr[cr]);
+ d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
+ d[2] = clamp(y + m_cbb[cb]);
+ d[3] = 255;
+ }
+
+ d += 4;
+ }
+ }
+
+ Py += 64 * m_expanded_blocks_per_mcu;
+ }
+ }
+
+ // Find end of image (EOI) marker, so we can return to the user the exact size of the input stream.
+ void jpeg_decoder::find_eoi()
+ {
+ if (!m_progressive_flag)
+ {
+ // Attempt to read the EOI marker.
+ //get_bits_no_markers(m_bits_left & 7);
+
+ // Prime the bit buffer
+ m_bits_left = 16;
+ get_bits(16);
+ get_bits(16);
+
+ // The next marker _should_ be EOI
+ process_markers();
+ }
+
+ m_total_bytes_read -= m_in_buf_left;
+ }
+
+ int jpeg_decoder::decode(const void** pScan_line, uint* pScan_line_len)
+ {
+ if ((m_error_code) || (!m_ready_flag))
+ return JPGD_FAILED;
+
+ if (m_total_lines_left == 0)
+ return JPGD_DONE;
+
+ if (m_mcu_lines_left == 0)
+ {
+ if (setjmp(m_jmp_state))
+ return JPGD_FAILED;
+
+ if (m_progressive_flag)
+ load_next_row();
+ else
+ decode_next_row();
+
+ // Find the EOI marker if that was the last row.
+ if (m_total_lines_left <= m_max_mcu_y_size)
+ find_eoi();
+
+ m_mcu_lines_left = m_max_mcu_y_size;
+ }
+
+ if (m_freq_domain_chroma_upsample)
+ {
+ expanded_convert();
+ *pScan_line = m_pScan_line_0;
+ }
+ else
+ {
+ switch (m_scan_type)
+ {
+ case JPGD_YH2V2:
+ {
+ if ((m_mcu_lines_left & 1) == 0)
+ {
+ H2V2Convert();
+ *pScan_line = m_pScan_line_0;
+ }
+ else
+ *pScan_line = m_pScan_line_1;
+
+ break;
+ }
+ case JPGD_YH2V1:
+ {
+ H2V1Convert();
+ *pScan_line = m_pScan_line_0;
+ break;
+ }
+ case JPGD_YH1V2:
+ {
+ if ((m_mcu_lines_left & 1) == 0)
+ {
+ H1V2Convert();
+ *pScan_line = m_pScan_line_0;
+ }
+ else
+ *pScan_line = m_pScan_line_1;
+
+ break;
+ }
+ case JPGD_YH1V1:
+ {
+ H1V1Convert();
+ *pScan_line = m_pScan_line_0;
+ break;
+ }
+ case JPGD_GRAYSCALE:
+ {
+ gray_convert();
+ *pScan_line = m_pScan_line_0;
+
+ break;
+ }
+ }
+ }
+
+ *pScan_line_len = m_real_dest_bytes_per_scan_line;
+
+ m_mcu_lines_left--;
+ m_total_lines_left--;
+
+ return JPGD_SUCCESS;
+ }
+
+ // Creates the tables needed for efficient Huffman decoding.
+ void jpeg_decoder::make_huff_table(int index, huff_tables *pH)
+ {
+ int p, i, l, si;
+ uint8 huffsize[257];
+ uint huffcode[257];
+ uint code;
+ uint subtree;
+ int code_size;
+ int lastp;
+ int nextfreeentry;
+ int currententry;
+
+ pH->ac_table = m_huff_ac[index] != 0;
+
+ p = 0;
+
+ for (l = 1; l <= 16; l++)
+ {
+ for (i = 1; i <= m_huff_num[index][l]; i++)
+ huffsize[p++] = static_cast(l);
+ }
+
+ huffsize[p] = 0;
+
+ lastp = p;
+
+ code = 0;
+ si = huffsize[0];
+ p = 0;
+
+ while (huffsize[p])
+ {
+ while (huffsize[p] == si)
+ {
+ huffcode[p++] = code;
+ code++;
+ }
+
+ code <<= 1;
+ si++;
+ }
+
+ memset(pH->look_up, 0, sizeof(pH->look_up));
+ memset(pH->look_up2, 0, sizeof(pH->look_up2));
+ memset(pH->tree, 0, sizeof(pH->tree));
+ memset(pH->code_size, 0, sizeof(pH->code_size));
+
+ nextfreeentry = -1;
+
+ p = 0;
+
+ while (p < lastp)
+ {
+ i = m_huff_val[index][p];
+ code = huffcode[p];
+ code_size = huffsize[p];
+
+ pH->code_size[i] = static_cast(code_size);
+
+ if (code_size <= 8)
+ {
+ code <<= (8 - code_size);
+
+ for (l = 1 << (8 - code_size); l > 0; l--)
+ {
+ JPGD_ASSERT(i < 256);
+
+ pH->look_up[code] = i;
+
+ bool has_extrabits = false;
+ int extra_bits = 0;
+ int num_extra_bits = i & 15;
+
+ int bits_to_fetch = code_size;
+ if (num_extra_bits)
+ {
+ int total_codesize = code_size + num_extra_bits;
+ if (total_codesize <= 8)
+ {
+ has_extrabits = true;
+ extra_bits = ((1 << num_extra_bits) - 1) & (code >> (8 - total_codesize));
+ JPGD_ASSERT(extra_bits <= 0x7FFF);
+ bits_to_fetch += num_extra_bits;
+ }
+ }
+
+ if (!has_extrabits)
+ pH->look_up2[code] = i | (bits_to_fetch << 8);
+ else
+ pH->look_up2[code] = i | 0x8000 | (extra_bits << 16) | (bits_to_fetch << 8);
+
+ code++;
+ }
+ }
+ else
+ {
+ subtree = (code >> (code_size - 8)) & 0xFF;
+
+ currententry = pH->look_up[subtree];
+
+ if (currententry == 0)
+ {
+ pH->look_up[subtree] = currententry = nextfreeentry;
+ pH->look_up2[subtree] = currententry = nextfreeentry;
+
+ nextfreeentry -= 2;
+ }
+
+ code <<= (16 - (code_size - 8));
+
+ for (l = code_size; l > 9; l--)
+ {
+ if ((code & 0x8000) == 0)
+ currententry--;
+
+ if (pH->tree[-currententry - 1] == 0)
+ {
+ pH->tree[-currententry - 1] = nextfreeentry;
+
+ currententry = nextfreeentry;
+
+ nextfreeentry -= 2;
+ }
+ else
+ currententry = pH->tree[-currententry - 1];
+
+ code <<= 1;
+ }
+
+ if ((code & 0x8000) == 0)
+ currententry--;
+
+ pH->tree[-currententry - 1] = i;
+ }
+
+ p++;
+ }
+ }
+
+ // Verifies the quantization tables needed for this scan are available.
+ void jpeg_decoder::check_quant_tables()
+ {
+ for (int i = 0; i < m_comps_in_scan; i++)
+ if (m_quant[m_comp_quant[m_comp_list[i]]] == NULL)
+ stop_decoding(JPGD_UNDEFINED_QUANT_TABLE);
+ }
+
+ // Verifies that all the Huffman tables needed for this scan are available.
+ void jpeg_decoder::check_huff_tables()
+ {
+ for (int i = 0; i < m_comps_in_scan; i++)
+ {
+ if ((m_spectral_start == 0) && (m_huff_num[m_comp_dc_tab[m_comp_list[i]]] == NULL))
+ stop_decoding(JPGD_UNDEFINED_HUFF_TABLE);
+
+ if ((m_spectral_end > 0) && (m_huff_num[m_comp_ac_tab[m_comp_list[i]]] == NULL))
+ stop_decoding(JPGD_UNDEFINED_HUFF_TABLE);
+ }
+
+ for (int i = 0; i < JPGD_MAX_HUFF_TABLES; i++)
+ if (m_huff_num[i])
+ {
+ if (!m_pHuff_tabs[i])
+ m_pHuff_tabs[i] = (huff_tables *)alloc(sizeof(huff_tables));
+
+ make_huff_table(i, m_pHuff_tabs[i]);
+ }
+ }
+
+ // Determines the component order inside each MCU.
+ // Also calcs how many MCU's are on each row, etc.
+ void jpeg_decoder::calc_mcu_block_order()
+ {
+ int component_num, component_id;
+ int max_h_samp = 0, max_v_samp = 0;
+
+ for (component_id = 0; component_id < m_comps_in_frame; component_id++)
+ {
+ if (m_comp_h_samp[component_id] > max_h_samp)
+ max_h_samp = m_comp_h_samp[component_id];
+
+ if (m_comp_v_samp[component_id] > max_v_samp)
+ max_v_samp = m_comp_v_samp[component_id];
+ }
+
+ for (component_id = 0; component_id < m_comps_in_frame; component_id++)
+ {
+ m_comp_h_blocks[component_id] = ((((m_image_x_size * m_comp_h_samp[component_id]) + (max_h_samp - 1)) / max_h_samp) + 7) / 8;
+ m_comp_v_blocks[component_id] = ((((m_image_y_size * m_comp_v_samp[component_id]) + (max_v_samp - 1)) / max_v_samp) + 7) / 8;
+ }
+
+ if (m_comps_in_scan == 1)
+ {
+ m_mcus_per_row = m_comp_h_blocks[m_comp_list[0]];
+ m_mcus_per_col = m_comp_v_blocks[m_comp_list[0]];
+ }
+ else
+ {
+ m_mcus_per_row = (((m_image_x_size + 7) / 8) + (max_h_samp - 1)) / max_h_samp;
+ m_mcus_per_col = (((m_image_y_size + 7) / 8) + (max_v_samp - 1)) / max_v_samp;
+ }
+
+ if (m_comps_in_scan == 1)
+ {
+ m_mcu_org[0] = m_comp_list[0];
+
+ m_blocks_per_mcu = 1;
+ }
+ else
+ {
+ m_blocks_per_mcu = 0;
+
+ for (component_num = 0; component_num < m_comps_in_scan; component_num++)
+ {
+ int num_blocks;
+
+ component_id = m_comp_list[component_num];
+
+ num_blocks = m_comp_h_samp[component_id] * m_comp_v_samp[component_id];
+
+ while (num_blocks--)
+ m_mcu_org[m_blocks_per_mcu++] = component_id;
+ }
+ }
+ }
+
+ // Starts a new scan.
+ int jpeg_decoder::init_scan()
+ {
+ if (!locate_sos_marker())
+ return JPGD_FALSE;
+
+ calc_mcu_block_order();
+
+ check_huff_tables();
+
+ check_quant_tables();
+
+ memset(m_last_dc_val, 0, m_comps_in_frame * sizeof(uint));
+
+ m_eob_run = 0;
+
+ if (m_restart_interval)
+ {
+ m_restarts_left = m_restart_interval;
+ m_next_restart_num = 0;
+ }
+
+ fix_in_buffer();
+
+ return JPGD_TRUE;
+ }
+
+ // Starts a frame. Determines if the number of components or sampling factors
+ // are supported.
+ void jpeg_decoder::init_frame()
+ {
+ int i;
+
+ if (m_comps_in_frame == 1)
+ {
+ if ((m_comp_h_samp[0] != 1) || (m_comp_v_samp[0] != 1))
+ stop_decoding(JPGD_UNSUPPORTED_SAMP_FACTORS);
+
+ m_scan_type = JPGD_GRAYSCALE;
+ m_max_blocks_per_mcu = 1;
+ m_max_mcu_x_size = 8;
+ m_max_mcu_y_size = 8;
+ }
+ else if (m_comps_in_frame == 3)
+ {
+ if ( ((m_comp_h_samp[1] != 1) || (m_comp_v_samp[1] != 1)) ||
+ ((m_comp_h_samp[2] != 1) || (m_comp_v_samp[2] != 1)) )
+ stop_decoding(JPGD_UNSUPPORTED_SAMP_FACTORS);
+
+ if ((m_comp_h_samp[0] == 1) && (m_comp_v_samp[0] == 1))
+ {
+ m_scan_type = JPGD_YH1V1;
+
+ m_max_blocks_per_mcu = 3;
+ m_max_mcu_x_size = 8;
+ m_max_mcu_y_size = 8;
+ }
+ else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 1))
+ {
+ m_scan_type = JPGD_YH2V1;
+ m_max_blocks_per_mcu = 4;
+ m_max_mcu_x_size = 16;
+ m_max_mcu_y_size = 8;
+ }
+ else if ((m_comp_h_samp[0] == 1) && (m_comp_v_samp[0] == 2))
+ {
+ m_scan_type = JPGD_YH1V2;
+ m_max_blocks_per_mcu = 4;
+ m_max_mcu_x_size = 8;
+ m_max_mcu_y_size = 16;
+ }
+ else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 2))
+ {
+ m_scan_type = JPGD_YH2V2;
+ m_max_blocks_per_mcu = 6;
+ m_max_mcu_x_size = 16;
+ m_max_mcu_y_size = 16;
+ }
+ else
+ stop_decoding(JPGD_UNSUPPORTED_SAMP_FACTORS);
+ }
+ else
+ stop_decoding(JPGD_UNSUPPORTED_COLORSPACE);
+
+ m_max_mcus_per_row = (m_image_x_size + (m_max_mcu_x_size - 1)) / m_max_mcu_x_size;
+ m_max_mcus_per_col = (m_image_y_size + (m_max_mcu_y_size - 1)) / m_max_mcu_y_size;
+
+ // These values are for the *destination* pixels: after conversion.
+ if (m_scan_type == JPGD_GRAYSCALE)
+ m_dest_bytes_per_pixel = 1;
+ else
+ m_dest_bytes_per_pixel = 4;
+
+ m_dest_bytes_per_scan_line = ((m_image_x_size + 15) & 0xFFF0) * m_dest_bytes_per_pixel;
+
+ m_real_dest_bytes_per_scan_line = (m_image_x_size * m_dest_bytes_per_pixel);
+
+ // Initialize two scan line buffers.
+ m_pScan_line_0 = (uint8 *)alloc(m_dest_bytes_per_scan_line, true);
+ if ((m_scan_type == JPGD_YH1V2) || (m_scan_type == JPGD_YH2V2))
+ m_pScan_line_1 = (uint8 *)alloc(m_dest_bytes_per_scan_line, true);
+
+ m_max_blocks_per_row = m_max_mcus_per_row * m_max_blocks_per_mcu;
+
+ // Should never happen
+ if (m_max_blocks_per_row > JPGD_MAX_BLOCKS_PER_ROW)
+ stop_decoding(JPGD_ASSERTION_ERROR);
+
+ // Allocate the coefficient buffer, enough for one MCU
+ m_pMCU_coefficients = (jpgd_block_t*)alloc(m_max_blocks_per_mcu * 64 * sizeof(jpgd_block_t));
+
+ for (i = 0; i < m_max_blocks_per_mcu; i++)
+ m_mcu_block_max_zag[i] = 64;
+
+ m_expanded_blocks_per_component = m_comp_h_samp[0] * m_comp_v_samp[0];
+ m_expanded_blocks_per_mcu = m_expanded_blocks_per_component * m_comps_in_frame;
+ m_expanded_blocks_per_row = m_max_mcus_per_row * m_expanded_blocks_per_mcu;
+ // Freq. domain chroma upsampling is only supported for H2V2 subsampling factor.
+// BEGIN EPIC MOD
+#if JPGD_SUPPORT_FREQ_DOMAIN_UPSAMPLING
+ m_freq_domain_chroma_upsample = (m_expanded_blocks_per_mcu == 4*3);
+#else
+ m_freq_domain_chroma_upsample = 0;
+#endif
+// END EPIC MOD
+
+ if (m_freq_domain_chroma_upsample)
+ m_pSample_buf = (uint8 *)alloc(m_expanded_blocks_per_row * 64);
+ else
+ m_pSample_buf = (uint8 *)alloc(m_max_blocks_per_row * 64);
+
+ m_total_lines_left = m_image_y_size;
+
+ m_mcu_lines_left = 0;
+
+ create_look_ups();
+ }
+
+ // The coeff_buf series of methods originally stored the coefficients
+ // into a "virtual" file which was located in EMS, XMS, or a disk file. A cache
+ // was used to make this process more efficient. Now, we can store the entire
+ // thing in RAM.
+ jpeg_decoder::coeff_buf* jpeg_decoder::coeff_buf_open(int block_num_x, int block_num_y, int block_len_x, int block_len_y)
+ {
+ coeff_buf* cb = (coeff_buf*)alloc(sizeof(coeff_buf));
+
+ cb->block_num_x = block_num_x;
+ cb->block_num_y = block_num_y;
+ cb->block_len_x = block_len_x;
+ cb->block_len_y = block_len_y;
+ cb->block_size = (block_len_x * block_len_y) * sizeof(jpgd_block_t);
+ cb->pData = (uint8 *)alloc(cb->block_size * block_num_x * block_num_y, true);
+ return cb;
+ }
+
+ inline jpgd_block_t *jpeg_decoder::coeff_buf_getp(coeff_buf *cb, int block_x, int block_y)
+ {
+ JPGD_ASSERT((block_x < cb->block_num_x) && (block_y < cb->block_num_y));
+ return (jpgd_block_t *)(cb->pData + block_x * cb->block_size + block_y * (cb->block_size * cb->block_num_x));
+ }
+
+ // The following methods decode the various types of m_blocks encountered
+ // in progressively encoded images.
+ void jpeg_decoder::decode_block_dc_first(jpeg_decoder *pD, int component_id, int block_x, int block_y)
+ {
+ int s, r;
+ jpgd_block_t *p = pD->coeff_buf_getp(pD->m_dc_coeffs[component_id], block_x, block_y);
+
+ if ((s = pD->huff_decode(pD->m_pHuff_tabs[pD->m_comp_dc_tab[component_id]])) != 0)
+ {
+ r = pD->get_bits_no_markers(s);
+ s = HUFF_EXTEND(r, s);
+ }
+
+ pD->m_last_dc_val[component_id] = (s += pD->m_last_dc_val[component_id]);
+
+ p[0] = static_cast(s << pD->m_successive_low);
+ }
+
+ void jpeg_decoder::decode_block_dc_refine(jpeg_decoder *pD, int component_id, int block_x, int block_y)
+ {
+ if (pD->get_bits_no_markers(1))
+ {
+ jpgd_block_t *p = pD->coeff_buf_getp(pD->m_dc_coeffs[component_id], block_x, block_y);
+
+ p[0] |= (1 << pD->m_successive_low);
+ }
+ }
+
+ void jpeg_decoder::decode_block_ac_first(jpeg_decoder *pD, int component_id, int block_x, int block_y)
+ {
+ int k, s, r;
+
+ if (pD->m_eob_run)
+ {
+ pD->m_eob_run--;
+ return;
+ }
+
+ jpgd_block_t *p = pD->coeff_buf_getp(pD->m_ac_coeffs[component_id], block_x, block_y);
+
+ for (k = pD->m_spectral_start; k <= pD->m_spectral_end; k++)
+ {
+ s = pD->huff_decode(pD->m_pHuff_tabs[pD->m_comp_ac_tab[component_id]]);
+
+ r = s >> 4;
+ s &= 15;
+
+ if (s)
+ {
+ if ((k += r) > 63)
+ pD->stop_decoding(JPGD_DECODE_ERROR);
+
+ r = pD->get_bits_no_markers(s);
+ s = HUFF_EXTEND(r, s);
+
+ p[g_ZAG[k]] = static_cast(s << pD->m_successive_low);
+ }
+ else
+ {
+ if (r == 15)
+ {
+ if ((k += 15) > 63)
+ pD->stop_decoding(JPGD_DECODE_ERROR);
+ }
+ else
+ {
+ pD->m_eob_run = 1 << r;
+
+ if (r)
+ pD->m_eob_run += pD->get_bits_no_markers(r);
+
+ pD->m_eob_run--;
+
+ break;
+ }
+ }
+ }
+ }
+
+ void jpeg_decoder::decode_block_ac_refine(jpeg_decoder *pD, int component_id, int block_x, int block_y)
+ {
+ int s, k, r;
+ int p1 = 1 << pD->m_successive_low;
+ int m1 = (-1) << pD->m_successive_low;
+ jpgd_block_t *p = pD->coeff_buf_getp(pD->m_ac_coeffs[component_id], block_x, block_y);
+
+ k = pD->m_spectral_start;
+
+ if (pD->m_eob_run == 0)
+ {
+ for ( ; k <= pD->m_spectral_end; k++)
+ {
+ s = pD->huff_decode(pD->m_pHuff_tabs[pD->m_comp_ac_tab[component_id]]);
+
+ r = s >> 4;
+ s &= 15;
+
+ if (s)
+ {
+ if (s != 1)
+ pD->stop_decoding(JPGD_DECODE_ERROR);
+
+ if (pD->get_bits_no_markers(1))
+ s = p1;
+ else
+ s = m1;
+ }
+ else
+ {
+ if (r != 15)
+ {
+ pD->m_eob_run = 1 << r;
+
+ if (r)
+ pD->m_eob_run += pD->get_bits_no_markers(r);
+
+ break;
+ }
+ }
+
+ do
+ {
+ // BEGIN EPIC MOD
+ JPGD_ASSERT(k < 64);
+ // END EPIC MOD
+
+ jpgd_block_t *this_coef = p + g_ZAG[k];
+
+ if (*this_coef != 0)
+ {
+ if (pD->get_bits_no_markers(1))
+ {
+ if ((*this_coef & p1) == 0)
+ {
+ if (*this_coef >= 0)
+ *this_coef = static_cast(*this_coef + p1);
+ else
+ *this_coef = static_cast(*this_coef + m1);
+ }
+ }
+ }
+ else
+ {
+ if (--r < 0)
+ break;
+ }
+
+ k++;
+
+ } while (k <= pD->m_spectral_end);
+
+ if ((s) && (k < 64))
+ {
+ p[g_ZAG[k]] = static_cast(s);
+ }
+ }
+ }
+
+ if (pD->m_eob_run > 0)
+ {
+ for ( ; k <= pD->m_spectral_end; k++)
+ {
+ // BEGIN EPIC MOD
+ JPGD_ASSERT(k < 64);
+ // END EPIC MOD
+
+ jpgd_block_t *this_coef = p + g_ZAG[k];
+
+ if (*this_coef != 0)
+ {
+ if (pD->get_bits_no_markers(1))
+ {
+ if ((*this_coef & p1) == 0)
+ {
+ if (*this_coef >= 0)
+ *this_coef = static_cast(*this_coef + p1);
+ else
+ *this_coef = static_cast(*this_coef + m1);
+ }
+ }
+ }
+ }
+
+ pD->m_eob_run--;
+ }
+ }
+
+ // Decode a scan in a progressively encoded image.
+ void jpeg_decoder::decode_scan(pDecode_block_func decode_block_func)
+ {
+ int mcu_row, mcu_col, mcu_block;
+ int block_x_mcu[JPGD_MAX_COMPONENTS], m_block_y_mcu[JPGD_MAX_COMPONENTS];
+
+ memset(m_block_y_mcu, 0, sizeof(m_block_y_mcu));
+
+ for (mcu_col = 0; mcu_col < m_mcus_per_col; mcu_col++)
+ {
+ int component_num, component_id;
+
+ memset(block_x_mcu, 0, sizeof(block_x_mcu));
+
+ for (mcu_row = 0; mcu_row < m_mcus_per_row; mcu_row++)
+ {
+ int block_x_mcu_ofs = 0, block_y_mcu_ofs = 0;
+
+ if ((m_restart_interval) && (m_restarts_left == 0))
+ process_restart();
+
+ for (mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++)
+ {
+ component_id = m_mcu_org[mcu_block];
+
+ decode_block_func(this, component_id, block_x_mcu[component_id] + block_x_mcu_ofs, m_block_y_mcu[component_id] + block_y_mcu_ofs);
+
+ if (m_comps_in_scan == 1)
+ block_x_mcu[component_id]++;
+ else
+ {
+ if (++block_x_mcu_ofs == m_comp_h_samp[component_id])
+ {
+ block_x_mcu_ofs = 0;
+
+ if (++block_y_mcu_ofs == m_comp_v_samp[component_id])
+ {
+ block_y_mcu_ofs = 0;
+ block_x_mcu[component_id] += m_comp_h_samp[component_id];
+ }
+ }
+ }
+ }
+
+ m_restarts_left--;
+ }
+
+ if (m_comps_in_scan == 1)
+ m_block_y_mcu[m_comp_list[0]]++;
+ else
+ {
+ for (component_num = 0; component_num < m_comps_in_scan; component_num++)
+ {
+ component_id = m_comp_list[component_num];
+ m_block_y_mcu[component_id] += m_comp_v_samp[component_id];
+ }
+ }
+ }
+ }
+
+ // Decode a progressively encoded image.
+ void jpeg_decoder::init_progressive()
+ {
+ int i;
+
+ if (m_comps_in_frame == 4)
+ stop_decoding(JPGD_UNSUPPORTED_COLORSPACE);
+
+ // Allocate the coefficient buffers.
+ for (i = 0; i < m_comps_in_frame; i++)
+ {
+ m_dc_coeffs[i] = coeff_buf_open(m_max_mcus_per_row * m_comp_h_samp[i], m_max_mcus_per_col * m_comp_v_samp[i], 1, 1);
+ m_ac_coeffs[i] = coeff_buf_open(m_max_mcus_per_row * m_comp_h_samp[i], m_max_mcus_per_col * m_comp_v_samp[i], 8, 8);
+ }
+
+ for ( ; ; )
+ {
+ int dc_only_scan, refinement_scan;
+ pDecode_block_func decode_block_func;
+
+ if (!init_scan())
+ break;
+
+ dc_only_scan = (m_spectral_start == 0);
+ refinement_scan = (m_successive_high != 0);
+
+ if ((m_spectral_start > m_spectral_end) || (m_spectral_end > 63))
+ stop_decoding(JPGD_BAD_SOS_SPECTRAL);
+
+ if (dc_only_scan)
+ {
+ if (m_spectral_end)
+ stop_decoding(JPGD_BAD_SOS_SPECTRAL);
+ }
+ else if (m_comps_in_scan != 1) /* AC scans can only contain one component */
+ stop_decoding(JPGD_BAD_SOS_SPECTRAL);
+
+ if ((refinement_scan) && (m_successive_low != m_successive_high - 1))
+ stop_decoding(JPGD_BAD_SOS_SUCCESSIVE);
+
+ if (dc_only_scan)
+ {
+ if (refinement_scan)
+ decode_block_func = decode_block_dc_refine;
+ else
+ decode_block_func = decode_block_dc_first;
+ }
+ else
+ {
+ if (refinement_scan)
+ decode_block_func = decode_block_ac_refine;
+ else
+ decode_block_func = decode_block_ac_first;
+ }
+
+ decode_scan(decode_block_func);
+
+ m_bits_left = 16;
+ get_bits(16);
+ get_bits(16);
+ }
+
+ m_comps_in_scan = m_comps_in_frame;
+
+ for (i = 0; i < m_comps_in_frame; i++)
+ m_comp_list[i] = i;
+
+ calc_mcu_block_order();
+ }
+
+ void jpeg_decoder::init_sequential()
+ {
+ if (!init_scan())
+ stop_decoding(JPGD_UNEXPECTED_MARKER);
+ }
+
+ void jpeg_decoder::decode_start()
+ {
+ init_frame();
+
+ if (m_progressive_flag)
+ init_progressive();
+ else
+ init_sequential();
+ }
+
+ void jpeg_decoder::decode_init(jpeg_decoder_stream *pStream)
+ {
+ init(pStream);
+ locate_sof_marker();
+ }
+
+ jpeg_decoder::jpeg_decoder(jpeg_decoder_stream *pStream)
+ {
+ if (setjmp(m_jmp_state))
+ return;
+ decode_init(pStream);
+ }
+
+ int jpeg_decoder::begin_decoding()
+ {
+ if (m_ready_flag)
+ return JPGD_SUCCESS;
+
+ if (m_error_code)
+ return JPGD_FAILED;
+
+ if (setjmp(m_jmp_state))
+ return JPGD_FAILED;
+
+ decode_start();
+
+ m_ready_flag = true;
+
+ return JPGD_SUCCESS;
+ }
+
+ jpeg_decoder::~jpeg_decoder()
+ {
+ free_all_blocks();
+ }
+
+ jpeg_decoder_file_stream::jpeg_decoder_file_stream()
+ {
+ m_pFile = NULL;
+ m_eof_flag = false;
+ m_error_flag = false;
+ }
+
+ void jpeg_decoder_file_stream::close()
+ {
+ if (m_pFile)
+ {
+ fclose(m_pFile);
+ m_pFile = NULL;
+ }
+
+ m_eof_flag = false;
+ m_error_flag = false;
+ }
+
+ jpeg_decoder_file_stream::~jpeg_decoder_file_stream()
+ {
+ close();
+ }
+
+ bool jpeg_decoder_file_stream::open(const char *Pfilename)
+ {
+ close();
+
+ m_eof_flag = false;
+ m_error_flag = false;
+
+#if defined(_MSC_VER)
+ m_pFile = NULL;
+ fopen_s(&m_pFile, Pfilename, "rb");
+#else
+ m_pFile = fopen(Pfilename, "rb");
+#endif
+ return m_pFile != NULL;
+ }
+
+ int jpeg_decoder_file_stream::read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag)
+ {
+ if (!m_pFile)
+ return -1;
+
+ if (m_eof_flag)
+ {
+ *pEOF_flag = true;
+ return 0;
+ }
+
+ if (m_error_flag)
+ return -1;
+
+ int bytes_read = static_cast(fread(pBuf, 1, max_bytes_to_read, m_pFile));
+ if (bytes_read < max_bytes_to_read)
+ {
+ if (ferror(m_pFile))
+ {
+ m_error_flag = true;
+ return -1;
+ }
+
+ m_eof_flag = true;
+ *pEOF_flag = true;
+ }
+
+ return bytes_read;
+ }
+
+ bool jpeg_decoder_mem_stream::open(const uint8 *pSrc_data, uint size)
+ {
+ close();
+ m_pSrc_data = pSrc_data;
+ m_ofs = 0;
+ m_size = size;
+ return true;
+ }
+
+ int jpeg_decoder_mem_stream::read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag)
+ {
+ *pEOF_flag = false;
+
+ if (!m_pSrc_data)
+ return -1;
+
+ uint bytes_remaining = m_size - m_ofs;
+ if ((uint)max_bytes_to_read > bytes_remaining)
+ {
+ max_bytes_to_read = bytes_remaining;
+ *pEOF_flag = true;
+ }
+
+ memcpy(pBuf, m_pSrc_data + m_ofs, max_bytes_to_read);
+ m_ofs += max_bytes_to_read;
+
+ return max_bytes_to_read;
+ }
+
+ unsigned char *decompress_jpeg_image_from_stream(jpeg_decoder_stream *pStream, int *width, int *height, int *actual_comps, int req_comps)
+ {
+ if (!actual_comps)
+ return NULL;
+ *actual_comps = 0;
+
+ if ((!pStream) || (!width) || (!height) || (!req_comps))
+ return NULL;
+
+ if ((req_comps != 1) && (req_comps != 3) && (req_comps != 4))
+ return NULL;
+
+ jpeg_decoder decoder(pStream);
+ if (decoder.get_error_code() != JPGD_SUCCESS)
+ return NULL;
+
+ const int image_width = decoder.get_width(), image_height = decoder.get_height();
+ *width = image_width;
+ *height = image_height;
+ *actual_comps = decoder.get_num_components();
+
+ if (decoder.begin_decoding() != JPGD_SUCCESS)
+ return NULL;
+
+ const int dst_bpl = image_width * req_comps;
+
+ uint8 *pImage_data = (uint8*)jpgd_malloc(dst_bpl * image_height);
+ if (!pImage_data)
+ return NULL;
+
+ for (int y = 0; y < image_height; y++)
+ {
+ const uint8* pScan_line = 0;
+ uint scan_line_len;
+ if (decoder.decode((const void**)&pScan_line, &scan_line_len) != JPGD_SUCCESS)
+ {
+ jpgd_free(pImage_data);
+ return NULL;
+ }
+
+ uint8 *pDst = pImage_data + y * dst_bpl;
+
+ if (((req_comps == 4) && (decoder.get_num_components() == 3)) ||
+ ((req_comps == 1) && (decoder.get_num_components() == 1)))
+ {
+ memcpy(pDst, pScan_line, dst_bpl);
+ }
+ else if (decoder.get_num_components() == 1)
+ {
+ if (req_comps == 3)
+ {
+ for (int x = 0; x < image_width; x++)
+ {
+ uint8 luma = pScan_line[x];
+ pDst[0] = luma;
+ pDst[1] = luma;
+ pDst[2] = luma;
+ pDst += 3;
+ }
+ }
+ else
+ {
+ for (int x = 0; x < image_width; x++)
+ {
+ uint8 luma = pScan_line[x];
+ pDst[0] = luma;
+ pDst[1] = luma;
+ pDst[2] = luma;
+ pDst[3] = 255;
+ pDst += 4;
+ }
+ }
+ }
+ else if (decoder.get_num_components() == 3)
+ {
+ if (req_comps == 1)
+ {
+ const int YR = 19595, YG = 38470, YB = 7471;
+ for (int x = 0; x < image_width; x++)
+ {
+ int r = pScan_line[x*4+0];
+ int g = pScan_line[x*4+1];
+ int b = pScan_line[x*4+2];
+ *pDst++ = static_cast((r * YR + g * YG + b * YB + 32768) >> 16);
+ }
+ }
+ else
+ {
+ for (int x = 0; x < image_width; x++)
+ {
+ pDst[0] = pScan_line[x*4+0];
+ pDst[1] = pScan_line[x*4+1];
+ pDst[2] = pScan_line[x*4+2];
+ pDst += 3;
+ }
+ }
+ }
+ }
+
+ return pImage_data;
+ }
+
+// BEGIN EPIC MOD
+ unsigned char *decompress_jpeg_image_from_memory(const unsigned char *pSrc_data, int src_data_size, int *width, int *height, int *actual_comps, int req_comps, int format)
+ {
+ jpg_format = (ERGBFormatJPG)format;
+// EMD EPIC MOD
+ jpgd::jpeg_decoder_mem_stream mem_stream(pSrc_data, src_data_size);
+ return decompress_jpeg_image_from_stream(&mem_stream, width, height, actual_comps, req_comps);
+ }
+
+ unsigned char *decompress_jpeg_image_from_file(const char *pSrc_filename, int *width, int *height, int *actual_comps, int req_comps)
+ {
+ jpgd::jpeg_decoder_file_stream file_stream;
+ if (!file_stream.open(pSrc_filename))
+ return NULL;
+ return decompress_jpeg_image_from_stream(&file_stream, width, height, actual_comps, req_comps);
+ }
+
+} // namespace jpgd
diff --git a/crazy_functions/test_project/cpp/longcode/jpge.cpp b/crazy_functions/test_project/cpp/longcode/jpge.cpp
new file mode 100644
index 0000000..2e26b71
--- /dev/null
+++ b/crazy_functions/test_project/cpp/longcode/jpge.cpp
@@ -0,0 +1,1049 @@
+// jpge.cpp - C++ class for JPEG compression.
+// Public domain, Rich Geldreich
+// v1.01, Dec. 18, 2010 - Initial release
+// v1.02, Apr. 6, 2011 - Removed 2x2 ordered dither in H2V1 chroma subsampling method load_block_16_8_8(). (The rounding factor was 2, when it should have been 1. Either way, it wasn't helping.)
+// v1.03, Apr. 16, 2011 - Added support for optimized Huffman code tables, optimized dynamic memory allocation down to only 1 alloc.
+// Also from Alex Evans: Added RGBA support, linear memory allocator (no longer needed in v1.03).
+// v1.04, May. 19, 2012: Forgot to set m_pFile ptr to NULL in cfile_stream::close(). Thanks to Owen Kaluza for reporting this bug.
+// Code tweaks to fix VS2008 static code analysis warnings (all looked harmless).
+// Code review revealed method load_block_16_8_8() (used for the non-default H2V1 sampling mode to downsample chroma) somehow didn't get the rounding factor fix from v1.02.
+
+#include "jpge.h"
+
+#include
+#include
+#if PLATFORM_WINDOWS
+#include
+#endif
+
+#define JPGE_MAX(a,b) (((a)>(b))?(a):(b))
+#define JPGE_MIN(a,b) (((a)<(b))?(a):(b))
+
+namespace jpge {
+
+static inline void *jpge_malloc(size_t nSize) { return FMemory::Malloc(nSize); }
+static inline void jpge_free(void *p) { FMemory::Free(p);; }
+
+// Various JPEG enums and tables.
+enum { M_SOF0 = 0xC0, M_DHT = 0xC4, M_SOI = 0xD8, M_EOI = 0xD9, M_SOS = 0xDA, M_DQT = 0xDB, M_APP0 = 0xE0 };
+enum { DC_LUM_CODES = 12, AC_LUM_CODES = 256, DC_CHROMA_CODES = 12, AC_CHROMA_CODES = 256, MAX_HUFF_SYMBOLS = 257, MAX_HUFF_CODESIZE = 32 };
+
+static uint8 s_zag[64] = { 0,1,8,16,9,2,3,10,17,24,32,25,18,11,4,5,12,19,26,33,40,48,41,34,27,20,13,6,7,14,21,28,35,42,49,56,57,50,43,36,29,22,15,23,30,37,44,51,58,59,52,45,38,31,39,46,53,60,61,54,47,55,62,63 };
+static int16 s_std_lum_quant[64] = { 16,11,12,14,12,10,16,14,13,14,18,17,16,19,24,40,26,24,22,22,24,49,35,37,29,40,58,51,61,60,57,51,56,55,64,72,92,78,64,68,87,69,55,56,80,109,81,87,95,98,103,104,103,62,77,113,121,112,100,120,92,101,103,99 };
+static int16 s_std_croma_quant[64] = { 17,18,18,24,21,24,47,26,26,47,99,66,56,66,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99 };
+static uint8 s_dc_lum_bits[17] = { 0,0,1,5,1,1,1,1,1,1,0,0,0,0,0,0,0 };
+static uint8 s_dc_lum_val[DC_LUM_CODES] = { 0,1,2,3,4,5,6,7,8,9,10,11 };
+static uint8 s_ac_lum_bits[17] = { 0,0,2,1,3,3,2,4,3,5,5,4,4,0,0,1,0x7d };
+static uint8 s_ac_lum_val[AC_LUM_CODES] =
+{
+ 0x01,0x02,0x03,0x00,0x04,0x11,0x05,0x12,0x21,0x31,0x41,0x06,0x13,0x51,0x61,0x07,0x22,0x71,0x14,0x32,0x81,0x91,0xa1,0x08,0x23,0x42,0xb1,0xc1,0x15,0x52,0xd1,0xf0,
+ 0x24,0x33,0x62,0x72,0x82,0x09,0x0a,0x16,0x17,0x18,0x19,0x1a,0x25,0x26,0x27,0x28,0x29,0x2a,0x34,0x35,0x36,0x37,0x38,0x39,0x3a,0x43,0x44,0x45,0x46,0x47,0x48,0x49,
+ 0x4a,0x53,0x54,0x55,0x56,0x57,0x58,0x59,0x5a,0x63,0x64,0x65,0x66,0x67,0x68,0x69,0x6a,0x73,0x74,0x75,0x76,0x77,0x78,0x79,0x7a,0x83,0x84,0x85,0x86,0x87,0x88,0x89,
+ 0x8a,0x92,0x93,0x94,0x95,0x96,0x97,0x98,0x99,0x9a,0xa2,0xa3,0xa4,0xa5,0xa6,0xa7,0xa8,0xa9,0xaa,0xb2,0xb3,0xb4,0xb5,0xb6,0xb7,0xb8,0xb9,0xba,0xc2,0xc3,0xc4,0xc5,
+ 0xc6,0xc7,0xc8,0xc9,0xca,0xd2,0xd3,0xd4,0xd5,0xd6,0xd7,0xd8,0xd9,0xda,0xe1,0xe2,0xe3,0xe4,0xe5,0xe6,0xe7,0xe8,0xe9,0xea,0xf1,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7,0xf8,
+ 0xf9,0xfa
+};
+static uint8 s_dc_chroma_bits[17] = { 0,0,3,1,1,1,1,1,1,1,1,1,0,0,0,0,0 };
+static uint8 s_dc_chroma_val[DC_CHROMA_CODES] = { 0,1,2,3,4,5,6,7,8,9,10,11 };
+static uint8 s_ac_chroma_bits[17] = { 0,0,2,1,2,4,4,3,4,7,5,4,4,0,1,2,0x77 };
+static uint8 s_ac_chroma_val[AC_CHROMA_CODES] =
+{
+ 0x00,0x01,0x02,0x03,0x11,0x04,0x05,0x21,0x31,0x06,0x12,0x41,0x51,0x07,0x61,0x71,0x13,0x22,0x32,0x81,0x08,0x14,0x42,0x91,0xa1,0xb1,0xc1,0x09,0x23,0x33,0x52,0xf0,
+ 0x15,0x62,0x72,0xd1,0x0a,0x16,0x24,0x34,0xe1,0x25,0xf1,0x17,0x18,0x19,0x1a,0x26,0x27,0x28,0x29,0x2a,0x35,0x36,0x37,0x38,0x39,0x3a,0x43,0x44,0x45,0x46,0x47,0x48,
+ 0x49,0x4a,0x53,0x54,0x55,0x56,0x57,0x58,0x59,0x5a,0x63,0x64,0x65,0x66,0x67,0x68,0x69,0x6a,0x73,0x74,0x75,0x76,0x77,0x78,0x79,0x7a,0x82,0x83,0x84,0x85,0x86,0x87,
+ 0x88,0x89,0x8a,0x92,0x93,0x94,0x95,0x96,0x97,0x98,0x99,0x9a,0xa2,0xa3,0xa4,0xa5,0xa6,0xa7,0xa8,0xa9,0xaa,0xb2,0xb3,0xb4,0xb5,0xb6,0xb7,0xb8,0xb9,0xba,0xc2,0xc3,
+ 0xc4,0xc5,0xc6,0xc7,0xc8,0xc9,0xca,0xd2,0xd3,0xd4,0xd5,0xd6,0xd7,0xd8,0xd9,0xda,0xe2,0xe3,0xe4,0xe5,0xe6,0xe7,0xe8,0xe9,0xea,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7,0xf8,
+ 0xf9,0xfa
+};
+
+// Low-level helper functions.
+template inline void clear_obj(T &obj) { memset(&obj, 0, sizeof(obj)); }
+
+const int YR = 19595, YG = 38470, YB = 7471, CB_R = -11059, CB_G = -21709, CB_B = 32768, CR_R = 32768, CR_G = -27439, CR_B = -5329;
+static inline uint8 clamp(int i) { if (static_cast(i) > 255U) { if (i < 0) i = 0; else if (i > 255) i = 255; } return static_cast(i); }
+
+static void RGB_to_YCC(uint8* pDst, const uint8 *pSrc, int num_pixels)
+{
+ for ( ; num_pixels; pDst += 3, pSrc += 3, num_pixels--)
+ {
+ const int r = pSrc[0], g = pSrc[1], b = pSrc[2];
+ pDst[0] = static_cast((r * YR + g * YG + b * YB + 32768) >> 16);
+ pDst[1] = clamp(128 + ((r * CB_R + g * CB_G + b * CB_B + 32768) >> 16));
+ pDst[2] = clamp(128 + ((r * CR_R + g * CR_G + b * CR_B + 32768) >> 16));
+ }
+}
+
+static void RGB_to_Y(uint8* pDst, const uint8 *pSrc, int num_pixels)
+{
+ for ( ; num_pixels; pDst++, pSrc += 3, num_pixels--)
+ pDst[0] = static_cast((pSrc[0] * YR + pSrc[1] * YG + pSrc[2] * YB + 32768) >> 16);
+}
+
+static void RGBA_to_YCC(uint8* pDst, const uint8 *pSrc, int num_pixels)
+{
+ for ( ; num_pixels; pDst += 3, pSrc += 4, num_pixels--)
+ {
+ const int r = pSrc[0], g = pSrc[1], b = pSrc[2];
+ pDst[0] = static_cast((r * YR + g * YG + b * YB + 32768) >> 16);
+ pDst[1] = clamp(128 + ((r * CB_R + g * CB_G + b * CB_B + 32768) >> 16));
+ pDst[2] = clamp(128 + ((r * CR_R + g * CR_G + b * CR_B + 32768) >> 16));
+ }
+}
+
+static void RGBA_to_Y(uint8* pDst, const uint8 *pSrc, int num_pixels)
+{
+ for ( ; num_pixels; pDst++, pSrc += 4, num_pixels--)
+ pDst[0] = static_cast((pSrc[0] * YR + pSrc[1] * YG + pSrc[2] * YB + 32768) >> 16);
+}
+
+static void Y_to_YCC(uint8* pDst, const uint8* pSrc, int num_pixels)
+{
+ for( ; num_pixels; pDst += 3, pSrc++, num_pixels--) { pDst[0] = pSrc[0]; pDst[1] = 128; pDst[2] = 128; }
+}
+
+// Forward DCT - DCT derived from jfdctint.
+#define CONST_BITS 13
+#define ROW_BITS 2
+#define DCT_DESCALE(x, n) (((x) + (((int32)1) << ((n) - 1))) >> (n))
+#define DCT_MUL(var, c) (static_cast(var) * static_cast(c))
+#define DCT1D(s0, s1, s2, s3, s4, s5, s6, s7) \
+ int32 t0 = s0 + s7, t7 = s0 - s7, t1 = s1 + s6, t6 = s1 - s6, t2 = s2 + s5, t5 = s2 - s5, t3 = s3 + s4, t4 = s3 - s4; \
+ int32 t10 = t0 + t3, t13 = t0 - t3, t11 = t1 + t2, t12 = t1 - t2; \
+ int32 u1 = DCT_MUL(t12 + t13, 4433); \
+ s2 = u1 + DCT_MUL(t13, 6270); \
+ s6 = u1 + DCT_MUL(t12, -15137); \
+ u1 = t4 + t7; \
+ int32 u2 = t5 + t6, u3 = t4 + t6, u4 = t5 + t7; \
+ int32 z5 = DCT_MUL(u3 + u4, 9633); \
+ t4 = DCT_MUL(t4, 2446); t5 = DCT_MUL(t5, 16819); \
+ t6 = DCT_MUL(t6, 25172); t7 = DCT_MUL(t7, 12299); \
+ u1 = DCT_MUL(u1, -7373); u2 = DCT_MUL(u2, -20995); \
+ u3 = DCT_MUL(u3, -16069); u4 = DCT_MUL(u4, -3196); \
+ u3 += z5; u4 += z5; \
+ s0 = t10 + t11; s1 = t7 + u1 + u4; s3 = t6 + u2 + u3; s4 = t10 - t11; s5 = t5 + u2 + u4; s7 = t4 + u1 + u3;
+
+static void DCT2D(int32 *p)
+{
+ int32 c, *q = p;
+ for (c = 7; c >= 0; c--, q += 8)
+ {
+ int32 s0 = q[0], s1 = q[1], s2 = q[2], s3 = q[3], s4 = q[4], s5 = q[5], s6 = q[6], s7 = q[7];
+ DCT1D(s0, s1, s2, s3, s4, s5, s6, s7);
+ q[0] = s0 << ROW_BITS; q[1] = DCT_DESCALE(s1, CONST_BITS-ROW_BITS); q[2] = DCT_DESCALE(s2, CONST_BITS-ROW_BITS); q[3] = DCT_DESCALE(s3, CONST_BITS-ROW_BITS);
+ q[4] = s4 << ROW_BITS; q[5] = DCT_DESCALE(s5, CONST_BITS-ROW_BITS); q[6] = DCT_DESCALE(s6, CONST_BITS-ROW_BITS); q[7] = DCT_DESCALE(s7, CONST_BITS-ROW_BITS);
+ }
+ for (q = p, c = 7; c >= 0; c--, q++)
+ {
+ int32 s0 = q[0*8], s1 = q[1*8], s2 = q[2*8], s3 = q[3*8], s4 = q[4*8], s5 = q[5*8], s6 = q[6*8], s7 = q[7*8];
+ DCT1D(s0, s1, s2, s3, s4, s5, s6, s7);
+ q[0*8] = DCT_DESCALE(s0, ROW_BITS+3); q[1*8] = DCT_DESCALE(s1, CONST_BITS+ROW_BITS+3); q[2*8] = DCT_DESCALE(s2, CONST_BITS+ROW_BITS+3); q[3*8] = DCT_DESCALE(s3, CONST_BITS+ROW_BITS+3);
+ q[4*8] = DCT_DESCALE(s4, ROW_BITS+3); q[5*8] = DCT_DESCALE(s5, CONST_BITS+ROW_BITS+3); q[6*8] = DCT_DESCALE(s6, CONST_BITS+ROW_BITS+3); q[7*8] = DCT_DESCALE(s7, CONST_BITS+ROW_BITS+3);
+ }
+}
+
+struct sym_freq { uint m_key, m_sym_index; };
+
+// Radix sorts sym_freq[] array by 32-bit key m_key. Returns ptr to sorted values.
+static inline sym_freq* radix_sort_syms(uint num_syms, sym_freq* pSyms0, sym_freq* pSyms1)
+{
+ const uint cMaxPasses = 4;
+ uint32 hist[256 * cMaxPasses]; clear_obj(hist);
+ for (uint i = 0; i < num_syms; i++) { uint freq = pSyms0[i].m_key; hist[freq & 0xFF]++; hist[256 + ((freq >> 8) & 0xFF)]++; hist[256*2 + ((freq >> 16) & 0xFF)]++; hist[256*3 + ((freq >> 24) & 0xFF)]++; }
+ sym_freq* pCur_syms = pSyms0, *pNew_syms = pSyms1;
+ uint total_passes = cMaxPasses; while ((total_passes > 1) && (num_syms == hist[(total_passes - 1) * 256])) total_passes--;
+ for (uint pass_shift = 0, pass = 0; pass < total_passes; pass++, pass_shift += 8)
+ {
+ const uint32* pHist = &hist[pass << 8];
+ uint offsets[256], cur_ofs = 0;
+ for (uint i = 0; i < 256; i++) { offsets[i] = cur_ofs; cur_ofs += pHist[i]; }
+ for (uint i = 0; i < num_syms; i++)
+ pNew_syms[offsets[(pCur_syms[i].m_key >> pass_shift) & 0xFF]++] = pCur_syms[i];
+ sym_freq* t = pCur_syms; pCur_syms = pNew_syms; pNew_syms = t;
+ }
+ return pCur_syms;
+}
+
+// calculate_minimum_redundancy() originally written by: Alistair Moffat, alistair@cs.mu.oz.au, Jyrki Katajainen, jyrki@diku.dk, November 1996.
+static void calculate_minimum_redundancy(sym_freq *A, int n)
+{
+ int root, leaf, next, avbl, used, dpth;
+ if (n==0) return; else if (n==1) { A[0].m_key = 1; return; }
+ A[0].m_key += A[1].m_key; root = 0; leaf = 2;
+ for (next=1; next < n-1; next++)
+ {
+ if (leaf>=n || A[root].m_key=n || (root=0; next--) A[next].m_key = A[A[next].m_key].m_key+1;
+ avbl = 1; used = dpth = 0; root = n-2; next = n-1;
+ while (avbl>0)
+ {
+ while (root>=0 && (int)A[root].m_key==dpth) { used++; root--; }
+ while (avbl>used) { A[next--].m_key = dpth; avbl--; }
+ avbl = 2*used; dpth++; used = 0;
+ }
+}
+
+// Limits canonical Huffman code table's max code size to max_code_size.
+static void huffman_enforce_max_code_size(int *pNum_codes, int code_list_len, int max_code_size)
+{
+ if (code_list_len <= 1) return;
+
+ for (int i = max_code_size + 1; i <= MAX_HUFF_CODESIZE; i++) pNum_codes[max_code_size] += pNum_codes[i];
+
+ uint32 total = 0;
+ for (int i = max_code_size; i > 0; i--)
+ total += (((uint32)pNum_codes[i]) << (max_code_size - i));
+
+ while (total != (1UL << max_code_size))
+ {
+ pNum_codes[max_code_size]--;
+ for (int i = max_code_size - 1; i > 0; i--)
+ {
+ if (pNum_codes[i]) { pNum_codes[i]--; pNum_codes[i + 1] += 2; break; }
+ }
+ total--;
+ }
+}
+
+// Generates an optimized offman table.
+void jpeg_encoder::optimize_huffman_table(int table_num, int table_len)
+{
+ sym_freq syms0[MAX_HUFF_SYMBOLS], syms1[MAX_HUFF_SYMBOLS];
+ syms0[0].m_key = 1; syms0[0].m_sym_index = 0; // dummy symbol, assures that no valid code contains all 1's
+ int num_used_syms = 1;
+ const uint32 *pSym_count = &m_huff_count[table_num][0];
+ for (int i = 0; i < table_len; i++)
+ if (pSym_count[i]) { syms0[num_used_syms].m_key = pSym_count[i]; syms0[num_used_syms++].m_sym_index = i + 1; }
+ sym_freq* pSyms = radix_sort_syms(num_used_syms, syms0, syms1);
+ calculate_minimum_redundancy(pSyms, num_used_syms);
+
+ // Count the # of symbols of each code size.
+ int num_codes[1 + MAX_HUFF_CODESIZE]; clear_obj(num_codes);
+ for (int i = 0; i < num_used_syms; i++)
+ num_codes[pSyms[i].m_key]++;
+
+ const uint JPGE_CODE_SIZE_LIMIT = 16; // the maximum possible size of a JPEG Huffman code (valid range is [9,16] - 9 vs. 8 because of the dummy symbol)
+ huffman_enforce_max_code_size(num_codes, num_used_syms, JPGE_CODE_SIZE_LIMIT);
+
+ // Compute m_huff_bits array, which contains the # of symbols per code size.
+ clear_obj(m_huff_bits[table_num]);
+ for (int i = 1; i <= (int)JPGE_CODE_SIZE_LIMIT; i++)
+ m_huff_bits[table_num][i] = static_cast(num_codes[i]);
+
+ // Remove the dummy symbol added above, which must be in largest bucket.
+ for (int i = JPGE_CODE_SIZE_LIMIT; i >= 1; i--)
+ {
+ if (m_huff_bits[table_num][i]) { m_huff_bits[table_num][i]--; break; }
+ }
+
+ // Compute the m_huff_val array, which contains the symbol indices sorted by code size (smallest to largest).
+ for (int i = num_used_syms - 1; i >= 1; i--)
+ m_huff_val[table_num][num_used_syms - 1 - i] = static_cast(pSyms[i].m_sym_index - 1);
+}
+
+// JPEG marker generation.
+void jpeg_encoder::emit_byte(uint8 i)
+{
+ m_all_stream_writes_succeeded = m_all_stream_writes_succeeded && m_pStream->put_obj(i);
+}
+
+void jpeg_encoder::emit_word(uint i)
+{
+ emit_byte(uint8(i >> 8)); emit_byte(uint8(i & 0xFF));
+}
+
+void jpeg_encoder::emit_marker(int marker)
+{
+ emit_byte(uint8(0xFF)); emit_byte(uint8(marker));
+}
+
+// Emit JFIF marker
+void jpeg_encoder::emit_jfif_app0()
+{
+ emit_marker(M_APP0);
+ emit_word(2 + 4 + 1 + 2 + 1 + 2 + 2 + 1 + 1);
+ emit_byte(0x4A); emit_byte(0x46); emit_byte(0x49); emit_byte(0x46); /* Identifier: ASCII "JFIF" */
+ emit_byte(0);
+ emit_byte(1); /* Major version */
+ emit_byte(1); /* Minor version */
+ emit_byte(0); /* Density unit */
+ emit_word(1);
+ emit_word(1);
+ emit_byte(0); /* No thumbnail image */
+ emit_byte(0);
+}
+
+// Emit quantization tables
+void jpeg_encoder::emit_dqt()
+{
+ for (int i = 0; i < ((m_num_components == 3) ? 2 : 1); i++)
+ {
+ emit_marker(M_DQT);
+ emit_word(64 + 1 + 2);
+ emit_byte(static_cast(i));
+ for (int j = 0; j < 64; j++)
+ emit_byte(static_cast(m_quantization_tables[i][j]));
+ }
+}
+
+// Emit start of frame marker
+void jpeg_encoder::emit_sof()
+{
+ emit_marker(M_SOF0); /* baseline */
+ emit_word(3 * m_num_components + 2 + 5 + 1);
+ emit_byte(8); /* precision */
+ emit_word(m_image_y);
+ emit_word(m_image_x);
+ emit_byte(m_num_components);
+ for (int i = 0; i < m_num_components; i++)
+ {
+ emit_byte(static_cast(i + 1)); /* component ID */
+ emit_byte((m_comp_h_samp[i] << 4) + m_comp_v_samp[i]); /* h and v sampling */
+ emit_byte(i > 0); /* quant. table num */
+ }
+}
+
+// Emit Huffman table.
+void jpeg_encoder::emit_dht(uint8 *bits, uint8 *val, int index, bool ac_flag)
+{
+ emit_marker(M_DHT);
+
+ int length = 0;
+ for (int i = 1; i <= 16; i++)
+ length += bits[i];
+
+ emit_word(length + 2 + 1 + 16);
+ emit_byte(static_cast(index + (ac_flag << 4)));
+
+ for (int i = 1; i <= 16; i++)
+ emit_byte(bits[i]);
+
+ for (int i = 0; i < length; i++)
+ emit_byte(val[i]);
+}
+
+// Emit all Huffman tables.
+void jpeg_encoder::emit_dhts()
+{
+ emit_dht(m_huff_bits[0+0], m_huff_val[0+0], 0, false);
+ emit_dht(m_huff_bits[2+0], m_huff_val[2+0], 0, true);
+ if (m_num_components == 3)
+ {
+ emit_dht(m_huff_bits[0+1], m_huff_val[0+1], 1, false);
+ emit_dht(m_huff_bits[2+1], m_huff_val[2+1], 1, true);
+ }
+}
+
+// emit start of scan
+void jpeg_encoder::emit_sos()
+{
+ emit_marker(M_SOS);
+ emit_word(2 * m_num_components + 2 + 1 + 3);
+ emit_byte(m_num_components);
+ for (int i = 0; i < m_num_components; i++)
+ {
+ emit_byte(static_cast(i + 1));
+ if (i == 0)
+ emit_byte((0 << 4) + 0);
+ else
+ emit_byte((1 << 4) + 1);
+ }
+ emit_byte(0); /* spectral selection */
+ emit_byte(63);
+ emit_byte(0);
+}
+
+// Emit all markers at beginning of image file.
+void jpeg_encoder::emit_markers()
+{
+ emit_marker(M_SOI);
+ emit_jfif_app0();
+ emit_dqt();
+ emit_sof();
+ emit_dhts();
+ emit_sos();
+}
+
+// Compute the actual canonical Huffman codes/code sizes given the JPEG huff bits and val arrays.
+void jpeg_encoder::compute_huffman_table(uint *codes, uint8 *code_sizes, uint8 *bits, uint8 *val)
+{
+ int i, l, last_p, si;
+ uint8 huff_size[257];
+ uint huff_code[257];
+ uint code;
+
+ int p = 0;
+ for (l = 1; l <= 16; l++)
+ for (i = 1; i <= bits[l]; i++)
+ huff_size[p++] = (char)l;
+
+ huff_size[p] = 0; last_p = p; // write sentinel
+
+ code = 0; si = huff_size[0]; p = 0;
+
+ while (huff_size[p])
+ {
+ while (huff_size[p] == si)
+ huff_code[p++] = code++;
+ code <<= 1;
+ si++;
+ }
+
+ memset(codes, 0, sizeof(codes[0])*256);
+ memset(code_sizes, 0, sizeof(code_sizes[0])*256);
+ for (p = 0; p < last_p; p++)
+ {
+ codes[val[p]] = huff_code[p];
+ code_sizes[val[p]] = huff_size[p];
+ }
+}
+
+// Quantization table generation.
+void jpeg_encoder::compute_quant_table(int32 *pDst, int16 *pSrc)
+{
+ int32 q;
+ if (m_params.m_quality < 50)
+ q = 5000 / m_params.m_quality;
+ else
+ q = 200 - m_params.m_quality * 2;
+ for (int i = 0; i < 64; i++)
+ {
+ int32 j = *pSrc++; j = (j * q + 50L) / 100L;
+ *pDst++ = JPGE_MIN(JPGE_MAX(j, 1), 255);
+ }
+}
+
+// Higher-level methods.
+void jpeg_encoder::first_pass_init()
+{
+ m_bit_buffer = 0; m_bits_in = 0;
+ memset(m_last_dc_val, 0, 3 * sizeof(m_last_dc_val[0]));
+ m_mcu_y_ofs = 0;
+ m_pass_num = 1;
+}
+
+bool jpeg_encoder::second_pass_init()
+{
+ compute_huffman_table(&m_huff_codes[0+0][0], &m_huff_code_sizes[0+0][0], m_huff_bits[0+0], m_huff_val[0+0]);
+ compute_huffman_table(&m_huff_codes[2+0][0], &m_huff_code_sizes[2+0][0], m_huff_bits[2+0], m_huff_val[2+0]);
+ if (m_num_components > 1)
+ {
+ compute_huffman_table(&m_huff_codes[0+1][0], &m_huff_code_sizes[0+1][0], m_huff_bits[0+1], m_huff_val[0+1]);
+ compute_huffman_table(&m_huff_codes[2+1][0], &m_huff_code_sizes[2+1][0], m_huff_bits[2+1], m_huff_val[2+1]);
+ }
+ first_pass_init();
+ emit_markers();
+ m_pass_num = 2;
+ return true;
+}
+
+bool jpeg_encoder::jpg_open(int p_x_res, int p_y_res, int src_channels)
+{
+ m_num_components = 3;
+ switch (m_params.m_subsampling)
+ {
+ case Y_ONLY:
+ {
+ m_num_components = 1;
+ m_comp_h_samp[0] = 1; m_comp_v_samp[0] = 1;
+ m_mcu_x = 8; m_mcu_y = 8;
+ break;
+ }
+ case H1V1:
+ {
+ m_comp_h_samp[0] = 1; m_comp_v_samp[0] = 1;
+ m_comp_h_samp[1] = 1; m_comp_v_samp[1] = 1;
+ m_comp_h_samp[2] = 1; m_comp_v_samp[2] = 1;
+ m_mcu_x = 8; m_mcu_y = 8;
+ break;
+ }
+ case H2V1:
+ {
+ m_comp_h_samp[0] = 2; m_comp_v_samp[0] = 1;
+ m_comp_h_samp[1] = 1; m_comp_v_samp[1] = 1;
+ m_comp_h_samp[2] = 1; m_comp_v_samp[2] = 1;
+ m_mcu_x = 16; m_mcu_y = 8;
+ break;
+ }
+ case H2V2:
+ {
+ m_comp_h_samp[0] = 2; m_comp_v_samp[0] = 2;
+ m_comp_h_samp[1] = 1; m_comp_v_samp[1] = 1;
+ m_comp_h_samp[2] = 1; m_comp_v_samp[2] = 1;
+ m_mcu_x = 16; m_mcu_y = 16;
+ }
+ }
+
+ m_image_x = p_x_res; m_image_y = p_y_res;
+ m_image_bpp = src_channels;
+ m_image_bpl = m_image_x * src_channels;
+ m_image_x_mcu = (m_image_x + m_mcu_x - 1) & (~(m_mcu_x - 1));
+ m_image_y_mcu = (m_image_y + m_mcu_y - 1) & (~(m_mcu_y - 1));
+ m_image_bpl_xlt = m_image_x * m_num_components;
+ m_image_bpl_mcu = m_image_x_mcu * m_num_components;
+ m_mcus_per_row = m_image_x_mcu / m_mcu_x;
+
+ if ((m_mcu_lines[0] = static_cast(jpge_malloc(m_image_bpl_mcu * m_mcu_y))) == NULL) return false;
+ for (int i = 1; i < m_mcu_y; i++)
+ m_mcu_lines[i] = m_mcu_lines[i-1] + m_image_bpl_mcu;
+
+ compute_quant_table(m_quantization_tables[0], s_std_lum_quant);
+ compute_quant_table(m_quantization_tables[1], m_params.m_no_chroma_discrim_flag ? s_std_lum_quant : s_std_croma_quant);
+
+ m_out_buf_left = JPGE_OUT_BUF_SIZE;
+ m_pOut_buf = m_out_buf;
+
+ if (m_params.m_two_pass_flag)
+ {
+ clear_obj(m_huff_count);
+ first_pass_init();
+ }
+ else
+ {
+ memcpy(m_huff_bits[0+0], s_dc_lum_bits, 17); memcpy(m_huff_val [0+0], s_dc_lum_val, DC_LUM_CODES);
+ memcpy(m_huff_bits[2+0], s_ac_lum_bits, 17); memcpy(m_huff_val [2+0], s_ac_lum_val, AC_LUM_CODES);
+ memcpy(m_huff_bits[0+1], s_dc_chroma_bits, 17); memcpy(m_huff_val [0+1], s_dc_chroma_val, DC_CHROMA_CODES);
+ memcpy(m_huff_bits[2+1], s_ac_chroma_bits, 17); memcpy(m_huff_val [2+1], s_ac_chroma_val, AC_CHROMA_CODES);
+ if (!second_pass_init()) return false; // in effect, skip over the first pass
+ }
+ return m_all_stream_writes_succeeded;
+}
+
+void jpeg_encoder::load_block_8_8_grey(int x)
+{
+ uint8 *pSrc;
+ sample_array_t *pDst = m_sample_array;
+ x <<= 3;
+ for (int i = 0; i < 8; i++, pDst += 8)
+ {
+ pSrc = m_mcu_lines[i] + x;
+ pDst[0] = pSrc[0] - 128; pDst[1] = pSrc[1] - 128; pDst[2] = pSrc[2] - 128; pDst[3] = pSrc[3] - 128;
+ pDst[4] = pSrc[4] - 128; pDst[5] = pSrc[5] - 128; pDst[6] = pSrc[6] - 128; pDst[7] = pSrc[7] - 128;
+ }
+}
+
+void jpeg_encoder::load_block_8_8(int x, int y, int c)
+{
+ uint8 *pSrc;
+ sample_array_t *pDst = m_sample_array;
+ x = (x * (8 * 3)) + c;
+ y <<= 3;
+ for (int i = 0; i < 8; i++, pDst += 8)
+ {
+ pSrc = m_mcu_lines[y + i] + x;
+ pDst[0] = pSrc[0 * 3] - 128; pDst[1] = pSrc[1 * 3] - 128; pDst[2] = pSrc[2 * 3] - 128; pDst[3] = pSrc[3 * 3] - 128;
+ pDst[4] = pSrc[4 * 3] - 128; pDst[5] = pSrc[5 * 3] - 128; pDst[6] = pSrc[6 * 3] - 128; pDst[7] = pSrc[7 * 3] - 128;
+ }
+}
+
+void jpeg_encoder::load_block_16_8(int x, int c)
+{
+ uint8 *pSrc1, *pSrc2;
+ sample_array_t *pDst = m_sample_array;
+ x = (x * (16 * 3)) + c;
+ int a = 0, b = 2;
+ for (int i = 0; i < 16; i += 2, pDst += 8)
+ {
+ pSrc1 = m_mcu_lines[i + 0] + x;
+ pSrc2 = m_mcu_lines[i + 1] + x;
+ pDst[0] = ((pSrc1[ 0 * 3] + pSrc1[ 1 * 3] + pSrc2[ 0 * 3] + pSrc2[ 1 * 3] + a) >> 2) - 128; pDst[1] = ((pSrc1[ 2 * 3] + pSrc1[ 3 * 3] + pSrc2[ 2 * 3] + pSrc2[ 3 * 3] + b) >> 2) - 128;
+ pDst[2] = ((pSrc1[ 4 * 3] + pSrc1[ 5 * 3] + pSrc2[ 4 * 3] + pSrc2[ 5 * 3] + a) >> 2) - 128; pDst[3] = ((pSrc1[ 6 * 3] + pSrc1[ 7 * 3] + pSrc2[ 6 * 3] + pSrc2[ 7 * 3] + b) >> 2) - 128;
+ pDst[4] = ((pSrc1[ 8 * 3] + pSrc1[ 9 * 3] + pSrc2[ 8 * 3] + pSrc2[ 9 * 3] + a) >> 2) - 128; pDst[5] = ((pSrc1[10 * 3] + pSrc1[11 * 3] + pSrc2[10 * 3] + pSrc2[11 * 3] + b) >> 2) - 128;
+ pDst[6] = ((pSrc1[12 * 3] + pSrc1[13 * 3] + pSrc2[12 * 3] + pSrc2[13 * 3] + a) >> 2) - 128; pDst[7] = ((pSrc1[14 * 3] + pSrc1[15 * 3] + pSrc2[14 * 3] + pSrc2[15 * 3] + b) >> 2) - 128;
+ int temp = a; a = b; b = temp;
+ }
+}
+
+void jpeg_encoder::load_block_16_8_8(int x, int c)
+{
+ uint8 *pSrc1;
+ sample_array_t *pDst = m_sample_array;
+ x = (x * (16 * 3)) + c;
+ for (int i = 0; i < 8; i++, pDst += 8)
+ {
+ pSrc1 = m_mcu_lines[i + 0] + x;
+ pDst[0] = ((pSrc1[ 0 * 3] + pSrc1[ 1 * 3]) >> 1) - 128; pDst[1] = ((pSrc1[ 2 * 3] + pSrc1[ 3 * 3]) >> 1) - 128;
+ pDst[2] = ((pSrc1[ 4 * 3] + pSrc1[ 5 * 3]) >> 1) - 128; pDst[3] = ((pSrc1[ 6 * 3] + pSrc1[ 7 * 3]) >> 1) - 128;
+ pDst[4] = ((pSrc1[ 8 * 3] + pSrc1[ 9 * 3]) >> 1) - 128; pDst[5] = ((pSrc1[10 * 3] + pSrc1[11 * 3]) >> 1) - 128;
+ pDst[6] = ((pSrc1[12 * 3] + pSrc1[13 * 3]) >> 1) - 128; pDst[7] = ((pSrc1[14 * 3] + pSrc1[15 * 3]) >> 1) - 128;
+ }
+}
+
+void jpeg_encoder::load_quantized_coefficients(int component_num)
+{
+ int32 *q = m_quantization_tables[component_num > 0];
+ int16 *pDst = m_coefficient_array;
+ for (int i = 0; i < 64; i++)
+ {
+ sample_array_t j = m_sample_array[s_zag[i]];
+ if (j < 0)
+ {
+ if ((j = -j + (*q >> 1)) < *q)
+ *pDst++ = 0;
+ else
+ *pDst++ = static_cast(-(j / *q));
+ }
+ else
+ {
+ if ((j = j + (*q >> 1)) < *q)
+ *pDst++ = 0;
+ else
+ *pDst++ = static_cast((j / *q));
+ }
+ q++;
+ }
+}
+
+void jpeg_encoder::flush_output_buffer()
+{
+ if (m_out_buf_left != JPGE_OUT_BUF_SIZE)
+ m_all_stream_writes_succeeded = m_all_stream_writes_succeeded && m_pStream->put_buf(m_out_buf, JPGE_OUT_BUF_SIZE - m_out_buf_left);
+ m_pOut_buf = m_out_buf;
+ m_out_buf_left = JPGE_OUT_BUF_SIZE;
+}
+
+void jpeg_encoder::put_bits(uint bits, uint len)
+{
+ m_bit_buffer |= ((uint32)bits << (24 - (m_bits_in += len)));
+ while (m_bits_in >= 8)
+ {
+ uint8 c;
+ #define JPGE_PUT_BYTE(c) { *m_pOut_buf++ = (c); if (--m_out_buf_left == 0) flush_output_buffer(); }
+ JPGE_PUT_BYTE(c = (uint8)((m_bit_buffer >> 16) & 0xFF));
+ if (c == 0xFF) JPGE_PUT_BYTE(0);
+ m_bit_buffer <<= 8;
+ m_bits_in -= 8;
+ }
+}
+
+void jpeg_encoder::code_coefficients_pass_one(int component_num)
+{
+ if (component_num >= 3) return; // just to shut up static analysis
+ int i, run_len, nbits, temp1;
+ int16 *src = m_coefficient_array;
+ uint32 *dc_count = component_num ? m_huff_count[0 + 1] : m_huff_count[0 + 0], *ac_count = component_num ? m_huff_count[2 + 1] : m_huff_count[2 + 0];
+
+ temp1 = src[0] - m_last_dc_val[component_num];
+ m_last_dc_val[component_num] = src[0];
+ if (temp1 < 0) temp1 = -temp1;
+
+ nbits = 0;
+ while (temp1)
+ {
+ nbits++; temp1 >>= 1;
+ }
+
+ dc_count[nbits]++;
+ for (run_len = 0, i = 1; i < 64; i++)
+ {
+ if ((temp1 = m_coefficient_array[i]) == 0)
+ run_len++;
+ else
+ {
+ while (run_len >= 16)
+ {
+ ac_count[0xF0]++;
+ run_len -= 16;
+ }
+ if (temp1 < 0) temp1 = -temp1;
+ nbits = 1;
+ while (temp1 >>= 1) nbits++;
+ ac_count[(run_len << 4) + nbits]++;
+ run_len = 0;
+ }
+ }
+ if (run_len) ac_count[0]++;
+}
+
+void jpeg_encoder::code_coefficients_pass_two(int component_num)
+{
+ int i, j, run_len, nbits, temp1, temp2;
+ int16 *pSrc = m_coefficient_array;
+ uint *codes[2];
+ uint8 *code_sizes[2];
+
+ if (component_num == 0)
+ {
+ codes[0] = m_huff_codes[0 + 0]; codes[1] = m_huff_codes[2 + 0];
+ code_sizes[0] = m_huff_code_sizes[0 + 0]; code_sizes[1] = m_huff_code_sizes[2 + 0];
+ }
+ else
+ {
+ codes[0] = m_huff_codes[0 + 1]; codes[1] = m_huff_codes[2 + 1];
+ code_sizes[0] = m_huff_code_sizes[0 + 1]; code_sizes[1] = m_huff_code_sizes[2 + 1];
+ }
+
+ temp1 = temp2 = pSrc[0] - m_last_dc_val[component_num];
+ m_last_dc_val[component_num] = pSrc[0];
+
+ if (temp1 < 0)
+ {
+ temp1 = -temp1; temp2--;
+ }
+
+ nbits = 0;
+ while (temp1)
+ {
+ nbits++; temp1 >>= 1;
+ }
+
+ put_bits(codes[0][nbits], code_sizes[0][nbits]);
+ if (nbits) put_bits(temp2 & ((1 << nbits) - 1), nbits);
+
+ for (run_len = 0, i = 1; i < 64; i++)
+ {
+ if ((temp1 = m_coefficient_array[i]) == 0)
+ run_len++;
+ else
+ {
+ while (run_len >= 16)
+ {
+ put_bits(codes[1][0xF0], code_sizes[1][0xF0]);
+ run_len -= 16;
+ }
+ if ((temp2 = temp1) < 0)
+ {
+ temp1 = -temp1;
+ temp2--;
+ }
+ nbits = 1;
+ while (temp1 >>= 1)
+ nbits++;
+ j = (run_len << 4) + nbits;
+ put_bits(codes[1][j], code_sizes[1][j]);
+ put_bits(temp2 & ((1 << nbits) - 1), nbits);
+ run_len = 0;
+ }
+ }
+ if (run_len)
+ put_bits(codes[1][0], code_sizes[1][0]);
+}
+
+void jpeg_encoder::code_block(int component_num)
+{
+ DCT2D(m_sample_array);
+ load_quantized_coefficients(component_num);
+ if (m_pass_num == 1)
+ code_coefficients_pass_one(component_num);
+ else
+ code_coefficients_pass_two(component_num);
+}
+
+void jpeg_encoder::process_mcu_row()
+{
+ if (m_num_components == 1)
+ {
+ for (int i = 0; i < m_mcus_per_row; i++)
+ {
+ load_block_8_8_grey(i); code_block(0);
+ }
+ }
+ else if ((m_comp_h_samp[0] == 1) && (m_comp_v_samp[0] == 1))
+ {
+ for (int i = 0; i < m_mcus_per_row; i++)
+ {
+ load_block_8_8(i, 0, 0); code_block(0); load_block_8_8(i, 0, 1); code_block(1); load_block_8_8(i, 0, 2); code_block(2);
+ }
+ }
+ else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 1))
+ {
+ for (int i = 0; i < m_mcus_per_row; i++)
+ {
+ load_block_8_8(i * 2 + 0, 0, 0); code_block(0); load_block_8_8(i * 2 + 1, 0, 0); code_block(0);
+ load_block_16_8_8(i, 1); code_block(1); load_block_16_8_8(i, 2); code_block(2);
+ }
+ }
+ else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 2))
+ {
+ for (int i = 0; i < m_mcus_per_row; i++)
+ {
+ load_block_8_8(i * 2 + 0, 0, 0); code_block(0); load_block_8_8(i * 2 + 1, 0, 0); code_block(0);
+ load_block_8_8(i * 2 + 0, 1, 0); code_block(0); load_block_8_8(i * 2 + 1, 1, 0); code_block(0);
+ load_block_16_8(i, 1); code_block(1); load_block_16_8(i, 2); code_block(2);
+ }
+ }
+}
+
+bool jpeg_encoder::terminate_pass_one()
+{
+ optimize_huffman_table(0+0, DC_LUM_CODES); optimize_huffman_table(2+0, AC_LUM_CODES);
+ if (m_num_components > 1)
+ {
+ optimize_huffman_table(0+1, DC_CHROMA_CODES); optimize_huffman_table(2+1, AC_CHROMA_CODES);
+ }
+ return second_pass_init();
+}
+
+bool jpeg_encoder::terminate_pass_two()
+{
+ put_bits(0x7F, 7);
+ flush_output_buffer();
+ emit_marker(M_EOI);
+ m_pass_num++; // purposely bump up m_pass_num, for debugging
+ return true;
+}
+
+bool jpeg_encoder::process_end_of_image()
+{
+ if (m_mcu_y_ofs)
+ {
+ if (m_mcu_y_ofs < 16) // check here just to shut up static analysis
+ {
+ for (int i = m_mcu_y_ofs; i < m_mcu_y; i++)
+ memcpy(m_mcu_lines[i], m_mcu_lines[m_mcu_y_ofs - 1], m_image_bpl_mcu);
+ }
+
+ process_mcu_row();
+ }
+
+ if (m_pass_num == 1)
+ return terminate_pass_one();
+ else
+ return terminate_pass_two();
+}
+
+void jpeg_encoder::load_mcu(const void *pSrc)
+{
+ const uint8* Psrc = reinterpret_cast(pSrc);
+
+ uint8* pDst = m_mcu_lines[m_mcu_y_ofs]; // OK to write up to m_image_bpl_xlt bytes to pDst
+
+ if (m_num_components == 1)
+ {
+ if (m_image_bpp == 4)
+ RGBA_to_Y(pDst, Psrc, m_image_x);
+ else if (m_image_bpp == 3)
+ RGB_to_Y(pDst, Psrc, m_image_x);
+ else
+ memcpy(pDst, Psrc, m_image_x);
+ }
+ else
+ {
+ if (m_image_bpp == 4)
+ RGBA_to_YCC(pDst, Psrc, m_image_x);
+ else if (m_image_bpp == 3)
+ RGB_to_YCC(pDst, Psrc, m_image_x);
+ else
+ Y_to_YCC(pDst, Psrc, m_image_x);
+ }
+
+ // Possibly duplicate pixels at end of scanline if not a multiple of 8 or 16
+ if (m_num_components == 1)
+ memset(m_mcu_lines[m_mcu_y_ofs] + m_image_bpl_xlt, pDst[m_image_bpl_xlt - 1], m_image_x_mcu - m_image_x);
+ else
+ {
+ const uint8 y = pDst[m_image_bpl_xlt - 3 + 0], cb = pDst[m_image_bpl_xlt - 3 + 1], cr = pDst[m_image_bpl_xlt - 3 + 2];
+ uint8 *q = m_mcu_lines[m_mcu_y_ofs] + m_image_bpl_xlt;
+ for (int i = m_image_x; i < m_image_x_mcu; i++)
+ {
+ *q++ = y; *q++ = cb; *q++ = cr;
+ }
+ }
+
+ if (++m_mcu_y_ofs == m_mcu_y)
+ {
+ process_mcu_row();
+ m_mcu_y_ofs = 0;
+ }
+}
+
+void jpeg_encoder::clear()
+{
+ m_mcu_lines[0] = NULL;
+ m_pass_num = 0;
+ m_all_stream_writes_succeeded = true;
+}
+
+jpeg_encoder::jpeg_encoder()
+{
+ clear();
+}
+
+jpeg_encoder::~jpeg_encoder()
+{
+ deinit();
+}
+
+bool jpeg_encoder::init(output_stream *pStream, int64_t width, int64_t height, int64_t src_channels, const params &comp_params)
+{
+ deinit();
+ if (((!pStream) || (width < 1) || (height < 1)) || ((src_channels != 1) && (src_channels != 3) && (src_channels != 4)) || (!comp_params.check_valid())) return false;
+ m_pStream = pStream;
+ m_params = comp_params;
+ return jpg_open(width, height, src_channels);
+}
+
+void jpeg_encoder::deinit()
+{
+ jpge_free(m_mcu_lines[0]);
+ clear();
+}
+
+bool jpeg_encoder::process_scanline(const void* pScanline)
+{
+ if ((m_pass_num < 1) || (m_pass_num > 2)) return false;
+ if (m_all_stream_writes_succeeded)
+ {
+ if (!pScanline)
+ {
+ if (!process_end_of_image()) return false;
+ }
+ else
+ {
+ load_mcu(pScanline);
+ }
+ }
+ return m_all_stream_writes_succeeded;
+}
+
+// Higher level wrappers/examples (optional).
+#include
+
+class cfile_stream : public output_stream
+{
+ cfile_stream(const cfile_stream &);
+ cfile_stream &operator= (const cfile_stream &);
+
+ FILE* m_pFile;
+ bool m_bStatus;
+
+public:
+ cfile_stream() : m_pFile(NULL), m_bStatus(false) { }
+
+ virtual ~cfile_stream()
+ {
+ close();
+ }
+
+ bool open(const char *pFilename)
+ {
+ close();
+#if defined(_MSC_VER)
+ if (fopen_s(&m_pFile, pFilename, "wb") != 0)
+ {
+ return false;
+ }
+#else
+ m_pFile = fopen(pFilename, "wb");
+#endif
+ m_bStatus = (m_pFile != NULL);
+ return m_bStatus;
+ }
+
+ bool close()
+ {
+ if (m_pFile)
+ {
+ if (fclose(m_pFile) == EOF)
+ {
+ m_bStatus = false;
+ }
+ m_pFile = NULL;
+ }
+ return m_bStatus;
+ }
+
+ virtual bool put_buf(const void* pBuf, int64_t len)
+ {
+ m_bStatus = m_bStatus && (fwrite(pBuf, len, 1, m_pFile) == 1);
+ return m_bStatus;
+ }
+
+ uint get_size() const
+ {
+ return m_pFile ? ftell(m_pFile) : 0;
+ }
+};
+
+// Writes JPEG image to file.
+bool compress_image_to_jpeg_file(const char *pFilename, int64_t width, int64_t height, int64_t num_channels, const uint8 *pImage_data, const params &comp_params)
+{
+ cfile_stream dst_stream;
+ if (!dst_stream.open(pFilename))
+ return false;
+
+ jpge::jpeg_encoder dst_image;
+ if (!dst_image.init(&dst_stream, width, height, num_channels, comp_params))
+ return false;
+
+ for (uint pass_index = 0; pass_index < dst_image.get_total_passes(); pass_index++)
+ {
+ for (int64_t i = 0; i < height; i++)
+ {
+ // i, width, and num_channels are all 64bit
+ const uint8* pBuf = pImage_data + i * width * num_channels;
+ if (!dst_image.process_scanline(pBuf))
+ return false;
+ }
+ if (!dst_image.process_scanline(NULL))
+ return false;
+ }
+
+ dst_image.deinit();
+
+ return dst_stream.close();
+}
+
+class memory_stream : public output_stream
+{
+ memory_stream(const memory_stream &);
+ memory_stream &operator= (const memory_stream &);
+
+ uint8 *m_pBuf;
+ uint64_t m_buf_size, m_buf_ofs;
+
+public:
+ memory_stream(void *pBuf, uint64_t buf_size) : m_pBuf(static_cast(pBuf)), m_buf_size(buf_size), m_buf_ofs(0) { }
+
+ virtual ~memory_stream() { }
+
+ virtual bool put_buf(const void* pBuf, int64_t len)
+ {
+ uint64_t buf_remaining = m_buf_size - m_buf_ofs;
+ if ((uint64_t)len > buf_remaining)
+ return false;
+ memcpy(m_pBuf + m_buf_ofs, pBuf, len);
+ m_buf_ofs += len;
+ return true;
+ }
+
+ uint64_t get_size() const
+ {
+ return m_buf_ofs;
+ }
+};
+
+bool compress_image_to_jpeg_file_in_memory(void *pDstBuf, int64_t &buf_size, int64_t width, int64_t height, int64_t num_channels, const uint8 *pImage_data, const params &comp_params)
+{
+ if ((!pDstBuf) || (!buf_size))
+ return false;
+
+ memory_stream dst_stream(pDstBuf, buf_size);
+
+ buf_size = 0;
+
+ jpge::jpeg_encoder dst_image;
+ if (!dst_image.init(&dst_stream, width, height, num_channels, comp_params))
+ return false;
+
+ for (uint pass_index = 0; pass_index < dst_image.get_total_passes(); pass_index++)
+ {
+ for (int64_t i = 0; i < height; i++)
+ {
+ const uint8* pScanline = pImage_data + i * width * num_channels;
+ if (!dst_image.process_scanline(pScanline))
+ return false;
+ }
+ if (!dst_image.process_scanline(NULL))
+ return false;
+ }
+
+ dst_image.deinit();
+
+ buf_size = dst_stream.get_size();
+ return true;
+}
+
+} // namespace jpge
\ No newline at end of file
diff --git a/crazy_functions/test_project/cpp/longcode/prod_cons.h b/crazy_functions/test_project/cpp/longcode/prod_cons.h
new file mode 100644
index 0000000..28d99bd
--- /dev/null
+++ b/crazy_functions/test_project/cpp/longcode/prod_cons.h
@@ -0,0 +1,433 @@
+#pragma once
+
+#include
+#include
+#include
+#include
+#include
+
+#include "libipc/def.h"
+
+#include "libipc/platform/detail.h"
+#include "libipc/circ/elem_def.h"
+#include "libipc/utility/log.h"
+#include "libipc/utility/utility.h"
+
+namespace ipc {
+
+////////////////////////////////////////////////////////////////
+/// producer-consumer implementation
+////////////////////////////////////////////////////////////////
+
+template
+struct prod_cons_impl;
+
+template <>
+struct prod_cons_impl> {
+
+ template
+ struct elem_t {
+ std::aligned_storage_t data_ {};
+ };
+
+ alignas(cache_line_size) std::atomic rd_; // read index
+ alignas(cache_line_size) std::atomic wt_; // write index
+
+ constexpr circ::u2_t cursor() const noexcept {
+ return 0;
+ }
+
+ template
+ bool push(W* /*wrapper*/, F&& f, E* elems) {
+ auto cur_wt = circ::index_of(wt_.load(std::memory_order_relaxed));
+ if (cur_wt == circ::index_of(rd_.load(std::memory_order_acquire) - 1)) {
+ return false; // full
+ }
+ std::forward(f)(&(elems[cur_wt].data_));
+ wt_.fetch_add(1, std::memory_order_release);
+ return true;
+ }
+
+ /**
+ * In single-single-unicast, 'force_push' means 'no reader' or 'the only one reader is dead'.
+ * So we could just disconnect all connections of receiver, and return false.
+ */
+ template
+ bool force_push(W* wrapper, F&&, E*) {
+ wrapper->elems()->disconnect_receiver(~static_cast(0u));
+ return false;
+ }
+
+ template
+ bool pop(W* /*wrapper*/, circ::u2_t& /*cur*/, F&& f, R&& out, E* elems) {
+ auto cur_rd = circ::index_of(rd_.load(std::memory_order_relaxed));
+ if (cur_rd == circ::index_of(wt_.load(std::memory_order_acquire))) {
+ return false; // empty
+ }
+ std::forward(f)(&(elems[cur_rd].data_));
+ std::forward(out)(true);
+ rd_.fetch_add(1, std::memory_order_release);
+ return true;
+ }
+};
+
+template <>
+struct prod_cons_impl>
+ : prod_cons_impl> {
+
+ template
+ bool force_push(W* wrapper, F&&, E*) {
+ wrapper->elems()->disconnect_receiver(1);
+ return false;
+ }
+
+ template class E, std::size_t DS, std::size_t AS>
+ bool pop(W* /*wrapper*/, circ::u2_t& /*cur*/, F&& f, R&& out, E* elems) {
+ byte_t buff[DS];
+ for (unsigned k = 0;;) {
+ auto cur_rd = rd_.load(std::memory_order_relaxed);
+ if (circ::index_of(cur_rd) ==
+ circ::index_of(wt_.load(std::memory_order_acquire))) {
+ return false; // empty
+ }
+ std::memcpy(buff, &(elems[circ::index_of(cur_rd)].data_), sizeof(buff));
+ if (rd_.compare_exchange_weak(cur_rd, cur_rd + 1, std::memory_order_release)) {
+ std::forward(f)(buff);
+ std::forward(out)(true);
+ return true;
+ }
+ ipc::yield(k);
+ }
+ }
+};
+
+template <>
+struct prod_cons_impl>
+ : prod_cons_impl> {
+
+ using flag_t = std::uint64_t;
+
+ template
+ struct elem_t {
+ std::aligned_storage_t data_ {};
+ std::atomic f_ct_ { 0 }; // commit flag
+ };
+
+ alignas(cache_line_size) std::atomic ct_; // commit index
+
+ template
+ bool push(W* /*wrapper*/, F&& f, E* elems) {
+ circ::u2_t cur_ct, nxt_ct;
+ for (unsigned k = 0;;) {
+ cur_ct = ct_.load(std::memory_order_relaxed);
+ if (circ::index_of(nxt_ct = cur_ct + 1) ==
+ circ::index_of(rd_.load(std::memory_order_acquire))) {
+ return false; // full
+ }
+ if (ct_.compare_exchange_weak(cur_ct, nxt_ct, std::memory_order_acq_rel)) {
+ break;
+ }
+ ipc::yield(k);
+ }
+ auto* el = elems + circ::index_of(cur_ct);
+ std::forward(f)(&(el->data_));
+ // set flag & try update wt
+ el->f_ct_.store(~static_cast(cur_ct), std::memory_order_release);
+ while (1) {
+ auto cac_ct = el->f_ct_.load(std::memory_order_acquire);
+ if (cur_ct != wt_.load(std::memory_order_relaxed)) {
+ return true;
+ }
+ if ((~cac_ct) != cur_ct) {
+ return true;
+ }
+ if (!el->f_ct_.compare_exchange_strong(cac_ct, 0, std::memory_order_relaxed)) {
+ return true;
+ }
+ wt_.store(nxt_ct, std::memory_order_release);
+ cur_ct = nxt_ct;
+ nxt_ct = cur_ct + 1;
+ el = elems + circ::index_of(cur_ct);
+ }
+ return true;
+ }
+
+ template
+ bool force_push(W* wrapper, F&&, E*) {
+ wrapper->elems()->disconnect_receiver(1);
+ return false;
+ }
+
+ template class E, std::size_t DS, std::size_t AS>
+ bool pop(W* /*wrapper*/, circ::u2_t& /*cur*/, F&& f, R&& out, E* elems) {
+ byte_t buff[DS];
+ for (unsigned k = 0;;) {
+ auto cur_rd = rd_.load(std::memory_order_relaxed);
+ auto cur_wt = wt_.load(std::memory_order_acquire);
+ auto id_rd = circ::index_of(cur_rd);
+ auto id_wt = circ::index_of(cur_wt);
+ if (id_rd == id_wt) {
+ auto* el = elems + id_wt;
+ auto cac_ct = el->f_ct_.load(std::memory_order_acquire);
+ if ((~cac_ct) != cur_wt) {
+ return false; // empty
+ }
+ if (el->f_ct_.compare_exchange_weak(cac_ct, 0, std::memory_order_relaxed)) {
+ wt_.store(cur_wt + 1, std::memory_order_release);
+ }
+ k = 0;
+ }
+ else {
+ std::memcpy(buff, &(elems[circ::index_of(cur_rd)].data_), sizeof(buff));
+ if (rd_.compare_exchange_weak(cur_rd, cur_rd + 1, std::memory_order_release)) {
+ std::forward(f)(buff);
+ std::forward(out)(true);
+ return true;
+ }
+ ipc::yield(k);
+ }
+ }
+ }
+};
+
+template <>
+struct prod_cons_impl> {
+
+ using rc_t = std::uint64_t;
+
+ enum : rc_t {
+ ep_mask = 0x00000000ffffffffull,
+ ep_incr = 0x0000000100000000ull
+ };
+
+ template
+ struct elem_t {
+ std::aligned_storage_t data_ {};
+ std::atomic rc_ { 0 }; // read-counter
+ };
+
+ alignas(cache_line_size) std::atomic wt_; // write index
+ alignas(cache_line_size) rc_t epoch_ { 0 }; // only one writer
+
+ circ::u2_t cursor() const noexcept {
+ return wt_.load(std::memory_order_acquire);
+ }
+
+ template
+ bool push(W* wrapper, F&& f, E* elems) {
+ E* el;
+ for (unsigned k = 0;;) {
+ circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
+ if (cc == 0) return false; // no reader
+ el = elems + circ::index_of(wt_.load(std::memory_order_relaxed));
+ // check all consumers have finished reading this element
+ auto cur_rc = el->rc_.load(std::memory_order_acquire);
+ circ::cc_t rem_cc = cur_rc & ep_mask;
+ if ((cc & rem_cc) && ((cur_rc & ~ep_mask) == epoch_)) {
+ return false; // has not finished yet
+ }
+ // consider rem_cc to be 0 here
+ if (el->rc_.compare_exchange_weak(
+ cur_rc, epoch_ | static_cast(cc), std::memory_order_release)) {
+ break;
+ }
+ ipc::yield(k);
+ }
+ std::forward(f)(&(el->data_));
+ wt_.fetch_add(1, std::memory_order_release);
+ return true;
+ }
+
+ template
+ bool force_push(W* wrapper, F&& f, E* elems) {
+ E* el;
+ epoch_ += ep_incr;
+ for (unsigned k = 0;;) {
+ circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
+ if (cc == 0) return false; // no reader
+ el = elems + circ::index_of(wt_.load(std::memory_order_relaxed));
+ // check all consumers have finished reading this element
+ auto cur_rc = el->rc_.load(std::memory_order_acquire);
+ circ::cc_t rem_cc = cur_rc & ep_mask;
+ if (cc & rem_cc) {
+ ipc::log("force_push: k = %u, cc = %u, rem_cc = %u\n", k, cc, rem_cc);
+ cc = wrapper->elems()->disconnect_receiver(rem_cc); // disconnect all invalid readers
+ if (cc == 0) return false; // no reader
+ }
+ // just compare & exchange
+ if (el->rc_.compare_exchange_weak(
+ cur_rc, epoch_ | static_cast(cc), std::memory_order_release)) {
+ break;
+ }
+ ipc::yield(k);
+ }
+ std::forward(f)(&(el->data_));
+ wt_.fetch_add(1, std::memory_order_release);
+ return true;
+ }
+
+ template
+ bool pop(W* wrapper, circ::u2_t& cur, F&& f, R&& out, E* elems) {
+ if (cur == cursor()) return false; // acquire
+ auto* el = elems + circ::index_of(cur++);
+ std::forward(f)(&(el->data_));
+ for (unsigned k = 0;;) {
+ auto cur_rc = el->rc_.load(std::memory_order_acquire);
+ if ((cur_rc & ep_mask) == 0) {
+ std::forward(out)(true);
+ return true;
+ }
+ auto nxt_rc = cur_rc & ~static_cast(wrapper->connected_id());
+ if (el->rc_.compare_exchange_weak(cur_rc, nxt_rc, std::memory_order_release)) {
+ std::forward(out)((nxt_rc & ep_mask) == 0);
+ return true;
+ }
+ ipc::yield(k);
+ }
+ }
+};
+
+template <>
+struct prod_cons_impl> {
+
+ using rc_t = std::uint64_t;
+ using flag_t = std::uint64_t;
+
+ enum : rc_t {
+ rc_mask = 0x00000000ffffffffull,
+ ep_mask = 0x00ffffffffffffffull,
+ ep_incr = 0x0100000000000000ull,
+ ic_mask = 0xff000000ffffffffull,
+ ic_incr = 0x0000000100000000ull
+ };
+
+ template
+ struct elem_t {
+ std::aligned_storage_t data_ {};
+ std::atomic rc_ { 0 }; // read-counter
+ std::atomic f_ct_ { 0 }; // commit flag
+ };
+
+ alignas(cache_line_size) std::atomic ct_; // commit index
+ alignas(cache_line_size) std::atomic epoch_ { 0 };
+
+ circ::u2_t cursor() const noexcept {
+ return ct_.load(std::memory_order_acquire);
+ }
+
+ constexpr static rc_t inc_rc(rc_t rc) noexcept {
+ return (rc & ic_mask) | ((rc + ic_incr) & ~ic_mask);
+ }
+
+ constexpr static rc_t inc_mask(rc_t rc) noexcept {
+ return inc_rc(rc) & ~rc_mask;
+ }
+
+ template
+ bool push(W* wrapper, F&& f, E* elems) {
+ E* el;
+ circ::u2_t cur_ct;
+ rc_t epoch = epoch_.load(std::memory_order_acquire);
+ for (unsigned k = 0;;) {
+ circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
+ if (cc == 0) return false; // no reader
+ el = elems + circ::index_of(cur_ct = ct_.load(std::memory_order_relaxed));
+ // check all consumers have finished reading this element
+ auto cur_rc = el->rc_.load(std::memory_order_relaxed);
+ circ::cc_t rem_cc = cur_rc & rc_mask;
+ if ((cc & rem_cc) && ((cur_rc & ~ep_mask) == epoch)) {
+ return false; // has not finished yet
+ }
+ else if (!rem_cc) {
+ auto cur_fl = el->f_ct_.load(std::memory_order_acquire);
+ if ((cur_fl != cur_ct) && cur_fl) {
+ return false; // full
+ }
+ }
+ // consider rem_cc to be 0 here
+ if (el->rc_.compare_exchange_weak(
+ cur_rc, inc_mask(epoch | (cur_rc & ep_mask)) | static_cast(cc), std::memory_order_relaxed) &&
+ epoch_.compare_exchange_weak(epoch, epoch, std::memory_order_acq_rel)) {
+ break;
+ }
+ ipc::yield(k);
+ }
+ // only one thread/process would touch here at one time
+ ct_.store(cur_ct + 1, std::memory_order_release);
+ std::forward(f)(&(el->data_));
+ // set flag & try update wt
+ el->f_ct_.store(~static_cast(cur_ct), std::memory_order_release);
+ return true;
+ }
+
+ template
+ bool force_push(W* wrapper, F&& f, E* elems) {
+ E* el;
+ circ::u2_t cur_ct;
+ rc_t epoch = epoch_.fetch_add(ep_incr, std::memory_order_release) + ep_incr;
+ for (unsigned k = 0;;) {
+ circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
+ if (cc == 0) return false; // no reader
+ el = elems + circ::index_of(cur_ct = ct_.load(std::memory_order_relaxed));
+ // check all consumers have finished reading this element
+ auto cur_rc = el->rc_.load(std::memory_order_acquire);
+ circ::cc_t rem_cc = cur_rc & rc_mask;
+ if (cc & rem_cc) {
+ ipc::log("force_push: k = %u, cc = %u, rem_cc = %u\n", k, cc, rem_cc);
+ cc = wrapper->elems()->disconnect_receiver(rem_cc); // disconnect all invalid readers
+ if (cc == 0) return false; // no reader
+ }
+ // just compare & exchange
+ if (el->rc_.compare_exchange_weak(
+ cur_rc, inc_mask(epoch | (cur_rc & ep_mask)) | static_cast(cc), std::memory_order_relaxed)) {
+ if (epoch == epoch_.load(std::memory_order_acquire)) {
+ break;
+ }
+ else if (push(wrapper, std::forward(f), elems)) {
+ return true;
+ }
+ epoch = epoch_.fetch_add(ep_incr, std::memory_order_release) + ep_incr;
+ }
+ ipc::yield(k);
+ }
+ // only one thread/process would touch here at one time
+ ct_.store(cur_ct + 1, std::memory_order_release);
+ std::forward(f)(&(el->data_));
+ // set flag & try update wt
+ el->f_ct_.store(~static_cast(cur_ct), std::memory_order_release);
+ return true;
+ }
+
+ template
+ bool pop(W* wrapper, circ::u2_t& cur, F&& f, R&& out, E(& elems)[N]) {
+ auto* el = elems + circ::index_of(cur);
+ auto cur_fl = el->f_ct_.load(std::memory_order_acquire);
+ if (cur_fl != ~static_cast(cur)) {
+ return false; // empty
+ }
+ ++cur;
+ std::forward(f)(&(el->data_));
+ for (unsigned k = 0;;) {
+ auto cur_rc = el->rc_.load(std::memory_order_acquire);
+ if ((cur_rc & rc_mask) == 0) {
+ std::forward(out)(true);
+ el->f_ct_.store(cur + N - 1, std::memory_order_release);
+ return true;
+ }
+ auto nxt_rc = inc_rc(cur_rc) & ~static_cast(wrapper->connected_id());
+ bool last_one = false;
+ if ((last_one = (nxt_rc & rc_mask) == 0)) {
+ el->f_ct_.store(cur + N - 1, std::memory_order_release);
+ }
+ if (el->rc_.compare_exchange_weak(cur_rc, nxt_rc, std::memory_order_release)) {
+ std::forward(out)(last_one);
+ return true;
+ }
+ ipc::yield(k);
+ }
+ }
+};
+
+} // namespace ipc
diff --git a/crazy_functions/下载arxiv论文翻译摘要.py b/crazy_functions/下载arxiv论文翻译摘要.py
new file mode 100644
index 0000000..50708a1
--- /dev/null
+++ b/crazy_functions/下载arxiv论文翻译摘要.py
@@ -0,0 +1,186 @@
+from request_llm.bridge_chatgpt import predict_no_ui
+from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down, get_conf
+import re, requests, unicodedata, os
+
+def download_arxiv_(url_pdf):
+ if 'arxiv.org' not in url_pdf:
+ if ('.' in url_pdf) and ('/' not in url_pdf):
+ new_url = 'https://arxiv.org/abs/'+url_pdf
+ print('下载编号:', url_pdf, '自动定位:', new_url)
+ # download_arxiv_(new_url)
+ return download_arxiv_(new_url)
+ else:
+ print('不能识别的URL!')
+ return None
+ if 'abs' in url_pdf:
+ url_pdf = url_pdf.replace('abs', 'pdf')
+ url_pdf = url_pdf + '.pdf'
+
+ url_abs = url_pdf.replace('.pdf', '').replace('pdf', 'abs')
+ title, other_info = get_name(_url_=url_abs)
+
+ paper_id = title.split()[0] # '[1712.00559]'
+ if '2' in other_info['year']:
+ title = other_info['year'] + ' ' + title
+
+ known_conf = ['NeurIPS', 'NIPS', 'Nature', 'Science', 'ICLR', 'AAAI']
+ for k in known_conf:
+ if k in other_info['comment']:
+ title = k + ' ' + title
+
+ download_dir = './gpt_log/arxiv/'
+ os.makedirs(download_dir, exist_ok=True)
+
+ title_str = title.replace('?', '?')\
+ .replace(':', ':')\
+ .replace('\"', '“')\
+ .replace('\n', '')\
+ .replace(' ', ' ')\
+ .replace(' ', ' ')
+
+ requests_pdf_url = url_pdf
+ file_path = download_dir+title_str
+ # if os.path.exists(file_path):
+ # print('返回缓存文件')
+ # return './gpt_log/arxiv/'+title_str
+
+ print('下载中')
+ proxies, = get_conf('proxies')
+ r = requests.get(requests_pdf_url, proxies=proxies)
+ with open(file_path, 'wb+') as f:
+ f.write(r.content)
+ print('下载完成')
+
+ # print('输出下载命令:','aria2c -o \"%s\" %s'%(title_str,url_pdf))
+ # subprocess.call('aria2c --all-proxy=\"172.18.116.150:11084\" -o \"%s\" %s'%(download_dir+title_str,url_pdf), shell=True)
+
+ x = "%s %s %s.bib" % (paper_id, other_info['year'], other_info['authors'])
+ x = x.replace('?', '?')\
+ .replace(':', ':')\
+ .replace('\"', '“')\
+ .replace('\n', '')\
+ .replace(' ', ' ')\
+ .replace(' ', ' ')
+ return './gpt_log/arxiv/'+title_str, other_info
+
+
+def get_name(_url_):
+ import os
+ from bs4 import BeautifulSoup
+ print('正在获取文献名!')
+ print(_url_)
+
+ # arxiv_recall = {}
+ # if os.path.exists('./arxiv_recall.pkl'):
+ # with open('./arxiv_recall.pkl', 'rb') as f:
+ # arxiv_recall = pickle.load(f)
+
+ # if _url_ in arxiv_recall:
+ # print('在缓存中')
+ # return arxiv_recall[_url_]
+
+ proxies, = get_conf('proxies')
+ res = requests.get(_url_, proxies=proxies)
+
+ bs = BeautifulSoup(res.text, 'html.parser')
+ other_details = {}
+
+ # get year
+ try:
+ year = bs.find_all(class_='dateline')[0].text
+ year = re.search(r'(\d{4})', year, re.M | re.I).group(1)
+ other_details['year'] = year
+ abstract = bs.find_all(class_='abstract mathjax')[0].text
+ other_details['abstract'] = abstract
+ except:
+ other_details['year'] = ''
+ print('年份获取失败')
+
+ # get author
+ try:
+ authors = bs.find_all(class_='authors')[0].text
+ authors = authors.split('Authors:')[1]
+ other_details['authors'] = authors
+ except:
+ other_details['authors'] = ''
+ print('authors获取失败')
+
+ # get comment
+ try:
+ comment = bs.find_all(class_='metatable')[0].text
+ real_comment = None
+ for item in comment.replace('\n', ' ').split(' '):
+ if 'Comments' in item:
+ real_comment = item
+ if real_comment is not None:
+ other_details['comment'] = real_comment
+ else:
+ other_details['comment'] = ''
+ except:
+ other_details['comment'] = ''
+ print('年份获取失败')
+
+ title_str = BeautifulSoup(
+ res.text, 'html.parser').find('title').contents[0]
+ print('获取成功:', title_str)
+ # arxiv_recall[_url_] = (title_str+'.pdf', other_details)
+ # with open('./arxiv_recall.pkl', 'wb') as f:
+ # pickle.dump(arxiv_recall, f)
+
+ return title_str+'.pdf', other_details
+
+
+
+@CatchException
+def 下载arxiv论文并翻译摘要(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
+
+ CRAZY_FUNCTION_INFO = "下载arxiv论文并翻译摘要,函数插件作者[binary-husky]。正在提取摘要并下载PDF文档……"
+ import glob
+ import os
+
+ # 基本信息:功能、贡献者
+ chatbot.append(["函数插件功能?", CRAZY_FUNCTION_INFO])
+ yield chatbot, history, '正常'
+
+ # 尝试导入依赖,如果缺少依赖,则给出安装建议
+ try:
+ import pdfminer, bs4
+ except:
+ report_execption(chatbot, history,
+ a = f"解析项目: {txt}",
+ b = f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade pdfminer beautifulsoup4```。")
+ yield chatbot, history, '正常'
+ return
+
+ # 清空历史,以免输入溢出
+ history = []
+
+ # 提取摘要,下载PDF文档
+ try:
+ pdf_path, info = download_arxiv_(txt)
+ except:
+ report_execption(chatbot, history,
+ a = f"解析项目: {txt}",
+ b = f"下载pdf文件未成功")
+ yield chatbot, history, '正常'
+ return
+
+ # 翻译摘要等
+ i_say = f"请你阅读以下学术论文相关的材料,提取摘要,翻译为中文。材料如下:{str(info)}"
+ i_say_show_user = f'请你阅读以下学术论文相关的材料,提取摘要,翻译为中文。论文:{pdf_path}'
+ chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
+ yield chatbot, history, '正常'
+ msg = '正常'
+ # ** gpt request **
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
+ chatbot[-1] = (i_say_show_user, gpt_say)
+ history.append(i_say_show_user); history.append(gpt_say)
+ yield chatbot, history, msg
+ # 写入文件
+ import shutil
+ # 重置文件的创建时间
+ shutil.copyfile(pdf_path, f'./gpt_log/{os.path.basename(pdf_path)}'); os.remove(pdf_path)
+ res = write_results_to_file(history)
+ chatbot.append(("完成了吗?", res + "\n\nPDF文件也已经下载"))
+ yield chatbot, history, msg
+
diff --git a/crazy_functions/代码重写为全英文_多线程.py b/crazy_functions/代码重写为全英文_多线程.py
index 6c6b1c7..ad23fea 100644
--- a/crazy_functions/代码重写为全英文_多线程.py
+++ b/crazy_functions/代码重写为全英文_多线程.py
@@ -1,41 +1,97 @@
import threading
-from predict import predict_no_ui_long_connection
-from toolbox import CatchException, write_results_to_file
+from request_llm.bridge_chatgpt import predict_no_ui_long_connection
+from toolbox import CatchException, write_results_to_file, report_execption
+from .crazy_utils import breakdown_txt_to_satisfy_token_limit
+def extract_code_block_carefully(txt):
+ splitted = txt.split('```')
+ n_code_block_seg = len(splitted) - 1
+ if n_code_block_seg <= 1: return txt
+ # 剩下的情况都开头除去 ``` 结尾除去一次 ```
+ txt_out = '```'.join(splitted[1:-1])
+ return txt_out
+
+
+
+def break_txt_into_half_at_some_linebreak(txt):
+ lines = txt.split('\n')
+ n_lines = len(lines)
+ pre = lines[:(n_lines//2)]
+ post = lines[(n_lines//2):]
+ return "\n".join(pre), "\n".join(post)
@CatchException
def 全项目切换英文(txt, top_p, temperature, chatbot, history, sys_prompt, WEB_PORT):
- history = [] # 清空历史,以免输入溢出
- # 集合文件
- import time, glob, os
+ # 第1步:清空历史,以免输入溢出
+ history = []
+
+ # 第2步:尝试导入依赖,如果缺少依赖,则给出安装建议
+ try:
+ import openai, transformers
+ except:
+ report_execption(chatbot, history,
+ a = f"解析项目: {txt}",
+ b = f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade openai transformers```。")
+ yield chatbot, history, '正常'
+ return
+
+ # 第3步:集合文件
+ import time, glob, os, shutil, re, openai
os.makedirs('gpt_log/generated_english_version', exist_ok=True)
os.makedirs('gpt_log/generated_english_version/crazy_functions', exist_ok=True)
file_manifest = [f for f in glob.glob('./*.py') if ('test_project' not in f) and ('gpt_log' not in f)] + \
[f for f in glob.glob('./crazy_functions/*.py') if ('test_project' not in f) and ('gpt_log' not in f)]
+ # file_manifest = ['./toolbox.py']
i_say_show_user_buffer = []
- # 随便显示点什么防止卡顿的感觉
+ # 第4步:随便显示点什么防止卡顿的感觉
for index, fp in enumerate(file_manifest):
# if 'test_project' in fp: continue
with open(fp, 'r', encoding='utf-8') as f:
file_content = f.read()
- i_say_show_user =f'[{index}/{len(file_manifest)}] 接下来请将以下代码中包含的所有中文转化为英文,只输出代码: {os.path.abspath(fp)}'
+ i_say_show_user =f'[{index}/{len(file_manifest)}] 接下来请将以下代码中包含的所有中文转化为英文,只输出转化后的英文代码,请用代码块输出代码: {os.path.abspath(fp)}'
i_say_show_user_buffer.append(i_say_show_user)
chatbot.append((i_say_show_user, "[Local Message] 等待多线程操作,中间过程不予显示."))
yield chatbot, history, '正常'
- # 任务函数
+
+ # 第5步:Token限制下的截断与处理
+ MAX_TOKEN = 3000
+ from transformers import GPT2TokenizerFast
+ print('加载tokenizer中')
+ tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
+ get_token_fn = lambda txt: len(tokenizer(txt)["input_ids"])
+ print('加载tokenizer结束')
+
+
+ # 第6步:任务函数
mutable_return = [None for _ in file_manifest]
+ observe_window = [[""] for _ in file_manifest]
def thread_worker(fp,index):
+ if index > 10:
+ time.sleep(60)
+ print('Openai 限制免费用户每分钟20次请求,降低请求频率中。')
with open(fp, 'r', encoding='utf-8') as f:
file_content = f.read()
- i_say = f'接下来请将以下代码中包含的所有中文转化为英文,只输出代码,文件名是{fp},文件代码是 ```{file_content}```'
- # ** gpt request **
- gpt_say = predict_no_ui_long_connection(inputs=i_say, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt)
- mutable_return[index] = gpt_say
+ i_say_template = lambda fp, file_content: f'接下来请将以下代码中包含的所有中文转化为英文,只输出代码,文件名是{fp},文件代码是 ```{file_content}```'
+ try:
+ gpt_say = ""
+ # 分解代码文件
+ file_content_breakdown = breakdown_txt_to_satisfy_token_limit(file_content, get_token_fn, MAX_TOKEN)
+ for file_content_partial in file_content_breakdown:
+ i_say = i_say_template(fp, file_content_partial)
+ # # ** gpt request **
+ gpt_say_partial = predict_no_ui_long_connection(inputs=i_say, top_p=top_p, temperature=temperature, history=[], sys_prompt=sys_prompt, observe_window=observe_window[index])
+ gpt_say_partial = extract_code_block_carefully(gpt_say_partial)
+ gpt_say += gpt_say_partial
+ mutable_return[index] = gpt_say
+ except ConnectionAbortedError as token_exceed_err:
+ print('至少一个线程任务Token溢出而失败', e)
+ except Exception as e:
+ print('至少一个线程任务意外失败', e)
- # 所有线程同时开始执行任务函数
+ # 第7步:所有线程同时开始执行任务函数
handles = [threading.Thread(target=thread_worker, args=(fp,index)) for index, fp in enumerate(file_manifest)]
for h in handles:
h.daemon = True
@@ -43,19 +99,23 @@ def 全项目切换英文(txt, top_p, temperature, chatbot, history, sys_prompt,
chatbot.append(('开始了吗?', f'多线程操作已经开始'))
yield chatbot, history, '正常'
- # 循环轮询各个线程是否执行完毕
+ # 第8步:循环轮询各个线程是否执行完毕
cnt = 0
while True:
- time.sleep(1)
+ cnt += 1
+ time.sleep(0.2)
th_alive = [h.is_alive() for h in handles]
if not any(th_alive): break
- stat = ['执行中' if alive else '已完成' for alive in th_alive]
- stat_str = '|'.join(stat)
- cnt += 1
- chatbot[-1] = (chatbot[-1][0], f'多线程操作已经开始,完成情况: {stat_str}' + ''.join(['.']*(cnt%4)))
+ # 更好的UI视觉效果
+ observe_win = []
+ for thread_index, alive in enumerate(th_alive):
+ observe_win.append("[ ..."+observe_window[thread_index][0][-60:].replace('\n','').replace('```','...').replace(' ','.').replace('
','.....').replace('$','.')+"... ]")
+ stat = [f'执行中: {obs}\n\n' if alive else '已完成\n\n' for alive, obs in zip(th_alive, observe_win)]
+ stat_str = ''.join(stat)
+ chatbot[-1] = (chatbot[-1][0], f'多线程操作已经开始,完成情况: \n\n{stat_str}' + ''.join(['.']*(cnt%10+1)))
yield chatbot, history, '正常'
- # 把结果写入文件
+ # 第9步:把结果写入文件
for index, h in enumerate(handles):
h.join() # 这里其实不需要join了,肯定已经都结束了
fp = file_manifest[index]
@@ -63,13 +123,17 @@ def 全项目切换英文(txt, top_p, temperature, chatbot, history, sys_prompt,
i_say_show_user = i_say_show_user_buffer[index]
where_to_relocate = f'gpt_log/generated_english_version/{fp}'
- with open(where_to_relocate, 'w+', encoding='utf-8') as f: f.write(gpt_say.lstrip('```').rstrip('```'))
+ if gpt_say is not None:
+ with open(where_to_relocate, 'w+', encoding='utf-8') as f:
+ f.write(gpt_say)
+ else: # 失败
+ shutil.copyfile(file_manifest[index], where_to_relocate)
chatbot.append((i_say_show_user, f'[Local Message] 已完成{os.path.abspath(fp)}的转化,\n\n存入{os.path.abspath(where_to_relocate)}'))
history.append(i_say_show_user); history.append(gpt_say)
yield chatbot, history, '正常'
time.sleep(1)
- # 备份一个文件
+ # 第10步:备份一个文件
res = write_results_to_file(history)
chatbot.append(("生成一份任务执行报告", res))
yield chatbot, history, '正常'
diff --git a/crazy_functions/总结word文档.py b/crazy_functions/总结word文档.py
new file mode 100644
index 0000000..f3edfe8
--- /dev/null
+++ b/crazy_functions/总结word文档.py
@@ -0,0 +1,127 @@
+from request_llm.bridge_chatgpt import predict_no_ui
+from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
+fast_debug = False
+
+
+def 解析docx(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
+ import time, os
+ # pip install python-docx 用于docx格式,跨平台
+ # pip install pywin32 用于doc格式,仅支持Win平台
+
+ print('begin analysis on:', file_manifest)
+ for index, fp in enumerate(file_manifest):
+ if fp.split(".")[-1] == "docx":
+ from docx import Document
+ doc = Document(fp)
+ file_content = "\n".join([para.text for para in doc.paragraphs])
+ else:
+ import win32com.client
+ word = win32com.client.Dispatch("Word.Application")
+ word.visible = False
+ # 打开文件
+ print('fp', os.getcwd())
+ doc = word.Documents.Open(os.getcwd() + '/' + fp)
+ # file_content = doc.Content.Text
+ doc = word.ActiveDocument
+ file_content = doc.Range().Text
+ doc.Close()
+ word.Quit()
+
+ print(file_content)
+
+ prefix = "接下来请你逐文件分析下面的论文文件," if index == 0 else ""
+ # private_upload里面的文件名在解压zip后容易出现乱码(rar和7z格式正常),故可以只分析文章内容,不输入文件名
+ i_say = prefix + f'请对下面的文章片段用中英文做概述,文件名是{os.path.relpath(fp, project_folder)},' \
+ f'文章内容是 ```{file_content}```'
+ i_say_show_user = prefix + f'[{index+1}/{len(file_manifest)}] 假设你是论文审稿专家,请对下面的文章片段做概述: {os.path.abspath(fp)}'
+ chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
+ yield chatbot, history, '正常'
+
+ if not fast_debug:
+ msg = '正常'
+ # ** gpt request **
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature,
+ history=[]) # 带超时倒计时
+ chatbot[-1] = (i_say_show_user, gpt_say)
+ history.append(i_say_show_user);
+ history.append(gpt_say)
+ yield chatbot, history, msg
+ if not fast_debug: time.sleep(2)
+
+ """
+ # 可按需启用
+ i_say = f'根据你上述的分析,对全文进行概括,用学术性语言写一段中文摘要,然后再写一篇英文的。'
+ chatbot.append((i_say, "[Local Message] waiting gpt response."))
+ yield chatbot, history, '正常'
+
+
+ i_say = f'我想让你做一个论文写作导师。您的任务是使用人工智能工具(例如自然语言处理)提供有关如何改进其上述文章的反馈。' \
+ f'您还应该利用您在有效写作技巧方面的修辞知识和经验来建议作者可以更好地以书面形式表达他们的想法和想法的方法。' \
+ f'根据你之前的分析,提出建议'
+ chatbot.append((i_say, "[Local Message] waiting gpt response."))
+ yield chatbot, history, '正常'
+
+ """
+
+ if not fast_debug:
+ msg = '正常'
+ # ** gpt request **
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature,
+ history=history) # 带超时倒计时
+
+ chatbot[-1] = (i_say, gpt_say)
+ history.append(i_say)
+ history.append(gpt_say)
+ yield chatbot, history, msg
+ res = write_results_to_file(history)
+ chatbot.append(("完成了吗?", res))
+ yield chatbot, history, msg
+
+
+@CatchException
+def 总结word文档(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
+ import glob, os
+
+ # 基本信息:功能、贡献者
+ chatbot.append([
+ "函数插件功能?",
+ "批量总结Word文档。函数插件贡献者: JasonGuo1"])
+ yield chatbot, history, '正常'
+
+ # 尝试导入依赖,如果缺少依赖,则给出安装建议
+ try:
+ from docx import Document
+ except:
+ report_execption(chatbot, history,
+ a=f"解析项目: {txt}",
+ b=f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade python-docx pywin32```。")
+ yield chatbot, history, '正常'
+ return
+
+ # 清空历史,以免输入溢出
+ history = []
+
+ # 检测输入参数,如没有给定输入参数,直接退出
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "": txt = '空空如也的输入栏'
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
+ yield chatbot, history, '正常'
+ return
+
+ # 搜索需要处理的文件清单
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.docx', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.doc', recursive=True)]
+ # [f for f in glob.glob(f'{project_folder}/**/*.tex', recursive=True)] + \
+ # [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
+ # [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
+
+ # 如果没找到任何文件
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何.docx或doc文件: {txt}")
+ yield chatbot, history, '正常'
+ return
+
+ # 开始正式执行任务
+ yield from 解析docx(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
diff --git a/crazy_functions/批量总结PDF文档.py b/crazy_functions/批量总结PDF文档.py
index 102bc9e..0ab095a 100644
--- a/crazy_functions/批量总结PDF文档.py
+++ b/crazy_functions/批量总结PDF文档.py
@@ -1,7 +1,61 @@
-from predict import predict_no_ui
+from request_llm.bridge_chatgpt import predict_no_ui
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
+import re
+import unicodedata
fast_debug = False
+def is_paragraph_break(match):
+ """
+ 根据给定的匹配结果来判断换行符是否表示段落分隔。
+ 如果换行符前为句子结束标志(句号,感叹号,问号),且下一个字符为大写字母,则换行符更有可能表示段落分隔。
+ 也可以根据之前的内容长度来判断段落是否已经足够长。
+ """
+ prev_char, next_char = match.groups()
+
+ # 句子结束标志
+ sentence_endings = ".!?"
+
+ # 设定一个最小段落长度阈值
+ min_paragraph_length = 140
+
+ if prev_char in sentence_endings and next_char.isupper() and len(match.string[:match.start(1)]) > min_paragraph_length:
+ return "\n\n"
+ else:
+ return " "
+
+def normalize_text(text):
+ """
+ 通过把连字(ligatures)等文本特殊符号转换为其基本形式来对文本进行归一化处理。
+ 例如,将连字 "fi" 转换为 "f" 和 "i"。
+ """
+ # 对文本进行归一化处理,分解连字
+ normalized_text = unicodedata.normalize("NFKD", text)
+
+ # 替换其他特殊字符
+ cleaned_text = re.sub(r'[^\x00-\x7F]+', '', normalized_text)
+
+ return cleaned_text
+
+def clean_text(raw_text):
+ """
+ 对从 PDF 提取出的原始文本进行清洗和格式化处理。
+ 1. 对原始文本进行归一化处理。
+ 2. 替换跨行的连词,例如 “Espe-\ncially” 转换为 “Especially”。
+ 3. 根据 heuristic 规则判断换行符是否是段落分隔,并相应地进行替换。
+ """
+ # 对文本进行归一化处理
+ normalized_text = normalize_text(raw_text)
+
+ # 替换跨行的连词
+ text = re.sub(r'(\w+-\n\w+)', lambda m: m.group(1).replace('-\n', ''), normalized_text)
+
+ # 根据前后相邻字符的特点,找到原文本中的换行符
+ newlines = re.compile(r'(\S)\n(\S)')
+
+ # 根据 heuristic 规则,用空格或段落分隔符替换原换行符
+ final_text = re.sub(newlines, lambda m: m.group(1) + is_paragraph_break(m) + m.group(2), text)
+
+ return final_text.strip()
def 解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
import time, glob, os, fitz
@@ -11,6 +65,7 @@ def 解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, histor
file_content = ""
for page in doc:
file_content += page.get_text()
+ file_content = clean_text(file_content)
print(file_content)
prefix = "接下来请你逐文件分析下面的论文文件,概括其内容" if index==0 else ""
@@ -58,7 +113,7 @@ def 批量总结PDF文档(txt, top_p, temperature, chatbot, history, systemPromp
# 基本信息:功能、贡献者
chatbot.append([
"函数插件功能?",
- "批量总结PDF文档。函数插件贡献者: ValeriaWong"])
+ "批量总结PDF文档。函数插件贡献者: ValeriaWong,Eralien"])
yield chatbot, history, '正常'
# 尝试导入依赖,如果缺少依赖,则给出安装建议
diff --git a/crazy_functions/批量总结PDF文档pdfminer.py b/crazy_functions/批量总结PDF文档pdfminer.py
new file mode 100644
index 0000000..8aba47c
--- /dev/null
+++ b/crazy_functions/批量总结PDF文档pdfminer.py
@@ -0,0 +1,151 @@
+from request_llm.bridge_chatgpt import predict_no_ui
+from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
+
+fast_debug = False
+
+def readPdf(pdfPath):
+ """
+ 读取pdf文件,返回文本内容
+ """
+ import pdfminer
+ from pdfminer.pdfparser import PDFParser
+ from pdfminer.pdfdocument import PDFDocument
+ from pdfminer.pdfpage import PDFPage, PDFTextExtractionNotAllowed
+ from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
+ from pdfminer.pdfdevice import PDFDevice
+ from pdfminer.layout import LAParams
+ from pdfminer.converter import PDFPageAggregator
+
+ fp = open(pdfPath, 'rb')
+
+ # Create a PDF parser object associated with the file object
+ parser = PDFParser(fp)
+
+ # Create a PDF document object that stores the document structure.
+ # Password for initialization as 2nd parameter
+ document = PDFDocument(parser)
+ # Check if the document allows text extraction. If not, abort.
+ if not document.is_extractable:
+ raise PDFTextExtractionNotAllowed
+
+ # Create a PDF resource manager object that stores shared resources.
+ rsrcmgr = PDFResourceManager()
+
+ # Create a PDF device object.
+ # device = PDFDevice(rsrcmgr)
+
+ # BEGIN LAYOUT ANALYSIS.
+ # Set parameters for analysis.
+ laparams = LAParams(
+ char_margin=10.0,
+ line_margin=0.2,
+ boxes_flow=0.2,
+ all_texts=False,
+ )
+ # Create a PDF page aggregator object.
+ device = PDFPageAggregator(rsrcmgr, laparams=laparams)
+ # Create a PDF interpreter object.
+ interpreter = PDFPageInterpreter(rsrcmgr, device)
+
+ # loop over all pages in the document
+ outTextList = []
+ for page in PDFPage.create_pages(document):
+ # read the page into a layout object
+ interpreter.process_page(page)
+ layout = device.get_result()
+ for obj in layout._objs:
+ if isinstance(obj, pdfminer.layout.LTTextBoxHorizontal):
+ # print(obj.get_text())
+ outTextList.append(obj.get_text())
+
+ return outTextList
+
+
+def 解析Paper(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
+ import time, glob, os
+ from bs4 import BeautifulSoup
+ print('begin analysis on:', file_manifest)
+ for index, fp in enumerate(file_manifest):
+ if ".tex" in fp:
+ with open(fp, 'r', encoding='utf-8') as f:
+ file_content = f.read()
+ if ".pdf" in fp.lower():
+ file_content = readPdf(fp)
+ file_content = BeautifulSoup(''.join(file_content), features="lxml").body.text.encode('gbk', 'ignore').decode('gbk')
+
+ prefix = "接下来请你逐文件分析下面的论文文件,概括其内容" if index==0 else ""
+ i_say = prefix + f'请对下面的文章片段用中文做一个概述,文件名是{os.path.relpath(fp, project_folder)},文章内容是 ```{file_content}```'
+ i_say_show_user = prefix + f'[{index}/{len(file_manifest)}] 请对下面的文章片段做一个概述: {os.path.abspath(fp)}'
+ chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
+ print('[1] yield chatbot, history')
+ yield chatbot, history, '正常'
+
+ if not fast_debug:
+ msg = '正常'
+ # ** gpt request **
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
+
+ print('[2] end gpt req')
+ chatbot[-1] = (i_say_show_user, gpt_say)
+ history.append(i_say_show_user); history.append(gpt_say)
+ print('[3] yield chatbot, history')
+ yield chatbot, history, msg
+ print('[4] next')
+ if not fast_debug: time.sleep(2)
+
+ all_file = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(file_manifest)])
+ i_say = f'根据以上你自己的分析,对全文进行概括,用学术性语言写一段中文摘要,然后再写一段英文摘要(包括{all_file})。'
+ chatbot.append((i_say, "[Local Message] waiting gpt response."))
+ yield chatbot, history, '正常'
+
+ if not fast_debug:
+ msg = '正常'
+ # ** gpt request **
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history) # 带超时倒计时
+
+ chatbot[-1] = (i_say, gpt_say)
+ history.append(i_say); history.append(gpt_say)
+ yield chatbot, history, msg
+ res = write_results_to_file(history)
+ chatbot.append(("完成了吗?", res))
+ yield chatbot, history, msg
+
+
+
+@CatchException
+def 批量总结PDF文档pdfminer(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
+ history = [] # 清空历史,以免输入溢出
+ import glob, os
+
+ # 基本信息:功能、贡献者
+ chatbot.append([
+ "函数插件功能?",
+ "批量总结PDF文档,此版本使用pdfminer插件,带token约简功能。函数插件贡献者: Euclid-Jie。"])
+ yield chatbot, history, '正常'
+
+ # 尝试导入依赖,如果缺少依赖,则给出安装建议
+ try:
+ import pdfminer, bs4
+ except:
+ report_execption(chatbot, history,
+ a = f"解析项目: {txt}",
+ b = f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade pdfminer beautifulsoup4```。")
+ yield chatbot, history, '正常'
+ return
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "": txt = '空空如也的输入栏'
+ report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
+ yield chatbot, history, '正常'
+ return
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.tex', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.pdf', recursive=True)] # + \
+ # [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
+ # [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex或pdf文件: {txt}")
+ yield chatbot, history, '正常'
+ return
+ yield from 解析Paper(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
+
diff --git a/crazy_functions/批量翻译PDF文档_多线程.py b/crazy_functions/批量翻译PDF文档_多线程.py
new file mode 100644
index 0000000..348ebb9
--- /dev/null
+++ b/crazy_functions/批量翻译PDF文档_多线程.py
@@ -0,0 +1,203 @@
+from toolbox import CatchException, report_execption, write_results_to_file
+from .crazy_utils import request_gpt_model_in_new_thread_with_ui_alive
+from .crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency
+
+
+def read_and_clean_pdf_text(fp):
+ """
+ **输入参数说明**
+ - `fp`:需要读取和清理文本的pdf文件路径
+
+ **输出参数说明**
+ - `meta_txt`:清理后的文本内容字符串
+ - `page_one_meta`:第一页清理后的文本内容列表
+
+ **函数功能**
+ 读取pdf文件并清理其中的文本内容,清理规则包括:
+ - 提取所有块元的文本信息,并合并为一个字符串
+ - 去除短块(字符数小于100)并替换为回车符
+ - 清理多余的空行
+ - 合并小写字母开头的段落块并替换为空格
+ - 清除重复的换行
+ - 将每个换行符替换为两个换行符,使每个段落之间有两个换行符分隔
+ """
+ import fitz
+ import re
+ import numpy as np
+ # file_content = ""
+ with fitz.open(fp) as doc:
+ meta_txt = []
+ meta_font = []
+ for index, page in enumerate(doc):
+ # file_content += page.get_text()
+ text_areas = page.get_text("dict") # 获取页面上的文本信息
+
+ # 块元提取 for each word segment with in line for each line cross-line words for each block
+ meta_txt.extend([" ".join(["".join([wtf['text'] for wtf in l['spans']]) for l in t['lines']]).replace(
+ '- ', '') for t in text_areas['blocks'] if 'lines' in t])
+ meta_font.extend([np.mean([np.mean([wtf['size'] for wtf in l['spans']])
+ for l in t['lines']]) for t in text_areas['blocks'] if 'lines' in t])
+ if index == 0:
+ page_one_meta = [" ".join(["".join([wtf['text'] for wtf in l['spans']]) for l in t['lines']]).replace(
+ '- ', '') for t in text_areas['blocks'] if 'lines' in t]
+
+ def 把字符太少的块清除为回车(meta_txt):
+ for index, block_txt in enumerate(meta_txt):
+ if len(block_txt) < 100:
+ meta_txt[index] = '\n'
+ return meta_txt
+ meta_txt = 把字符太少的块清除为回车(meta_txt)
+
+ def 清理多余的空行(meta_txt):
+ for index in reversed(range(1, len(meta_txt))):
+ if meta_txt[index] == '\n' and meta_txt[index-1] == '\n':
+ meta_txt.pop(index)
+ return meta_txt
+ meta_txt = 清理多余的空行(meta_txt)
+
+ def 合并小写开头的段落块(meta_txt):
+ def starts_with_lowercase_word(s):
+ pattern = r"^[a-z]+"
+ match = re.match(pattern, s)
+ if match:
+ return True
+ else:
+ return False
+ for _ in range(100):
+ for index, block_txt in enumerate(meta_txt):
+ if starts_with_lowercase_word(block_txt):
+ if meta_txt[index-1] != '\n':
+ meta_txt[index-1] += ' '
+ else:
+ meta_txt[index-1] = ''
+ meta_txt[index-1] += meta_txt[index]
+ meta_txt[index] = '\n'
+ return meta_txt
+ meta_txt = 合并小写开头的段落块(meta_txt)
+ meta_txt = 清理多余的空行(meta_txt)
+
+ meta_txt = '\n'.join(meta_txt)
+ # 清除重复的换行
+ for _ in range(5):
+ meta_txt = meta_txt.replace('\n\n', '\n')
+
+ # 换行 -> 双换行
+ meta_txt = meta_txt.replace('\n', '\n\n')
+
+ return meta_txt, page_one_meta
+
+
+@CatchException
+def 批量翻译PDF文档(txt, top_p, temperature, chatbot, history, sys_prompt, WEB_PORT):
+ import glob
+ import os
+
+ # 基本信息:功能、贡献者
+ chatbot.append([
+ "函数插件功能?",
+ "批量总结PDF文档。函数插件贡献者: Binary-Husky(二进制哈士奇)"])
+ yield chatbot, history, '正常'
+
+ # 尝试导入依赖,如果缺少依赖,则给出安装建议
+ try:
+ import fitz
+ import tiktoken
+ except:
+ report_execption(chatbot, history,
+ a=f"解析项目: {txt}",
+ b=f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade pymupdf tiktoken```。")
+ yield chatbot, history, '正常'
+ return
+
+ # 清空历史,以免输入溢出
+ history = []
+
+ # 检测输入参数,如没有给定输入参数,直接退出
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "":
+ txt = '空空如也的输入栏'
+ report_execption(chatbot, history,
+ a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
+ yield chatbot, history, '正常'
+ return
+
+ # 搜索需要处理的文件清单
+ file_manifest = [f for f in glob.glob(
+ f'{project_folder}/**/*.pdf', recursive=True)]
+
+ # 如果没找到任何文件
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history,
+ a=f"解析项目: {txt}", b=f"找不到任何.tex或.pdf文件: {txt}")
+ yield chatbot, history, '正常'
+ return
+
+ # 开始正式执行任务
+ yield from 解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, history, sys_prompt)
+
+
+def 解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, history, sys_prompt):
+ import os
+ import tiktoken
+ TOKEN_LIMIT_PER_FRAGMENT = 1600
+ generated_conclusion_files = []
+ for index, fp in enumerate(file_manifest):
+ # 读取PDF文件
+ file_content, page_one = read_and_clean_pdf_text(fp)
+ # 递归地切割PDF文件
+ from .crazy_utils import breakdown_txt_to_satisfy_token_limit_for_pdf
+ enc = tiktoken.get_encoding("gpt2")
+ def get_token_num(txt): return len(enc.encode(txt))
+ # 分解文本
+ paper_fragments = breakdown_txt_to_satisfy_token_limit_for_pdf(
+ txt=file_content, get_token_fn=get_token_num, limit=TOKEN_LIMIT_PER_FRAGMENT)
+ page_one_fragments = breakdown_txt_to_satisfy_token_limit_for_pdf(
+ txt=str(page_one), get_token_fn=get_token_num, limit=TOKEN_LIMIT_PER_FRAGMENT//4)
+ # 为了更好的效果,我们剥离Introduction之后的部分
+ paper_meta = page_one_fragments[0].split('introduction')[0].split(
+ 'Introduction')[0].split('INTRODUCTION')[0]
+ # 单线,获取文章meta信息
+ paper_meta_info = yield from request_gpt_model_in_new_thread_with_ui_alive(
+ inputs=f"以下是一篇学术论文的基础信息,请从中提取出“标题”、“收录会议或期刊”、“作者”、“摘要”、“编号”、“作者邮箱”这六个部分。请用markdown格式输出,最后用中文翻译摘要部分。请提取:{paper_meta}",
+ inputs_show_user=f"请从{fp}中提取出“标题”、“收录会议或期刊”等基本信息。",
+ top_p=top_p, temperature=temperature,
+ chatbot=chatbot, history=[],
+ sys_prompt="Your job is to collect information from materials。",
+ )
+ # 多线,翻译
+ gpt_response_collection = yield from request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency(
+ inputs_array=[
+ f"以下是你需要翻译的文章段落:\n{frag}" for frag in paper_fragments],
+ inputs_show_user_array=[f"" for _ in paper_fragments],
+ top_p=top_p, temperature=temperature,
+ chatbot=chatbot,
+ history_array=[[paper_meta] for _ in paper_fragments],
+ sys_prompt_array=[
+ "请你作为一个学术翻译,把整个段落翻译成中文,要求语言简洁,禁止重复输出原文。" for _ in paper_fragments],
+ max_workers=16 # OpenAI所允许的最大并行过载
+ )
+
+ final = ["", paper_meta_info + '\n\n---\n\n---\n\n---\n\n']
+ final.extend(gpt_response_collection)
+ create_report_file_name = f"{os.path.basename(fp)}.trans.md"
+ res = write_results_to_file(final, file_name=create_report_file_name)
+ generated_conclusion_files.append(
+ f'./gpt_log/{create_report_file_name}')
+ chatbot.append((f"{fp}完成了吗?", res))
+ msg = "完成"
+ yield chatbot, history, msg
+
+ # 准备文件的下载
+ import shutil
+ for pdf_path in generated_conclusion_files:
+ # 重命名文件
+ rename_file = f'./gpt_log/总结论文-{os.path.basename(pdf_path)}'
+ if os.path.exists(rename_file):
+ os.remove(rename_file)
+ shutil.copyfile(pdf_path, rename_file)
+ if os.path.exists(pdf_path):
+ os.remove(pdf_path)
+ chatbot.append(("给出输出文件清单", str(generated_conclusion_files)))
+ yield chatbot, history, msg
diff --git a/crazy_functions/生成函数注释.py b/crazy_functions/生成函数注释.py
index 010600c..62df83a 100644
--- a/crazy_functions/生成函数注释.py
+++ b/crazy_functions/生成函数注释.py
@@ -1,4 +1,4 @@
-from predict import predict_no_ui
+from request_llm.bridge_chatgpt import predict_no_ui
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
fast_debug = False
diff --git a/crazy_functions/解析项目源代码.py b/crazy_functions/解析项目源代码.py
index a239d96..ced0f26 100644
--- a/crazy_functions/解析项目源代码.py
+++ b/crazy_functions/解析项目源代码.py
@@ -1,4 +1,4 @@
-from predict import predict_no_ui
+from request_llm.bridge_chatgpt import predict_no_ui
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
fast_debug = False
@@ -50,7 +50,8 @@ def 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot,
def 解析项目本身(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
history = [] # 清空历史,以免输入溢出
import time, glob, os
- file_manifest = [f for f in glob.glob('*.py')]
+ file_manifest = [f for f in glob.glob('./*.py') if ('test_project' not in f) and ('gpt_log' not in f)] + \
+ [f for f in glob.glob('./crazy_functions/*.py') if ('test_project' not in f) and ('gpt_log' not in f)]
for index, fp in enumerate(file_manifest):
# if 'test_project' in fp: continue
with open(fp, 'r', encoding='utf-8') as f:
@@ -65,7 +66,7 @@ def 解析项目本身(txt, top_p, temperature, chatbot, history, systemPromptTx
if not fast_debug:
# ** gpt request **
# gpt_say = predict_no_ui(inputs=i_say, top_p=top_p, temperature=temperature)
- gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[], long_connection=True) # 带超时倒计时
chatbot[-1] = (i_say_show_user, gpt_say)
history.append(i_say_show_user); history.append(gpt_say)
@@ -79,7 +80,7 @@ def 解析项目本身(txt, top_p, temperature, chatbot, history, systemPromptTx
if not fast_debug:
# ** gpt request **
# gpt_say = predict_no_ui(inputs=i_say, top_p=top_p, temperature=temperature, history=history)
- gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history) # 带超时倒计时
+ gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history, long_connection=True) # 带超时倒计时
chatbot[-1] = (i_say, gpt_say)
history.append(i_say); history.append(gpt_say)
@@ -118,8 +119,8 @@ def 解析一个C项目的头文件(txt, top_p, temperature, chatbot, history, s
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
yield chatbot, history, '正常'
return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] # + \
- # [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.hpp', recursive=True)] #+ \
# [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
if len(file_manifest) == 0:
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.h头文件: {txt}")
@@ -140,6 +141,7 @@ def 解析一个C项目(txt, top_p, temperature, chatbot, history, systemPromptT
return
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] + \
[f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.hpp', recursive=True)] + \
[f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
if len(file_manifest) == 0:
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.h头文件: {txt}")
@@ -147,3 +149,66 @@ def 解析一个C项目(txt, top_p, temperature, chatbot, history, systemPromptT
return
yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
+
+@CatchException
+def 解析一个Java项目(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
+ history = [] # 清空历史,以免输入溢出
+ import glob, os
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "": txt = '空空如也的输入栏'
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
+ yield chatbot, history, '正常'
+ return
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.java', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.jar', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.xml', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.sh', recursive=True)]
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何java文件: {txt}")
+ yield chatbot, history, '正常'
+ return
+ yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
+
+
+@CatchException
+def 解析一个Rect项目(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
+ history = [] # 清空历史,以免输入溢出
+ import glob, os
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "": txt = '空空如也的输入栏'
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
+ yield chatbot, history, '正常'
+ return
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.ts', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.tsx', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.json', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.js', recursive=True)] + \
+ [f for f in glob.glob(f'{project_folder}/**/*.jsx', recursive=True)]
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何Rect文件: {txt}")
+ yield chatbot, history, '正常'
+ return
+ yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
+
+
+@CatchException
+def 解析一个Golang项目(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
+ history = [] # 清空历史,以免输入溢出
+ import glob, os
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "": txt = '空空如也的输入栏'
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
+ yield chatbot, history, '正常'
+ return
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.go', recursive=True)]
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何golang文件: {txt}")
+ yield chatbot, history, '正常'
+ return
+ yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
diff --git a/crazy_functions/读文章写摘要.py b/crazy_functions/读文章写摘要.py
index dc92256..b669864 100644
--- a/crazy_functions/读文章写摘要.py
+++ b/crazy_functions/读文章写摘要.py
@@ -1,4 +1,4 @@
-from predict import predict_no_ui
+from request_llm.bridge_chatgpt import predict_no_ui
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
fast_debug = False
diff --git a/crazy_functions/高级功能函数模板.py b/crazy_functions/高级功能函数模板.py
index 4cf1cb9..6530044 100644
--- a/crazy_functions/高级功能函数模板.py
+++ b/crazy_functions/高级功能函数模板.py
@@ -1,25 +1,20 @@
-from predict import predict_no_ui_long_connection
-from toolbox import CatchException, report_execption, write_results_to_file
+from toolbox import CatchException
+from .crazy_utils import request_gpt_model_in_new_thread_with_ui_alive
import datetime
-
@CatchException
def 高阶功能模板函数(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
history = [] # 清空历史,以免输入溢出
- chatbot.append(("这是什么功能?", "[Local Message] 请注意,您正在调用一个函数模板,该函数面向希望实现更多有趣功能的开发者,它可以作为创建新功能函数的模板。为了做到简单易读,该函数只有25行代码,不会实时反馈文字流或心跳,请耐心等待程序输出完成。另外您若希望分享新的功能模组,请不吝PR!"))
+ chatbot.append(("这是什么功能?", "[Local Message] 请注意,您正在调用一个[函数插件]的模板,该函数面向希望实现更多有趣功能的开发者,它可以作为创建新功能函数的模板(该函数只有20行代码)。此外我们也提供可同步处理大量文件的多线程Demo供您参考。您若希望分享新的功能模组,请不吝PR!"))
yield chatbot, history, '正常' # 由于请求gpt需要一段时间,我们先及时地做一次状态显示
-
for i in range(5):
currentMonth = (datetime.date.today() + datetime.timedelta(days=i)).month
currentDay = (datetime.date.today() + datetime.timedelta(days=i)).day
- i_say = f'历史中哪些事件发生在{currentMonth}月{currentDay}日?列举两条并发送相关图片。发送图片时,请使用Markdown,将Unsplash API中的PUT_YOUR_QUERY_HERE替换成描述改事件的三个最重要的单词。'
- chatbot.append((i_say, "[Local Message] waiting gpt response."))
- yield chatbot, history, '正常' # 由于请求gpt需要一段时间,我们先及时地做一次状态显示
-
- # history = [] 每次询问不携带之前的询问历史
- gpt_say = predict_no_ui_long_connection(
- inputs=i_say, top_p=top_p, temperature=temperature, history=[],
- sys_prompt="当你想发送一张照片时,请使用Markdown, 并且不要有反斜线, 不要用代码块。使用 Unsplash API (https://source.unsplash.com/1280x720/? < PUT_YOUR_QUERY_HERE >)。") # 请求gpt,需要一段时间
-
+ i_say = f'历史中哪些事件发生在{currentMonth}月{currentDay}日?列举两条并发送相关图片。发送图片时,请使用Markdown,将Unsplash API中的PUT_YOUR_QUERY_HERE替换成描述该事件的一个最重要的单词。'
+ gpt_say = yield from request_gpt_model_in_new_thread_with_ui_alive(
+ inputs=i_say, inputs_show_user=i_say,
+ top_p=top_p, temperature=temperature, chatbot=chatbot, history=[],
+ sys_prompt="当你想发送一张照片时,请使用Markdown, 并且不要有反斜线, 不要用代码块。使用 Unsplash API (https://source.unsplash.com/1280x720/? < PUT_YOUR_QUERY_HERE >)。"
+ )
chatbot[-1] = (i_say, gpt_say)
history.append(i_say);history.append(gpt_say)
- yield chatbot, history, '正常' # 显示
\ No newline at end of file
+ yield chatbot, history, '正常'
\ No newline at end of file
diff --git a/functional_crazy.py b/functional_crazy.py
deleted file mode 100644
index 3f13853..0000000
--- a/functional_crazy.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# UserVisibleLevel是过滤器参数。
-# 由于UI界面空间有限,所以通过这种方式决定UI界面中显示哪些插件
-# 默认函数插件 VisibleLevel 是 0
-# 当 UserVisibleLevel >= 函数插件的 VisibleLevel 时,该函数插件才会被显示出来
-UserVisibleLevel = 1
-
-def get_crazy_functionals():
- from crazy_functions.读文章写摘要 import 读文章写摘要
- from crazy_functions.生成函数注释 import 批量生成函数注释
- from crazy_functions.解析项目源代码 import 解析项目本身
- from crazy_functions.解析项目源代码 import 解析一个Python项目
- from crazy_functions.解析项目源代码 import 解析一个C项目的头文件
- from crazy_functions.解析项目源代码 import 解析一个C项目
- from crazy_functions.高级功能函数模板 import 高阶功能模板函数
- from crazy_functions.代码重写为全英文_多线程 import 全项目切换英文
-
- function_plugins = {
- "请解析并解构此项目本身": {
- "Function": 解析项目本身
- },
- "解析整个py项目": {
- "Color": "stop", # 按钮颜色
- "Function": 解析一个Python项目
- },
- "解析整个C++项目头文件": {
- "Color": "stop", # 按钮颜色
- "Function": 解析一个C项目的头文件
- },
- "解析整个C++项目": {
- "Color": "stop", # 按钮颜色
- "Function": 解析一个C项目
- },
- "读tex论文写摘要": {
- "Color": "stop", # 按钮颜色
- "Function": 读文章写摘要
- },
- "批量生成函数注释": {
- "Color": "stop", # 按钮颜色
- "Function": 批量生成函数注释
- },
- "[多线程demo] 把本项目源代码切换成全英文": {
- "Function": 全项目切换英文
- },
- "[函数插件模板demo] 历史上的今天": {
- "Function": 高阶功能模板函数
- },
- }
-
- # VisibleLevel=1 经过测试,但功能未达到理想状态
- if UserVisibleLevel >= 1:
- from crazy_functions.批量总结PDF文档 import 批量总结PDF文档
- function_plugins.update({
- "[仅供开发调试] 批量总结PDF文档": {
- "Color": "stop",
- "Function": 批量总结PDF文档
- },
- })
-
- # VisibleLevel=2 尚未充分测试的函数插件,放在这里
- if UserVisibleLevel >= 2:
- function_plugins.update({
- })
-
- return function_plugins
-
-
diff --git a/main.py b/main.py
index 4217304..67ee00a 100644
--- a/main.py
+++ b/main.py
@@ -1,112 +1,173 @@
import os; os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
import gradio as gr
-from predict import predict
-from toolbox import format_io, find_free_port, on_file_uploaded, on_report_generated, get_conf
+from request_llm.bridge_chatgpt import predict
+from toolbox import format_io, find_free_port, on_file_uploaded, on_report_generated, get_conf, ArgsGeneralWrapper, DummyWith
# 建议您复制一个config_private.py放自己的秘密, 如API和代理网址, 避免不小心传github被别人看到
-proxies, WEB_PORT, LLM_MODEL, CONCURRENT_COUNT, AUTHENTICATION = \
- get_conf('proxies', 'WEB_PORT', 'LLM_MODEL', 'CONCURRENT_COUNT', 'AUTHENTICATION')
-
+proxies, WEB_PORT, LLM_MODEL, CONCURRENT_COUNT, AUTHENTICATION, CHATBOT_HEIGHT, LAYOUT = \
+ get_conf('proxies', 'WEB_PORT', 'LLM_MODEL', 'CONCURRENT_COUNT', 'AUTHENTICATION', 'CHATBOT_HEIGHT', 'LAYOUT')
# 如果WEB_PORT是-1, 则随机选取WEB端口
PORT = find_free_port() if WEB_PORT <= 0 else WEB_PORT
-AUTHENTICATION = None if AUTHENTICATION == [] else AUTHENTICATION
+if not AUTHENTICATION: AUTHENTICATION = None
initial_prompt = "Serve me as a writing and programming assistant."
-title_html = """ChatGPT 学术优化
"""
+title_html = "ChatGPT 学术优化
"
+description = """代码开源和更新[地址🚀](https://github.com/binary-husky/chatgpt_academic),感谢热情的[开发者们❤️](https://github.com/binary-husky/chatgpt_academic/graphs/contributors)"""
# 问询记录, python 版本建议3.9+(越新越好)
import logging
-os.makedirs('gpt_log', exist_ok=True)
-try:logging.basicConfig(filename='gpt_log/chat_secrets.log', level=logging.INFO, encoding='utf-8')
-except:logging.basicConfig(filename='gpt_log/chat_secrets.log', level=logging.INFO)
-print('所有问询记录将自动保存在本地目录./gpt_log/chat_secrets.log, 请注意自我隐私保护哦!')
+os.makedirs("gpt_log", exist_ok=True)
+try:logging.basicConfig(filename="gpt_log/chat_secrets.log", level=logging.INFO, encoding="utf-8")
+except:logging.basicConfig(filename="gpt_log/chat_secrets.log", level=logging.INFO)
+print("所有问询记录将自动保存在本地目录./gpt_log/chat_secrets.log, 请注意自我隐私保护哦!")
# 一些普通功能模块
-from functional import get_functionals
-functional = get_functionals()
+from core_functional import get_core_functions
+functional = get_core_functions()
-# 对一些丧心病狂的实验性功能模块进行测试
-from functional_crazy import get_crazy_functionals
-crazy_functional = get_crazy_functionals()
+# 高级函数插件
+from crazy_functional import get_crazy_functions
+crazy_fns = get_crazy_functions()
# 处理markdown文本格式的转变
gr.Chatbot.postprocess = format_io
# 做一些外观色彩上的调整
-from theme import adjust_theme
+from theme import adjust_theme, advanced_css
set_theme = adjust_theme()
+# 代理与自动更新
+from check_proxy import check_proxy, auto_update
+proxy_info = check_proxy(proxies)
+
+gr_L1 = lambda: gr.Row().style()
+gr_L2 = lambda scale: gr.Column(scale=scale)
+if LAYOUT == "TOP-DOWN":
+ gr_L1 = lambda: DummyWith()
+ gr_L2 = lambda scale: gr.Row()
+ CHATBOT_HEIGHT /= 2
+
cancel_handles = []
-with gr.Blocks(theme=set_theme, analytics_enabled=False) as demo:
+with gr.Blocks(theme=set_theme, analytics_enabled=False, css=advanced_css) as demo:
gr.HTML(title_html)
- with gr.Row():
- with gr.Column(scale=2):
+ with gr_L1():
+ with gr_L2(scale=2):
chatbot = gr.Chatbot()
- chatbot.style(height=1150)
- chatbot.style()
+ chatbot.style(height=CHATBOT_HEIGHT)
history = gr.State([])
- with gr.Column(scale=1):
- with gr.Row():
- txt = gr.Textbox(show_label=False, placeholder="Input question here.").style(container=False)
- with gr.Row():
- submitBtn = gr.Button("提交", variant="primary")
- with gr.Row():
- resetBtn = gr.Button("重置", variant="secondary"); resetBtn.style(size="sm")
- stopBtn = gr.Button("停止", variant="secondary"); stopBtn.style(size="sm")
- with gr.Row():
- from check_proxy import check_proxy
- statusDisplay = gr.Markdown(f"Tip: 按Enter提交, 按Shift+Enter换行。当前模型: {LLM_MODEL} \n {check_proxy(proxies)}")
- with gr.Row():
- for k in functional:
- variant = functional[k]["Color"] if "Color" in functional[k] else "secondary"
- functional[k]["Button"] = gr.Button(k, variant=variant)
- with gr.Row():
- gr.Markdown("注意:以下“红颜色”标识的函数插件需从input区读取路径作为参数.")
- with gr.Row():
- for k in crazy_functional:
- variant = crazy_functional[k]["Color"] if "Color" in crazy_functional[k] else "secondary"
- crazy_functional[k]["Button"] = gr.Button(k, variant=variant)
- with gr.Row():
- gr.Markdown("上传本地文件,供上面的函数插件调用.")
- with gr.Row():
- file_upload = gr.Files(label='任何文件, 但推荐上传压缩文件(zip, tar)', file_count="multiple")
- system_prompt = gr.Textbox(show_label=True, placeholder=f"System Prompt", label="System prompt", value=initial_prompt).style(container=True)
- with gr.Accordion("arguments", open=False):
+ with gr_L2(scale=1):
+ with gr.Accordion("输入区", open=True) as area_input_primary:
+ with gr.Row():
+ txt = gr.Textbox(show_label=False, placeholder="Input question here.").style(container=False)
+ with gr.Row():
+ submitBtn = gr.Button("提交", variant="primary")
+ with gr.Row():
+ resetBtn = gr.Button("重置", variant="secondary"); resetBtn.style(size="sm")
+ stopBtn = gr.Button("停止", variant="secondary"); stopBtn.style(size="sm")
+ with gr.Row():
+ status = gr.Markdown(f"Tip: 按Enter提交, 按Shift+Enter换行。当前模型: {LLM_MODEL} \n {proxy_info}")
+ with gr.Accordion("基础功能区", open=True) as area_basic_fn:
+ with gr.Row():
+ for k in functional:
+ variant = functional[k]["Color"] if "Color" in functional[k] else "secondary"
+ functional[k]["Button"] = gr.Button(k, variant=variant)
+ with gr.Accordion("函数插件区", open=True) as area_crazy_fn:
+ with gr.Row():
+ gr.Markdown("注意:以下“红颜色”标识的函数插件需从输入区读取路径作为参数.")
+ with gr.Row():
+ for k in crazy_fns:
+ if not crazy_fns[k].get("AsButton", True): continue
+ variant = crazy_fns[k]["Color"] if "Color" in crazy_fns[k] else "secondary"
+ crazy_fns[k]["Button"] = gr.Button(k, variant=variant)
+ crazy_fns[k]["Button"].style(size="sm")
+ with gr.Row():
+ with gr.Accordion("更多函数插件", open=True):
+ dropdown_fn_list = [k for k in crazy_fns.keys() if not crazy_fns[k].get("AsButton", True)]
+ with gr.Column(scale=1):
+ dropdown = gr.Dropdown(dropdown_fn_list, value=r"打开插件列表", label="").style(container=False)
+ with gr.Column(scale=1):
+ switchy_bt = gr.Button(r"请先从插件列表中选择", variant="secondary")
+ with gr.Row():
+ with gr.Accordion("点击展开“文件上传区”。上传本地文件可供红色函数插件调用。", open=False) as area_file_up:
+ file_upload = gr.Files(label="任何文件, 但推荐上传压缩文件(zip, tar)", file_count="multiple")
+ with gr.Accordion("展开SysPrompt & 交互界面布局 & Github地址", open=(LAYOUT == "TOP-DOWN")):
+ system_prompt = gr.Textbox(show_label=True, placeholder=f"System Prompt", label="System prompt", value=initial_prompt)
top_p = gr.Slider(minimum=-0, maximum=1.0, value=1.0, step=0.01,interactive=True, label="Top-p (nucleus sampling)",)
temperature = gr.Slider(minimum=-0, maximum=2.0, value=1.0, step=0.01, interactive=True, label="Temperature",)
-
- predict_args = dict(fn=predict, inputs=[txt, top_p, temperature, chatbot, history, system_prompt], outputs=[chatbot, history, statusDisplay], show_progress=True)
- empty_txt_args = dict(fn=lambda: "", inputs=[], outputs=[txt]) # 用于在提交后清空输入栏
-
+ checkboxes = gr.CheckboxGroup(["基础功能区", "函数插件区", "底部输入区"], value=["基础功能区", "函数插件区"], label="显示/隐藏功能区")
+ gr.Markdown(description)
+ with gr.Accordion("备选输入区", open=True, visible=False) as area_input_secondary:
+ with gr.Row():
+ txt2 = gr.Textbox(show_label=False, placeholder="Input question here.", label="输入区2").style(container=False)
+ with gr.Row():
+ submitBtn2 = gr.Button("提交", variant="primary")
+ with gr.Row():
+ resetBtn2 = gr.Button("重置", variant="secondary"); resetBtn.style(size="sm")
+ stopBtn2 = gr.Button("停止", variant="secondary"); stopBtn.style(size="sm")
+ # 功能区显示开关与功能区的互动
+ def fn_area_visibility(a):
+ ret = {}
+ ret.update({area_basic_fn: gr.update(visible=("基础功能区" in a))})
+ ret.update({area_crazy_fn: gr.update(visible=("函数插件区" in a))})
+ ret.update({area_input_primary: gr.update(visible=("底部输入区" not in a))})
+ ret.update({area_input_secondary: gr.update(visible=("底部输入区" in a))})
+ if "底部输入区" in a: ret.update({txt: gr.update(value="")})
+ return ret
+ checkboxes.select(fn_area_visibility, [checkboxes], [area_basic_fn, area_crazy_fn, area_input_primary, area_input_secondary, txt, txt2] )
+ # 整理反复出现的控件句柄组合
+ input_combo = [txt, txt2, top_p, temperature, chatbot, history, system_prompt]
+ output_combo = [chatbot, history, status]
+ predict_args = dict(fn=ArgsGeneralWrapper(predict), inputs=input_combo, outputs=output_combo)
+ # 提交按钮、重置按钮
cancel_handles.append(txt.submit(**predict_args))
- # txt.submit(**empty_txt_args) 在提交后清空输入栏
+ cancel_handles.append(txt2.submit(**predict_args))
cancel_handles.append(submitBtn.click(**predict_args))
- # submitBtn.click(**empty_txt_args) 在提交后清空输入栏
- resetBtn.click(lambda: ([], [], "已重置"), None, [chatbot, history, statusDisplay])
+ cancel_handles.append(submitBtn2.click(**predict_args))
+ resetBtn.click(lambda: ([], [], "已重置"), None, output_combo)
+ resetBtn2.click(lambda: ([], [], "已重置"), None, output_combo)
+ # 基础功能区的回调函数注册
for k in functional:
- click_handle = functional[k]["Button"].click(predict,
- [txt, top_p, temperature, chatbot, history, system_prompt, gr.State(True), gr.State(k)], [chatbot, history, statusDisplay], show_progress=True)
+ click_handle = functional[k]["Button"].click(fn=ArgsGeneralWrapper(predict), inputs=[*input_combo, gr.State(True), gr.State(k)], outputs=output_combo)
cancel_handles.append(click_handle)
+ # 文件上传区,接收文件后与chatbot的互动
file_upload.upload(on_file_uploaded, [file_upload, chatbot, txt], [chatbot, txt])
- for k in crazy_functional:
- click_handle = crazy_functional[k]["Button"].click(crazy_functional[k]["Function"],
- [txt, top_p, temperature, chatbot, history, system_prompt, gr.State(PORT)], [chatbot, history, statusDisplay]
- )
- try: click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
- except: pass
+ # 函数插件-固定按钮区
+ for k in crazy_fns:
+ if not crazy_fns[k].get("AsButton", True): continue
+ click_handle = crazy_fns[k]["Button"].click(ArgsGeneralWrapper(crazy_fns[k]["Function"]), [*input_combo, gr.State(PORT)], output_combo)
+ click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
cancel_handles.append(click_handle)
+ # 函数插件-下拉菜单与随变按钮的互动
+ def on_dropdown_changed(k):
+ variant = crazy_fns[k]["Color"] if "Color" in crazy_fns[k] else "secondary"
+ return {switchy_bt: gr.update(value=k, variant=variant)}
+ dropdown.select(on_dropdown_changed, [dropdown], [switchy_bt] )
+ # 随变按钮的回调函数注册
+ def route(k, *args, **kwargs):
+ if k in [r"打开插件列表", r"请先从插件列表中选择"]: return
+ yield from ArgsGeneralWrapper(crazy_fns[k]["Function"])(*args, **kwargs)
+ click_handle = switchy_bt.click(route,[switchy_bt, *input_combo, gr.State(PORT)], output_combo)
+ click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
+ # def expand_file_area(file_upload, area_file_up):
+ # if len(file_upload)>0: return {area_file_up: gr.update(open=True)}
+ # click_handle.then(expand_file_area, [file_upload, area_file_up], [area_file_up])
+ cancel_handles.append(click_handle)
+ # 终止按钮的回调函数注册
stopBtn.click(fn=None, inputs=None, outputs=None, cancels=cancel_handles)
-
+ stopBtn2.click(fn=None, inputs=None, outputs=None, cancels=cancel_handles)
# gradio的inbrowser触发不太稳定,回滚代码到原始的浏览器打开函数
def auto_opentab_delay():
import threading, webbrowser, time
- print(f"URL http://localhost:{PORT}")
+ print(f"如果浏览器没有自动打开,请复制并转到以下URL:")
+ print(f"\t(亮色主体): http://localhost:{PORT}")
+ print(f"\t(暗色主体): http://localhost:{PORT}/?__dark-theme=true")
def open():
time.sleep(2)
- webbrowser.open_new_tab(f'http://localhost:{PORT}')
- t = threading.Thread(target=open)
- t.daemon = True; t.start()
+ try: auto_update() # 检查新版本
+ except: pass
+ webbrowser.open_new_tab(f"http://localhost:{PORT}/?__dark-theme=true")
+ threading.Thread(target=open, name="open-browser", daemon=True).start()
auto_opentab_delay()
demo.title = "ChatGPT 学术优化"
diff --git a/project_self_analysis.md b/project_self_analysis.md
deleted file mode 100644
index c817421..0000000
--- a/project_self_analysis.md
+++ /dev/null
@@ -1,122 +0,0 @@
-# chatgpt-academic项目分析报告
-(Author补充:以下分析均由本项目调用ChatGPT一键生成,如果有不准确的地方全怪GPT)
-
-## [0/10] 程序摘要: check_proxy.py
-
-这个程序是一个用来检查代理服务器是否有效的 Python 程序代码。程序文件名为 check_proxy.py。其中定义了一个函数 check_proxy,该函数接收一个代理配置信息 proxies,使用 requests 库向一个代理服务器发送请求,获取该代理的所在地信息并返回。如果请求超时或者异常,该函数将返回一个代理无效的结果。
-
-程序代码分为两个部分,首先是 check_proxy 函数的定义部分,其次是程序文件的入口部分,在该部分代码中,程序从 config_private.py 文件或者 config.py 文件中加载代理配置信息,然后调用 check_proxy 函数来检测代理服务器是否有效。如果配置文件 config_private.py 存在,则会加载其中的代理配置信息,否则会从 config.py 文件中读取。
-
-## [1/10] 程序摘要: config.py
-
-本程序文件名为config.py,主要功能是存储应用所需的常量和配置信息。
-
-其中,包含了应用所需的OpenAI API密钥、API接口地址、网络代理设置、超时设置、网络端口和OpenAI模型选择等信息,在运行应用前需要进行相应的配置。在未配置网络代理时,程序给出了相应的警告提示。
-
-此外,还包含了一个检查函数,用于检查是否忘记修改API密钥。
-
-总之,config.py文件是应用中的一个重要配置文件,用来存储应用所需的常量和配置信息,需要在应用运行前进行相应的配置。
-
-## [2/10] 程序摘要: config_private.py
-
-该文件是一个配置文件,命名为config_private.py。它是一个Python脚本,用于配置OpenAI的API密钥、模型和其它相关设置。该配置文件还可以设置是否使用代理。如果使用代理,需要设置代理协议、地址和端口。在设置代理之后,该文件还包括一些用于测试代理是否正常工作的代码。该文件还包括超时时间、随机端口、重试次数等设置。在文件末尾,还有一个检查代码,如果没有更改API密钥,则抛出异常。
-
-## [3/10] 程序摘要: functional.py
-
-该程序文件名为 functional.py,其中包含一个名为 get_functionals 的函数,该函数返回一个字典,该字典包含了各种翻译、校对等功能的名称、前缀、后缀以及默认按钮颜色等信息。具体功能包括:英语学术润色、中文学术润色、查找语法错误、中英互译、中译英、学术中译英、英译中、解释代码等。该程序的作用为提供各种翻译、校对等功能的模板,以便后续程序可以直接调用。
-
-(Author补充:这个文件汇总了模块化的Prompt调用,如果发现了新的好用Prompt,别藏着哦^_^速速PR)
-
-
-## [4/10] 程序摘要: functional_crazy.py
-
-这个程序文件 functional_crazy.py 导入了一些 python 模块,并提供了一个函数 get_crazy_functionals(),该函数返回不同实验功能的描述和函数。其中,使用的的模块包括:
-
-- crazy_functions.读文章写摘要 中的 读文章写摘要
-- crazy_functions.生成函数注释 中的 批量生成函数注释
-- crazy_functions.解析项目源代码 中的 解析项目本身、解析一个Python项目、解析一个C项目的头文件、解析一个C项目
-- crazy_functions.高级功能函数模板 中的 高阶功能模板函数
-
-返回的实验功能函数包括:
-
-- "[实验] 请解析并解构此项目本身",包含函数:解析项目本身
-- "[实验] 解析整个py项目(配合input输入框)",包含函数:解析一个Python项目
-- "[实验] 解析整个C++项目头文件(配合input输入框)",包含函数:解析一个C项目的头文件
-- "[实验] 解析整个C++项目(配合input输入框)",包含函数:解析一个C项目
-- "[实验] 读tex论文写摘要(配合input输入框)",包含函数:读文章写摘要
-- "[实验] 批量生成函数注释(配合input输入框)",包含函数:批量生成函数注释
-- "[实验] 实验功能函数模板",包含函数:高阶功能模板函数
-
-这些函数用于系统开发和测试,方便开发者进行特定程序语言后台功能开发的测试和实验,增加系统可靠稳定性和用户友好性。
-
-(Author补充:这个文件汇总了模块化的函数,如此设计以方便任何新功能的加入)
-
-## [5/10] 程序摘要: main.py
-
-该程序是一个基于Gradio框架的聊天机器人应用程序。用户可以通过输入问题来获取答案,并与聊天机器人进行对话。该应用程序还集成了一些实验性功能模块,用户可以通过上传本地文件或点击相关按钮来使用这些模块。程序还可以生成对话日志,并且具有一些外观上的调整。在运行时,它会自动打开一个网页并在本地启动服务器。
-
-
-## [6/10] 程序摘要: predict.py
-
-该程序文件名为predict.py,主要是针对一个基于ChatGPT的聊天机器人进行交互和预测。
-
-第一部分是导入所需的库和配置文件。
-
-第二部分是一个用于获取Openai返回的完整错误信息的函数。
-
-第三部分是用于一次性完成向ChatGPT发送请求和等待回复的函数。
-
-第四部分是用于基础的对话功能的函数,通过stream参数可以选择是否显示中间的过程。
-
-第五部分是用于整合所需信息和选择LLM模型生成的HTTP请求。
-
-(Author补充:主要是predict_no_ui和predict两个函数。前者不用stream,方便、高效、易用。后者用stream,展现效果好。)
-
-## [7/10] 程序摘要: show_math.py
-
-这是一个名为show_math.py的Python程序文件,主要用于将Markdown-LaTeX混合文本转换为HTML格式,并包括MathML数学公式。程序使用latex2mathml.converter库将LaTeX公式转换为MathML格式,并使用正则表达式递归地翻译输入的Markdown-LaTeX混合文本。程序包括转换成双美元符号($$)形式、转换成单美元符号($)形式、转换成\[\]形式以及转换成\(\)形式的LaTeX数学公式。如果转换中出现错误,程序将返回相应的错误消息。
-
-## [8/10] 程序摘要: theme.py
-
-这是一个名为theme.py的程序文件,用于设置Gradio界面的颜色和字体主题。该文件中定义了一个名为adjust_theme()的函数,其作用是返回一个Gradio theme对象,设置了Gradio界面的颜色和字体主题。在该函数里面,使用了Graido可用的颜色列表,主要参数包括primary_hue、neutral_hue、font和font_mono等,用于设置Gradio界面的主题色调、字体等。另外,该函数还实现了一些参数的自定义,如input_background_fill_dark、button_transition、button_shadow_hover等,用于设置Gradio界面的渐变、阴影等特效。如果Gradio版本过于陈旧,该函数会抛出异常并返回None。
-
-## [9/10] 程序摘要: toolbox.py
-
-该文件为Python程序文件,文件名为toolbox.py。主要功能包括:
-
-1. 导入markdown、mdtex2html、threading、functools等模块。
-2. 定义函数predict_no_ui_but_counting_down,用于生成对话。
-3. 定义函数write_results_to_file,用于将对话记录生成Markdown文件。
-4. 定义函数regular_txt_to_markdown,将普通文本转换为Markdown格式的文本。
-5. 定义装饰器函数CatchException,用于捕获函数执行异常并返回生成器。
-6. 定义函数report_execption,用于向chatbot中添加错误信息。
-7. 定义函数text_divide_paragraph,用于将文本按照段落分隔符分割开,生成带有段落标签的HTML代码。
-8. 定义函数markdown_convertion,用于将Markdown格式的文本转换为HTML格式。
-9. 定义函数format_io,用于将输入和输出解析为HTML格式。
-10. 定义函数find_free_port,用于返回当前系统中可用的未使用端口。
-11. 定义函数extract_archive,用于解压归档文件。
-12. 定义函数find_recent_files,用于查找最近创建的文件。
-13. 定义函数on_file_uploaded,用于处理上传文件的操作。
-14. 定义函数on_report_generated,用于处理生成报告文件的操作。
-
-## 程序的整体功能和构架做出概括。然后用一张markdown表格整理每个文件的功能。
-
-这是一个基于Gradio框架的聊天机器人应用,支持通过文本聊天来获取答案,并可以使用一系列实验性功能模块,例如生成函数注释、解析项目源代码、读取Latex论文写摘要等。 程序架构分为前端和后端两个部分。前端使用Gradio实现,包括用户输入区域、应答区域、按钮、调用方式等。后端使用Python实现,包括聊天机器人模型、实验性功能模块、模板模块、管理模块、主程序模块等。
-
-每个程序文件的功能如下:
-
-| 文件名 | 功能描述 |
-|:----:|:----:|
-| check_proxy.py | 检查代理服务器是否有效 |
-| config.py | 存储应用所需的常量和配置信息 |
-| config_private.py | 存储Openai的API密钥、模型和其他相关设置 |
-| functional.py | 提供各种翻译、校对等实用模板 |
-| functional_crazy.py | 提供一些实验性质的高级功能 |
-| main.py | 基于Gradio框架的聊天机器人应用程序的主程序 |
-| predict.py | 用于chatbot预测方案创建,向ChatGPT发送请求和获取回复 |
-| show_math.py | 将Markdown-LaTeX混合文本转换为HTML格式,并包括MathML数学公式 |
-| theme.py | 设置Gradio界面的颜色和字体主题 |
-| toolbox.py | 定义一系列工具函数,用于对输入输出进行格式转换、文件操作、异常捕捉和处理等 |
-
-这些程序文件共同组成了一个聊天机器人应用程序的前端和后端实现,使用户可以方便地进行聊天,并可以使用相应的实验功能模块。
-
diff --git a/request_llm/README.md b/request_llm/README.md
new file mode 100644
index 0000000..c66cc15
--- /dev/null
+++ b/request_llm/README.md
@@ -0,0 +1,36 @@
+# 如何使用其他大语言模型(dev分支测试中)
+
+## 1. 先运行text-generation
+``` sh
+# 下载模型( text-generation 这么牛的项目,别忘了给人家star )
+git clone https://github.com/oobabooga/text-generation-webui.git
+
+# 安装text-generation的额外依赖
+pip install accelerate bitsandbytes flexgen gradio llamacpp markdown numpy peft requests rwkv safetensors sentencepiece tqdm datasets git+https://github.com/huggingface/transformers
+
+# 切换路径
+cd text-generation-webui
+
+# 下载模型
+python download-model.py facebook/galactica-1.3b
+# 其他可选如 facebook/opt-1.3b
+# facebook/galactica-6.7b
+# facebook/galactica-120b
+# facebook/pygmalion-1.3b 等
+# 详情见 https://github.com/oobabooga/text-generation-webui
+
+# 启动text-generation,注意把模型的斜杠改成下划线
+python server.py --cpu --listen --listen-port 7860 --model facebook_galactica-1.3b
+```
+
+## 2. 修改config.py
+``` sh
+# LLM_MODEL格式较复杂 TGUI:[模型]@[ws地址]:[ws端口] , 端口要和上面给定的端口一致
+LLM_MODEL = "TGUI:galactica-1.3b@localhost:7860"
+```
+
+## 3. 运行!
+``` sh
+cd chatgpt-academic
+python main.py
+```
diff --git a/predict.py b/request_llm/bridge_chatgpt.py
similarity index 76%
rename from predict.py
rename to request_llm/bridge_chatgpt.py
index 84036bc..c27a4ec 100644
--- a/predict.py
+++ b/request_llm/bridge_chatgpt.py
@@ -12,6 +12,7 @@
"""
import json
+import time
import gradio as gr
import logging
import traceback
@@ -71,12 +72,22 @@ def predict_no_ui(inputs, top_p, temperature, history=[], sys_prompt=""):
raise ConnectionAbortedError("Json解析不合常规,可能是文本过长" + response.text)
-def predict_no_ui_long_connection(inputs, top_p, temperature, history=[], sys_prompt=""):
+def predict_no_ui_long_connection(inputs, top_p, temperature, history=[], sys_prompt="", observe_window=None):
"""
- 发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免有人中途掐网线。
+ 发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免中途网线被掐。
+ inputs:
+ 是本次问询的输入
+ sys_prompt:
+ 系统静默prompt
+ top_p, temperature:
+ chatGPT的内部调优参数
+ history:
+ 是之前的对话列表
+ observe_window = None:
+ 用于负责跨越线程传递已经输出的部分,大部分时候仅仅为了fancy的视觉效果,留空即可。observe_window[0]:观测窗。observe_window[1]:看门狗
"""
+ watch_dog_patience = 5 # 看门狗的耐心, 设置5秒即可
headers, payload = generate_payload(inputs, top_p, temperature, history, system_prompt=sys_prompt, stream=True)
-
retry = 0
while True:
try:
@@ -96,13 +107,28 @@ def predict_no_ui_long_connection(inputs, top_p, temperature, history=[], sys_pr
except StopIteration: break
if len(chunk)==0: continue
if not chunk.startswith('data:'):
- chunk = get_full_error(chunk.encode('utf8'), stream_response)
- raise ConnectionAbortedError("OpenAI拒绝了请求:" + chunk.decode())
- delta = json.loads(chunk.lstrip('data:'))['choices'][0]["delta"]
+ error_msg = get_full_error(chunk.encode('utf8'), stream_response).decode()
+ if "reduce the length" in error_msg:
+ raise ConnectionAbortedError("OpenAI拒绝了请求:" + error_msg)
+ else:
+ raise RuntimeError("OpenAI拒绝了请求:" + error_msg)
+ json_data = json.loads(chunk.lstrip('data:'))['choices'][0]
+ delta = json_data["delta"]
if len(delta) == 0: break
if "role" in delta: continue
- if "content" in delta: result += delta["content"]; print(delta["content"], end='')
+ if "content" in delta:
+ result += delta["content"]
+ print(delta["content"], end='')
+ if observe_window is not None:
+ # 观测窗,把已经获取的数据显示出去
+ if len(observe_window) >= 1: observe_window[0] += delta["content"]
+ # 看门狗,如果超过期限没有喂狗,则终止
+ if len(observe_window) >= 2:
+ if (time.time()-observe_window[1]) > watch_dog_patience:
+ raise RuntimeError("程序终止。")
else: raise RuntimeError("意外Json结构:"+delta)
+ if json_data['finish_reason'] == 'length':
+ raise ConnectionAbortedError("正常结束,但显示Token不足,导致输出不完整,请削减单次输入的文本量。")
return result
@@ -118,11 +144,11 @@ def predict(inputs, top_p, temperature, chatbot=[], history=[], system_prompt=''
additional_fn代表点击的哪个按钮,按钮见functional.py
"""
if additional_fn is not None:
- import functional
- importlib.reload(functional) # 热更新prompt
- functional = functional.get_functionals()
- if "PreProcess" in functional[additional_fn]: inputs = functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话)
- inputs = functional[additional_fn]["Prefix"] + inputs + functional[additional_fn]["Suffix"]
+ import core_functional
+ importlib.reload(core_functional) # 热更新prompt
+ core_functional = core_functional.get_core_functions()
+ if "PreProcess" in core_functional[additional_fn]: inputs = core_functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话)
+ inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"]
if stream:
raw_input = inputs
@@ -179,15 +205,17 @@ def predict(inputs, top_p, temperature, chatbot=[], history=[], system_prompt=''
chunk = get_full_error(chunk, stream_response)
error_msg = chunk.decode()
if "reduce the length" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Input (or history) is too long, please reduce input or clear history by refreshing this page.")
- history = []
+ chatbot[-1] = (chatbot[-1][0], "[Local Message] Reduce the length. 本次输入过长,或历史数据过长. 历史缓存数据现已释放,您可以请再次尝试.")
+ history = [] # 清除历史
elif "Incorrect API key" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key provided.")
+ chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key. OpenAI以提供了不正确的API_KEY为由,拒绝服务.")
+ elif "exceeded your current quota" in error_msg:
+ chatbot[-1] = (chatbot[-1][0], "[Local Message] You exceeded your current quota. OpenAI以账户额度不足为由,拒绝服务.")
else:
from toolbox import regular_txt_to_markdown
- tb_str = regular_txt_to_markdown(traceback.format_exc())
- chatbot[-1] = (chatbot[-1][0], f"[Local Message] Json Error \n\n {tb_str} \n\n {regular_txt_to_markdown(chunk.decode()[4:])}")
- yield chatbot, history, "Json解析不合常规" + error_msg
+ tb_str = '```\n' + traceback.format_exc() + '```'
+ chatbot[-1] = (chatbot[-1][0], f"[Local Message] 异常 \n\n{tb_str} \n\n{regular_txt_to_markdown(chunk.decode()[4:])}")
+ yield chatbot, history, "Json异常" + error_msg
return
def generate_payload(inputs, top_p, temperature, history, system_prompt, stream):
diff --git a/request_llm/bridge_tgui.py b/request_llm/bridge_tgui.py
new file mode 100644
index 0000000..fceaa56
--- /dev/null
+++ b/request_llm/bridge_tgui.py
@@ -0,0 +1,167 @@
+'''
+Contributed by SagsMug. Modified by binary-husky
+https://github.com/oobabooga/text-generation-webui/pull/175
+'''
+
+import asyncio
+import json
+import random
+import string
+import websockets
+import logging
+import time
+import threading
+import importlib
+from toolbox import get_conf
+LLM_MODEL, = get_conf('LLM_MODEL')
+
+# "TGUI:galactica-1.3b@localhost:7860"
+model_name, addr_port = LLM_MODEL.split('@')
+assert ':' in addr_port, "LLM_MODEL 格式不正确!" + LLM_MODEL
+addr, port = addr_port.split(':')
+
+def random_hash():
+ letters = string.ascii_lowercase + string.digits
+ return ''.join(random.choice(letters) for i in range(9))
+
+async def run(context, max_token=512):
+ params = {
+ 'max_new_tokens': max_token,
+ 'do_sample': True,
+ 'temperature': 0.5,
+ 'top_p': 0.9,
+ 'typical_p': 1,
+ 'repetition_penalty': 1.05,
+ 'encoder_repetition_penalty': 1.0,
+ 'top_k': 0,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0,
+ 'length_penalty': 1,
+ 'early_stopping': True,
+ 'seed': -1,
+ }
+ session = random_hash()
+
+ async with websockets.connect(f"ws://{addr}:{port}/queue/join") as websocket:
+ while content := json.loads(await websocket.recv()):
+ #Python3.10 syntax, replace with if elif on older
+ if content["msg"] == "send_hash":
+ await websocket.send(json.dumps({
+ "session_hash": session,
+ "fn_index": 12
+ }))
+ elif content["msg"] == "estimation":
+ pass
+ elif content["msg"] == "send_data":
+ await websocket.send(json.dumps({
+ "session_hash": session,
+ "fn_index": 12,
+ "data": [
+ context,
+ params['max_new_tokens'],
+ params['do_sample'],
+ params['temperature'],
+ params['top_p'],
+ params['typical_p'],
+ params['repetition_penalty'],
+ params['encoder_repetition_penalty'],
+ params['top_k'],
+ params['min_length'],
+ params['no_repeat_ngram_size'],
+ params['num_beams'],
+ params['penalty_alpha'],
+ params['length_penalty'],
+ params['early_stopping'],
+ params['seed'],
+ ]
+ }))
+ elif content["msg"] == "process_starts":
+ pass
+ elif content["msg"] in ["process_generating", "process_completed"]:
+ yield content["output"]["data"][0]
+ # You can search for your desired end indicator and
+ # stop generation by closing the websocket here
+ if (content["msg"] == "process_completed"):
+ break
+
+
+
+
+
+def predict_tgui(inputs, top_p, temperature, chatbot=[], history=[], system_prompt='', stream = True, additional_fn=None):
+ """
+ 发送至chatGPT,流式获取输出。
+ 用于基础的对话功能。
+ inputs 是本次问询的输入
+ top_p, temperature是chatGPT的内部调优参数
+ history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
+ chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
+ additional_fn代表点击的哪个按钮,按钮见functional.py
+ """
+ if additional_fn is not None:
+ import core_functional
+ importlib.reload(core_functional) # 热更新prompt
+ core_functional = core_functional.get_core_functions()
+ if "PreProcess" in core_functional[additional_fn]: inputs = core_functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话)
+ inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"]
+
+ raw_input = "What I would like to say is the following: " + inputs
+ logging.info(f'[raw_input] {raw_input}')
+ history.extend([inputs, ""])
+ chatbot.append([inputs, ""])
+ yield chatbot, history, "等待响应"
+
+ prompt = inputs
+ tgui_say = ""
+
+ mutable = ["", time.time()]
+ def run_coorotine(mutable):
+ async def get_result(mutable):
+ async for response in run(prompt):
+ print(response[len(mutable[0]):])
+ mutable[0] = response
+ if (time.time() - mutable[1]) > 3:
+ print('exit when no listener')
+ break
+ asyncio.run(get_result(mutable))
+
+ thread_listen = threading.Thread(target=run_coorotine, args=(mutable,), daemon=True)
+ thread_listen.start()
+
+ while thread_listen.is_alive():
+ time.sleep(1)
+ mutable[1] = time.time()
+ # Print intermediate steps
+ if tgui_say != mutable[0]:
+ tgui_say = mutable[0]
+ history[-1] = tgui_say
+ chatbot[-1] = (history[-2], history[-1])
+ yield chatbot, history, "status_text"
+
+ logging.info(f'[response] {tgui_say}')
+
+
+
+def predict_tgui_no_ui(inputs, top_p, temperature, history=[], sys_prompt=""):
+ raw_input = "What I would like to say is the following: " + inputs
+ prompt = inputs
+ tgui_say = ""
+ mutable = ["", time.time()]
+ def run_coorotine(mutable):
+ async def get_result(mutable):
+ async for response in run(prompt, max_token=20):
+ print(response[len(mutable[0]):])
+ mutable[0] = response
+ if (time.time() - mutable[1]) > 3:
+ print('exit when no listener')
+ break
+ asyncio.run(get_result(mutable))
+ thread_listen = threading.Thread(target=run_coorotine, args=(mutable,))
+ thread_listen.start()
+ while thread_listen.is_alive():
+ time.sleep(1)
+ mutable[1] = time.time()
+ tgui_say = mutable[0]
+ return tgui_say
diff --git a/requirements.txt b/requirements.txt
index 84ced64..d864593 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,3 +1,12 @@
gradio>=3.23
requests[socks]
+transformers
+python-markdown-math
+beautifulsoup4
+latex2mathml
mdtex2html
+tiktoken
+Markdown
+pymupdf
+openai
+numpy
\ No newline at end of file
diff --git a/self_analysis.md b/self_analysis.md
new file mode 100644
index 0000000..acdcaa7
--- /dev/null
+++ b/self_analysis.md
@@ -0,0 +1,262 @@
+# chatgpt-academic项目自译解报告
+(Author补充:以下分析均由本项目调用ChatGPT一键生成,如果有不准确的地方,全怪GPT😄)
+
+## 对程序的整体功能和构架做出概括。然后用一张markdown表格整理每个文件的功能(包括'check_proxy.py', 'config.py'等)。
+
+整体概括:
+
+该程序是一个基于自然语言处理和机器学习的科学论文辅助工具,主要功能包括聊天机器人、批量总结PDF文档、批量翻译PDF文档、生成函数注释、解析项目源代码等。程序基于 Gradio 构建 Web 服务,并集成了代理和自动更新功能,提高了用户的使用体验。
+
+文件功能表格:
+
+| 文件名称 | 功能 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| .\check_proxy.py | 检查代理设置功能。 |
+| .\config.py | 配置文件,存储程序的基本设置。 |
+| .\config_private.py | 存储代理网络地址的文件。 |
+| .\core_functional.py | 主要的程序逻辑,包括聊天机器人和文件处理。 |
+| .\cradle.py | 程序入口,初始化程序和启动 Web 服务。 |
+| .\crazy_functional.py | 辅助程序功能,包括PDF文档处理、代码处理、函数注释生成等。 |
+| .\main.py | 包含聊天机器人的具体实现。 |
+| .\show_math.py | 处理 LaTeX 公式的函数。 |
+| .\theme.py | 存储 Gradio Web 服务的 CSS 样式文件。 |
+| .\toolbox.py | 提供了一系列工具函数,包括文件读写、网页抓取、解析函数参数、生成 HTML 等。 |
+| ./crazy_functions/crazy_utils.py | 提供各种工具函数,如解析字符串、清洗文本、清理目录结构等。 |
+| ./crazy_functions/\_\_init\_\_.py | crazy_functions 模块的入口文件。 |
+| ./crazy_functions/下载arxiv论文翻译摘要.py | 对 arxiv.org 上的 PDF 论文进行下载和翻译。 |
+| ./crazy_functions/代码重写为全英文_多线程.py | 将代码文件中的中文注释和字符串替换为英文。 |
+| ./crazy_functions/总结word文档.py | 读取 Word 文档并生成摘要。 |
+| ./crazy_functions/批量总结PDF文档.py | 批量读取 PDF 文件并生成摘要。 |
+| ./crazy_functions/批量总结PDF文档pdfminer.py | 使用 pdfminer 库进行 PDF 文件处理。 |
+| ./crazy_functions/批量翻译PDF文档_多线程.py | 使用多线程技术批量翻译 PDF 文件。 |
+| ./crazy_functions/生成函数注释.py | 给 Python 函数自动生成说明文档。 |
+| ./crazy_functions/解析项目源代码.py | 解析项目中的源代码,提取注释和函数名等信息。 |
+| ./crazy_functions/读文章写摘要.py | 读取多个文本文件并生成对应的摘要。 |
+| ./crazy_functions/高级功能函数模板.py | 使用 GPT 模型进行文本处理。 |
+
+
+
+## [0/22] 程序概述: check_proxy.py
+
+该程序的文件名是check_proxy.py,主要有两个函数:check_proxy和auto_update。
+
+check_proxy函数中会借助requests库向一个IP查询API发送请求,并返回该IP的地理位置信息。同时根据返回的数据来判断代理是否有效。
+
+auto_update函数主要用于检查程序更新,会从Github获取程序最新的版本信息,如果当前版本和最新版本相差较大,则会提示用户进行更新。该函数中也会依赖requests库进行网络请求。
+
+在程序的开头,还添加了一句防止代理网络影响的代码。程序使用了自己编写的toolbox模块中的get_conf函数来获取代理设置。
+
+## [1/22] 程序概述: config.py
+
+该程序文件是一个Python模块,文件名为config.py。该模块包含了一些变量和配置选项,用于配置一个OpenAI的聊天机器人。具体的配置选项如下:
+
+- API_KEY: 密钥,用于连接OpenAI的API。需要填写有效的API密钥。
+- USE_PROXY: 是否使用代理。如果需要使用代理,需要将其改为True。
+- proxies: 代理的协议、地址和端口。
+- CHATBOT_HEIGHT: 聊天机器人对话框的高度。
+- LAYOUT: 聊天机器人对话框的布局,默认为左右布局。
+- TIMEOUT_SECONDS: 发送请求到OpenAI后,等待多久判定为超时。
+- WEB_PORT: 网页的端口,-1代表随机端口。
+- MAX_RETRY: 如果OpenAI不响应(网络卡顿、代理失败、KEY失效),重试的次数限制。
+- LLM_MODEL: OpenAI模型选择,目前只对某些用户开放的gpt4。
+- API_URL: OpenAI的API地址。
+- CONCURRENT_COUNT: 使用的线程数。
+- AUTHENTICATION: 用户名和密码,如果需要。
+
+## [2/22] 程序概述: config_private.py
+
+该程序文件名为config_private.py,包含了API_KEY的设置和代理的配置。使用了一个名为API_KEY的常量来存储私人的API密钥。此外,还有一个名为USE_PROXY的常量来标记是否需要使用代理。如果需要代理,则使用了一个名为proxies的字典来存储代理网络的地址,其中包括协议类型、地址和端口。
+
+## [3/22] 程序概述: core_functional.py
+
+该程序文件名为`core_functional.py`,主要是定义了一些核心功能函数,包括英语和中文学术润色、查找语法错误、中译英、学术中英互译、英译中、找图片和解释代码等。每个功能都有一个`Prefix`属性和`Suffix`属性,`Prefix`是指在用户输入的任务前面要显示的文本,`Suffix`是指在任务后面要显示的文本。此外,还有一个`Color`属性指示按钮的颜色,以及一个`PreProcess`函数表示对输入进行预处理的函数。
+
+## [4/22] 程序概述: cradle.py
+
+该程序文件名为cradle.py,主要功能是检测当前版本与远程最新版本是否一致,如果不一致则输出新版本信息并提示更新。其流程大致如下:
+
+1. 导入相关模块与自定义工具箱函数get_conf
+2. 读取配置文件中的代理proxies
+3. 使用requests模块请求远程版本信息(url为https://raw.githubusercontent.com/binary-husky/chatgpt_academic/master/version)并加载为json格式
+4. 获取远程版本号、是否显示新功能信息、新功能内容
+5. 读取本地版本文件version并加载为json格式
+6. 获取当前版本号
+7. 比较当前版本与远程版本,如果远程版本号比当前版本号高0.05以上,则输出新版本信息并提示更新
+8. 如果不需要更新,则直接返回
+
+## [5/22] 程序概述: crazy_functional.py
+
+该程序文件名为.\crazy_functional.py,主要定义了一个名为get_crazy_functions()的函数,该函数返回一个字典类型的变量function_plugins,其中包含了一些函数插件。
+
+一些重要的函数插件包括:
+
+- 读文章写摘要:可以自动读取Tex格式的论文,并生成其摘要。
+
+- 批量生成函数注释:可以批量生成Python函数的文档注释。
+
+- 解析项目源代码:可以解析Python、C++、Golang、Java及React项目的源代码。
+
+- 批量总结PDF文档:可以对PDF文档进行批量总结,以提取其中的关键信息。
+
+- 一键下载arxiv论文并翻译摘要:可以自动下载arxiv.org网站上的PDF论文,并翻译生成其摘要。
+
+- 批量翻译PDF文档(多线程):可以对PDF文档进行批量翻译,并使用多线程方式提高翻译效率。
+
+## [6/22] 程序概述: main.py
+
+本程序为一个基于 Gradio 和 GPT-3 的交互式聊天机器人,文件名为 main.py。其中主要功能包括:
+
+1. 使用 Gradio 建立 Web 界面,实现用户与聊天机器人的交互;
+2. 通过 bridge_chatgpt 模块,利用 GPT-3 模型实现聊天机器人的逻辑;
+3. 提供一些基础功能和高级函数插件,用户可以通过按钮选择使用;
+4. 提供文档格式转变、外观调整以及代理和自动更新等功能。
+
+程序的主要流程为:
+
+1. 导入所需的库和模块,并通过 get_conf 函数获取配置信息;
+2. 设置 Gradio 界面的各个组件,包括聊天窗口、输入区、功能区、函数插件区等;
+3. 注册各个组件的回调函数,包括用户输入、信号按钮等,实现机器人逻辑的交互;
+4. 通过 Gradio 的 queue 函数和 launch 函数启动 Web 服务,并提供聊天机器人的功能。
+
+此外,程序还提供了代理和自动更新功能,可以确保用户的使用体验。
+
+## [7/22] 程序概述: show_math.py
+
+该程序是一个Python脚本,文件名为show_math.py。它转换Markdown和LaTeX混合语法到带MathML的HTML。程序使用latex2mathml模块来实现从LaTeX到MathML的转换,将符号转换为HTML实体以批量处理。程序利用正则表达式和递归函数的方法处理不同形式的LaTeX语法,支持以下四种情况:$$形式、$形式、\[..]形式和\(...\)形式。如果无法转换某个公式,则在该位置插入一条错误消息。最后,程序输出HTML字符串。
+
+## [8/22] 程序概述: theme.py
+
+该程序文件为一个Python脚本,其功能是调整Gradio应用的主题和样式,包括字体、颜色、阴影、背景等等。在程序中,使用了Gradio提供的默认颜色主题,并针对不同元素设置了相应的样式属性,以达到美化显示的效果。此外,程序中还包含了一段高级CSS样式代码,针对表格、列表、聊天气泡、行内代码等元素进行了样式设定。
+
+## [9/22] 程序概述: toolbox.py
+
+此程序文件主要包含了一系列用于聊天机器人开发的实用工具函数和装饰器函数。主要函数包括:
+
+1. ArgsGeneralWrapper:一个装饰器函数,用于重组输入参数,改变输入参数的顺序与结构。
+
+2. get_reduce_token_percent:一个函数,用于计算自然语言处理时会出现的token溢出比例。
+
+3. predict_no_ui_but_counting_down:一个函数,调用聊天接口,并且保留了一定的界面心跳功能,即当对话太长时,会自动采用二分法截断。
+
+4. write_results_to_file:一个函数,将对话记录history生成Markdown格式的文本,并写入文件中。
+
+5. regular_txt_to_markdown:一个函数,将普通文本转换为Markdown格式的文本。
+
+6. CatchException:一个装饰器函数,捕捉函数调度中的异常,并封装到一个生成器中返回,并显示到聊天当中。
+
+7. HotReload:一个装饰器函数,实现函数插件的热更新。
+
+8. report_execption:一个函数,向chatbot中添加错误信息。
+
+9. text_divide_paragraph:一个函数,将文本按照段落分隔符分割开,生成带有段落标签的HTML代码。
+
+10. markdown_convertion:一个函数,将Markdown格式的文本转换为HTML格式。如果包含数学公式,则先将公式转换为HTML格式。
+
+11. close_up_code_segment_during_stream:一个函数,用于在gpt输出代码的中途,即输出了前面的```,但还没输出完后面的```,补上后面的```。
+
+12. format_io:一个函数,将输入和输出解析为HTML格式。将输出部分的Markdown和数学公式转换为HTML格式。
+
+13. find_free_port:一个函数,返回当前系统中可用的未使用端口。
+
+14. extract_archive:一个函数,解压缩文件。
+
+15. find_recent_files:一个函数,查找目录下一分钟内创建的文件。
+
+16. on_file_uploaded:一个函数,响应用户上传的文件。
+
+## [10/22] 程序概述: crazy_functions\crazy_utils.py
+
+这是一个名为"crazy_utils.py"的Python程序文件,包含了两个函数:
+1. `breakdown_txt_to_satisfy_token_limit()`:接受文本字符串、计算文本单词数量的函数和单词数量限制作为输入参数,将长文本拆分成合适的长度,以满足单词数量限制。这个函数使用一个递归方法去拆分长文本。
+2. `breakdown_txt_to_satisfy_token_limit_for_pdf()`:类似于`breakdown_txt_to_satisfy_token_limit()`,但是它使用一个不同的递归方法来拆分长文本,以满足PDF文档中的需求。当出现无法继续拆分的情况时,该函数将使用一个中文句号标记插入文本来截断长文本。如果还是无法拆分,则会引发运行时异常。
+
+## [11/22] 程序概述: crazy_functions\__init__.py
+
+这个程序文件是一个 Python 的包,包名为 "crazy_functions",并且是其中的一个子模块 "__init__.py"。该包中可能包含多个函数或类,用于实现各种疯狂的功能。由于该文件的具体代码没有给出,因此无法进一步确定该包中的功能。通常情况下,一个包应该具有 __init__.py、__main__.py 和其它相关的模块文件,用于实现该包的各种功能。
+
+## [12/22] 程序概述: crazy_functions\下载arxiv论文翻译摘要.py
+
+这个程序实现的功能是下载arxiv论文并翻译摘要,文件名为`下载arxiv论文翻译摘要.py`。这个程序引入了`requests`、`unicodedata`、`os`、`re`等Python标准库,以及`pdfminer`、`bs4`等第三方库。其中`download_arxiv_`函数主要实现了从arxiv网站下载论文的功能,包括解析链接、获取论文信息、下载论文和生成文件名等,`get_name`函数则是为了从arxiv网站中获取论文信息创建的辅助函数。`下载arxiv论文并翻译摘要`函数则是实现了从下载好的PDF文件中提取摘要,然后使用预先训练的GPT模型翻译为中文的功能。同时,该函数还会将历史记录写入文件中。函数还会通过`CatchException`函数来捕获程序中出现的异常信息。
+
+## [13/22] 程序概述: crazy_functions\代码重写为全英文_多线程.py
+
+该程序文件为一个Python多线程程序,文件名为"crazy_functions\代码重写为全英文_多线程.py"。该程序使用了多线程技术,将一个大任务拆成多个小任务,同时执行,提高运行效率。
+
+程序的主要功能是将Python文件中的中文转换为英文,同时将转换后的代码输出。程序先清空历史记录,然后尝试导入openai和transformers等依赖库。程序接下来会读取当前路径下的.py文件和crazy_functions文件夹中的.py文件,并将其整合成一个文件清单。随后程序会使用GPT2模型进行中英文的翻译,并将结果保存在本地路径下的"gpt_log/generated_english_version"文件夹中。程序最终会生成一个任务执行报告。
+
+需要注意的是,该程序依赖于"request_llm"和"toolbox"库以及本地的"crazy_utils"模块。
+
+## [14/22] 程序概述: crazy_functions\总结word文档.py
+
+该程序文件是一个 Python 脚本文件,文件名为 ./crazy_functions/总结word文档.py。该脚本是一个函数插件,提供了名为“总结word文档”的函数。该函数的主要功能是批量读取给定文件夹下的 Word 文档文件,并使用 GPT 模型生成对每个文件的概述和意见建议。其中涉及到了读取 Word 文档、使用 GPT 模型等操作,依赖于许多第三方库。该文件也提供了导入依赖的方法,使用该脚本需要安装依赖库 python-docx 和 pywin32。函数功能实现的过程中,使用了一些用于调试的变量(如 fast_debug),可在需要时设置为 True。该脚本文件也提供了对程序功能和贡献者的注释。
+
+## [15/22] 程序概述: crazy_functions\批量总结PDF文档.py
+
+该程序文件名为 `./crazy_functions\批量总结PDF文档.py`,主要实现了批量处理PDF文档的功能。具体实现了以下几个函数:
+
+1. `is_paragraph_break(match)`:根据给定的匹配结果判断换行符是否表示段落分隔。
+2. `normalize_text(text)`:通过将文本特殊符号转换为其基本形式来对文本进行归一化处理。
+3. `clean_text(raw_text)`:对从 PDF 提取出的原始文本进行清洗和格式化处理。
+4. `解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)`:对给定的PDF文件进行分析并生成相应的概述。
+5. `批量总结PDF文档(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT)`:批量处理PDF文件,对其进行摘要生成。
+
+其中,主要用到了第三方库`pymupdf`对PDF文件进行处理。程序通过调用`fitz.open`函数打开PDF文件,使用`page.get_text()`方法获取PDF文本内容。然后,使用`clean_text`函数对文本进行清洗和格式化处理,生成最终的摘要。最后,调用`write_results_to_file`函数将历史记录写入文件并输出。
+
+## [16/22] 程序概述: crazy_functions\批量总结PDF文档pdfminer.py
+
+这个程序文件名是./crazy_functions\批量总结PDF文档pdfminer.py,是一个用于批量读取PDF文件,解析其中的内容,并对其进行概括的程序。程序中引用了pdfminer和beautifulsoup4等Python库,读取PDF文件并将其转化为文本内容,然后利用GPT模型生成摘要语言,最终输出一个中文和英文的摘要。程序还有一些错误处理的代码,会输出错误信息。
+
+## [17/22] 程序概述: crazy_functions\批量翻译PDF文档_多线程.py
+
+这是一个 Python 程序文件,文件名为 `批量翻译PDF文档_多线程.py`,包含多个函数。主要功能是批量处理 PDF 文档,解析其中的文本,进行清洗和格式化处理,并使用 OpenAI 的 GPT 模型进行翻译。其中使用了多线程技术来提高程序的效率和并行度。
+
+## [18/22] 程序概述: crazy_functions\生成函数注释.py
+
+该程序文件名为./crazy_functions\生成函数注释.py。该文件包含两个函数,分别为`生成函数注释`和`批量生成函数注释`。
+
+函数`生成函数注释`包含参数`file_manifest`、`project_folder`、`top_p`、`temperature`、`chatbot`、`history`和`systemPromptTxt`。其中,`file_manifest`为一个包含待处理文件路径的列表,`project_folder`表示项目文件夹路径,`top_p`和`temperature`是GPT模型参数,`chatbot`为与用户交互的聊天机器人,`history`记录聊天机器人与用户的历史记录,`systemPromptTxt`为聊天机器人发送信息前的提示语。`生成函数注释`通过读取文件内容,并调用GPT模型对文件中的所有函数生成注释,最后使用markdown表格输出结果。函数中还包含一些条件判断和计时器,以及调用其他自定义模块的函数。
+
+函数`批量生成函数注释`包含参数`txt`、`top_p`、`temperature`、`chatbot`、`history`、`systemPromptTxt`和`WEB_PORT`。其中,`txt`表示用户输入的项目文件夹路径,其他参数含义与`生成函数注释`中相同。`批量生成函数注释`主要是通过解析项目文件夹,获取所有待处理文件的路径,并调用函数`生成函数注释`对每个文件进行处理,最终生成注释表格输出给用户。
+
+## [19/22] 程序概述: crazy_functions\解析项目源代码.py
+
+该程序文件包含了多个函数,用于解析不同类型的项目,如Python项目、C项目、Java项目等。其中,最核心的函数是`解析源代码()`,它会对给定的一组文件进行分析,并返回对应的结果。具体流程如下:
+
+1. 遍历所有待分析的文件,对每个文件进行如下处理:
+
+ 1.1 从文件中读取代码内容,构造成一个字符串。
+
+ 1.2 构造一条GPT请求,向`predict_no_ui_but_counting_down()`函数发送请求,等待GPT回复。
+
+ 1.3 将GPT回复添加到机器人会话列表中,更新历史记录。
+
+ 1.4 如果不是快速调试模式,则等待2秒钟,继续分析下一个文件。
+
+2. 如果所有文件都分析完成,则向机器人会话列表中添加一条新消息,提示用户整个分析过程已经结束。
+
+3. 返回机器人会话列表和历史记录。
+
+除此之外,该程序文件还定义了若干个函数,用于针对不同类型的项目进行解析。这些函数会按照不同的方式调用`解析源代码()`函数。例如,对于Python项目,只需要分析.py文件;对于C项目,需要同时分析.h和.cpp文件等。每个函数中都会首先根据给定的项目路径读取相应的文件,然后调用`解析源代码()`函数进行分析。
+
+## [20/22] 程序概述: crazy_functions\读文章写摘要.py
+
+该程序文件为一个名为“读文章写摘要”的Python函数,用于解析项目文件夹中的.tex文件,并使用GPT模型生成文章的中英文摘要。函数使用了request_llm.bridge_chatgpt和toolbox模块中的函数,并包含两个子函数:解析Paper和CatchException。函数参数包括txt,top_p,temperature,chatbot,history,systemPromptTxt和WEB_PORT。执行过程中函数首先清空历史,然后根据项目文件夹中的.tex文件列表,对每个文件调用解析Paper函数生成中文摘要,最后根据所有文件的中文摘要,调用GPT模型生成英文摘要。函数运行过程中会将结果写入文件并返回聊天机器人和历史记录。
+
+## [21/22] 程序概述: crazy_functions\高级功能函数模板.py
+
+该程序文件为一个高级功能函数模板,文件名为"./crazy_functions\高级功能函数模板.py"。
+
+该文件导入了两个模块,分别是"request_llm.bridge_chatgpt"和"toolbox"。其中"request_llm.bridge_chatgpt"模块包含了一个函数"predict_no_ui_long_connection",该函数用于请求GPT模型进行对话生成。"toolbox"模块包含了三个函数,分别是"catchException"、"report_exception"和"write_results_to_file"函数,这三个函数主要用于异常处理和日志记录等。
+
+该文件定义了一个名为"高阶功能模板函数"的函数,并通过"decorator"装饰器将该函数装饰为一个异常处理函数,可以处理函数执行过程中出现的错误。该函数的作用是生成历史事件查询的问题,并向用户询问历史中哪些事件发生在指定日期,并索要相关图片。在查询完所有日期后,该函数返回所有历史事件及其相关图片的列表。其中,该函数的输入参数包括:
+
+1. txt: 一个字符串,表示当前消息的文本内容。
+2. top_p: 一个浮点数,表示GPT模型生成文本时的"top_p"参数。
+3. temperature: 一个浮点数,表示GPT模型生成文本时的"temperature"参数。
+4. chatbot: 一个列表,表示当前对话的记录列表。
+5. history: 一个列表,表示当前对话的历史记录列表。
+6. systemPromptTxt: 一个字符串,表示当前对话的系统提示信息。
+7. WEB_PORT: 一个整数,表示当前应用程序的WEB端口号。
+
+该函数在执行过程中,会先清空历史记录,以免输入溢出。然后,它会循环5次,生成5个历史事件查询的问题,并向用户请求输入相关信息。每次询问不携带之前的询问历史。在生成每个问题时,该函数会向"chatbot"列表中添加一条消息记录,并设置该记录的初始状态为"[Local Message] waiting gpt response."。然后,该函数会调用"predict_no_ui_long_connection"函数向GPT模型请求生成一段文本,并将生成的文本作为回答。如果请求过程中出现异常,该函数会忽略异常。最后,该函数将问题和回答添加到"chatbot"列表和"history"列表中,并将"chatbot"和"history"列表作为函数的返回值返回。
+
diff --git a/theme.py b/theme.py
index d7544ed..0c368c4 100644
--- a/theme.py
+++ b/theme.py
@@ -1,4 +1,4 @@
-import gradio as gr
+import gradio as gr
# gradio可用颜色列表
# gr.themes.utils.colors.slate (石板色)
@@ -24,14 +24,16 @@ import gradio as gr
# gr.themes.utils.colors.pink (粉红色)
# gr.themes.utils.colors.rose (玫瑰色)
+
def adjust_theme():
- try:
- color_er = gr.themes.utils.colors.pink
- set_theme = gr.themes.Default(
- primary_hue=gr.themes.utils.colors.orange,
- neutral_hue=gr.themes.utils.colors.gray,
- font=["sans-serif", "Microsoft YaHei", "ui-sans-serif", "system-ui", "sans-serif", gr.themes.utils.fonts.GoogleFont("Source Sans Pro")],
- font_mono=["ui-monospace", "Consolas", "monospace", gr.themes.utils.fonts.GoogleFont("IBM Plex Mono")])
+ try:
+ color_er = gr.themes.utils.colors.fuchsia
+ set_theme = gr.themes.Default(
+ primary_hue=gr.themes.utils.colors.orange,
+ neutral_hue=gr.themes.utils.colors.gray,
+ font=["sans-serif", "Microsoft YaHei", "ui-sans-serif", "system-ui",
+ "sans-serif", gr.themes.utils.fonts.GoogleFont("Source Sans Pro")],
+ font_mono=["ui-monospace", "Consolas", "monospace", gr.themes.utils.fonts.GoogleFont("IBM Plex Mono")])
set_theme.set(
# Colors
input_background_fill_dark="*neutral_800",
@@ -77,6 +79,78 @@ def adjust_theme():
button_cancel_text_color=color_er.c600,
button_cancel_text_color_dark="white",
)
- except:
- set_theme = None; print('gradio版本较旧, 不能自定义字体和颜色')
+ except:
+ set_theme = None
+ print('gradio版本较旧, 不能自定义字体和颜色')
return set_theme
+
+
+advanced_css = """
+/* 设置表格的外边距为1em,内部单元格之间边框合并,空单元格显示. */
+.markdown-body table {
+ margin: 1em 0;
+ border-collapse: collapse;
+ empty-cells: show;
+}
+
+/* 设置表格单元格的内边距为5px,边框粗细为1.2px,颜色为--border-color-primary. */
+.markdown-body th, .markdown-body td {
+ border: 1.2px solid var(--border-color-primary);
+ padding: 5px;
+}
+
+/* 设置表头背景颜色为rgba(175,184,193,0.2),透明度为0.2. */
+.markdown-body thead {
+ background-color: rgba(175,184,193,0.2);
+}
+
+/* 设置表头单元格的内边距为0.5em和0.2em. */
+.markdown-body thead th {
+ padding: .5em .2em;
+}
+
+/* 去掉列表前缀的默认间距,使其与文本线对齐. */
+.markdown-body ol, .markdown-body ul {
+ padding-inline-start: 2em !important;
+}
+
+/* 设定聊天气泡的样式,包括圆角、最大宽度和阴影等. */
+[class *= "message"] {
+ border-radius: var(--radius-xl) !important;
+ /* padding: var(--spacing-xl) !important; */
+ /* font-size: var(--text-md) !important; */
+ /* line-height: var(--line-md) !important; */
+ /* min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl)); */
+ /* min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl)); */
+}
+[data-testid = "bot"] {
+ max-width: 95%;
+ /* width: auto !important; */
+ border-bottom-left-radius: 0 !important;
+}
+[data-testid = "user"] {
+ max-width: 100%;
+ /* width: auto !important; */
+ border-bottom-right-radius: 0 !important;
+}
+
+/* 行内代码的背景设为淡灰色,设定圆角和间距. */
+.markdown-body code {
+ display: inline;
+ white-space: break-spaces;
+ border-radius: 6px;
+ margin: 0 2px 0 2px;
+ padding: .2em .4em .1em .4em;
+ background-color: rgba(175,184,193,0.2);
+}
+/* 设定代码块的样式,包括背景颜色、内、外边距、圆角。 */
+.markdown-body pre code {
+ display: block;
+ overflow: auto;
+ white-space: pre;
+ background-color: rgba(175,184,193,0.2);
+ border-radius: 10px;
+ padding: 1em;
+ margin: 1em 2em 1em 0.5em;
+}
+"""
diff --git a/toolbox.py b/toolbox.py
index d96b3f6..341d9e7 100644
--- a/toolbox.py
+++ b/toolbox.py
@@ -1,67 +1,134 @@
-import markdown, mdtex2html, threading, importlib, traceback
-from show_math import convert as convert_math
-from functools import wraps
+import markdown
+import mdtex2html
+import threading
+import importlib
+import traceback
+import importlib
+import inspect
+import re
+from latex2mathml.converter import convert as tex2mathml
+from functools import wraps, lru_cache
-def predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[], sys_prompt=''):
+
+def ArgsGeneralWrapper(f):
+ """
+ 装饰器函数,用于重组输入参数,改变输入参数的顺序与结构。
+ """
+ def decorated(txt, txt2, *args, **kwargs):
+ txt_passon = txt
+ if txt == "" and txt2 != "":
+ txt_passon = txt2
+ yield from f(txt_passon, *args, **kwargs)
+ return decorated
+
+
+def get_reduce_token_percent(text):
+ try:
+ # text = "maximum context length is 4097 tokens. However, your messages resulted in 4870 tokens"
+ pattern = r"(\d+)\s+tokens\b"
+ match = re.findall(pattern, text)
+ EXCEED_ALLO = 500 # 稍微留一点余地,否则在回复时会因余量太少出问题
+ max_limit = float(match[0]) - EXCEED_ALLO
+ current_tokens = float(match[1])
+ ratio = max_limit/current_tokens
+ assert ratio > 0 and ratio < 1
+ return ratio, str(int(current_tokens-max_limit))
+ except:
+ return 0.5, '不详'
+
+
+def predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[], sys_prompt='', long_connection=True):
"""
调用简单的predict_no_ui接口,但是依然保留了些许界面心跳功能,当对话太长时,会自动采用二分法截断
+ i_say: 当前输入
+ i_say_show_user: 显示到对话界面上的当前输入,例如,输入整个文件时,你绝对不想把文件的内容都糊到对话界面上
+ chatbot: 对话界面句柄
+ top_p, temperature: gpt参数
+ history: gpt参数 对话历史
+ sys_prompt: gpt参数 sys_prompt
+ long_connection: 是否采用更稳定的连接方式(推荐)
"""
import time
- from predict import predict_no_ui
+ from request_llm.bridge_chatgpt import predict_no_ui, predict_no_ui_long_connection
from toolbox import get_conf
TIMEOUT_SECONDS, MAX_RETRY = get_conf('TIMEOUT_SECONDS', 'MAX_RETRY')
# 多线程的时候,需要一个mutable结构在不同线程之间传递信息
# list就是最简单的mutable结构,我们第一个位置放gpt输出,第二个位置传递报错信息
mutable = [None, '']
# multi-threading worker
+
def mt(i_say, history):
while True:
try:
- mutable[0] = predict_no_ui(inputs=i_say, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt)
- break
- except ConnectionAbortedError as e:
- if len(history) > 0:
- history = [his[len(his)//2:] for his in history if his is not None]
- mutable[1] = 'Warning! History conversation is too long, cut into half. '
+ if long_connection:
+ mutable[0] = predict_no_ui_long_connection(
+ inputs=i_say, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt)
else:
- i_say = i_say[:len(i_say)//2]
- mutable[1] = 'Warning! Input file is too long, cut into half. '
+ mutable[0] = predict_no_ui(
+ inputs=i_say, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt)
+ break
+ except ConnectionAbortedError as token_exceeded_error:
+ # 尝试计算比例,尽可能多地保留文本
+ p_ratio, n_exceed = get_reduce_token_percent(
+ str(token_exceeded_error))
+ if len(history) > 0:
+ history = [his[int(len(his) * p_ratio):]
+ for his in history if his is not None]
+ else:
+ i_say = i_say[: int(len(i_say) * p_ratio)]
+ mutable[1] = f'警告,文本过长将进行截断,Token溢出数:{n_exceed},截断比例:{(1-p_ratio):.0%}。'
except TimeoutError as e:
- mutable[0] = '[Local Message] Failed with timeout.'
+ mutable[0] = '[Local Message] 请求超时。'
raise TimeoutError
+ except Exception as e:
+ mutable[0] = f'[Local Message] 异常:{str(e)}.'
+ raise RuntimeError(f'[Local Message] 异常:{str(e)}.')
# 创建新线程发出http请求
- thread_name = threading.Thread(target=mt, args=(i_say, history)); thread_name.start()
+ thread_name = threading.Thread(target=mt, args=(i_say, history))
+ thread_name.start()
# 原来的线程则负责持续更新UI,实现一个超时倒计时,并等待新线程的任务完成
cnt = 0
while thread_name.is_alive():
cnt += 1
- chatbot[-1] = (i_say_show_user, f"[Local Message] {mutable[1]}waiting gpt response {cnt}/{TIMEOUT_SECONDS*2*(MAX_RETRY+1)}"+''.join(['.']*(cnt%4)))
+ chatbot[-1] = (i_say_show_user,
+ f"[Local Message] {mutable[1]}waiting gpt response {cnt}/{TIMEOUT_SECONDS*2*(MAX_RETRY+1)}"+''.join(['.']*(cnt % 4)))
yield chatbot, history, '正常'
time.sleep(1)
# 把gpt的输出从mutable中取出来
gpt_say = mutable[0]
- if gpt_say=='[Local Message] Failed with timeout.': raise TimeoutError
+ if gpt_say == '[Local Message] Failed with timeout.':
+ raise TimeoutError
return gpt_say
+
def write_results_to_file(history, file_name=None):
"""
将对话记录history以Markdown格式写入文件中。如果没有指定文件名,则使用当前时间生成文件名。
"""
- import os, time
+ import os
+ import time
if file_name is None:
# file_name = time.strftime("chatGPT分析报告%Y-%m-%d-%H-%M-%S", time.localtime()) + '.md'
- file_name = 'chatGPT分析报告' + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + '.md'
+ file_name = 'chatGPT分析报告' + \
+ time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + '.md'
os.makedirs('./gpt_log/', exist_ok=True)
- with open(f'./gpt_log/{file_name}', 'w', encoding = 'utf8') as f:
+ with open(f'./gpt_log/{file_name}', 'w', encoding='utf8') as f:
f.write('# chatGPT 分析报告\n')
for i, content in enumerate(history):
- if i%2==0: f.write('## ')
+ try: # 这个bug没找到触发条件,暂时先这样顶一下
+ if type(content) != str:
+ content = str(content)
+ except:
+ continue
+ if i % 2 == 0:
+ f.write('## ')
f.write(content)
f.write('\n\n')
res = '以上材料已经被写入' + os.path.abspath(f'./gpt_log/{file_name}')
print(res)
return res
+
def regular_txt_to_markdown(text):
"""
将普通文本转换为Markdown格式的文本。
@@ -71,6 +138,7 @@ def regular_txt_to_markdown(text):
text = text.replace('\n\n\n', '\n\n')
return text
+
def CatchException(f):
"""
装饰器函数,捕捉函数f中的异常并封装到一个生成器中返回,并显示到聊天当中。
@@ -83,17 +151,35 @@ def CatchException(f):
from check_proxy import check_proxy
from toolbox import get_conf
proxies, = get_conf('proxies')
- tb_str = regular_txt_to_markdown(traceback.format_exc())
- chatbot[-1] = (chatbot[-1][0], f"[Local Message] 实验性函数调用出错: \n\n {tb_str} \n\n 当前代理可用性: \n\n {check_proxy(proxies)}")
+ tb_str = '```\n' + traceback.format_exc() + '```'
+ if chatbot is None or len(chatbot) == 0:
+ chatbot = [["插件调度异常", "异常原因"]]
+ chatbot[-1] = (chatbot[-1][0],
+ f"[Local Message] 实验性函数调用出错: \n\n{tb_str} \n\n当前代理可用性: \n\n{check_proxy(proxies)}")
yield chatbot, history, f'异常 {e}'
return decorated
+
+def HotReload(f):
+ """
+ 装饰器函数,实现函数插件热更新
+ """
+ @wraps(f)
+ def decorated(*args, **kwargs):
+ fn_name = f.__name__
+ f_hot_reload = getattr(importlib.reload(inspect.getmodule(f)), fn_name)
+ yield from f_hot_reload(*args, **kwargs)
+ return decorated
+
+
def report_execption(chatbot, history, a, b):
"""
向chatbot中添加错误信息
"""
chatbot.append((a, b))
- history.append(a); history.append(b)
+ history.append(a)
+ history.append(b)
+
def text_divide_paragraph(text):
"""
@@ -110,26 +196,105 @@ def text_divide_paragraph(text):
text = "".join(lines)
return text
+
def markdown_convertion(txt):
"""
将Markdown格式的文本转换为HTML格式。如果包含数学公式,则先将公式转换为HTML格式。
"""
- if ('$' in txt) and ('```' not in txt):
- return markdown.markdown(txt,extensions=['fenced_code','tables']) + '
' + \
- markdown.markdown(convert_math(txt, splitParagraphs=False),extensions=['fenced_code','tables'])
+ pre = ''
+ suf = '
'
+ markdown_extension_configs = {
+ 'mdx_math': {
+ 'enable_dollar_delimiter': True,
+ 'use_gitlab_delimiters': False,
+ },
+ }
+ find_equation_pattern = r'\n', '')
+ return content
+
+
+ if ('$' in txt) and ('```' not in txt): # 有$标识的公式符号,且没有代码段```的标识
+ # convert everything to html format
+ split = markdown.markdown(text='---')
+ convert_stage_1 = markdown.markdown(text=txt, extensions=['mdx_math', 'fenced_code', 'tables', 'sane_lists'], extension_configs=markdown_extension_configs)
+ convert_stage_1 = markdown_bug_hunt(convert_stage_1)
+ # re.DOTALL: Make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline. Corresponds to the inline flag (?s).
+ # 1. convert to easy-to-copy tex (do not render math)
+ convert_stage_2_1, n = re.subn(find_equation_pattern, replace_math_no_render, convert_stage_1, flags=re.DOTALL)
+ # 2. convert to rendered equation
+ convert_stage_2_2, n = re.subn(find_equation_pattern, replace_math_render, convert_stage_1, flags=re.DOTALL)
+ # cat them together
+ return pre + convert_stage_2_1 + f'{split}' + convert_stage_2_2 + suf
else:
- return markdown.markdown(txt,extensions=['fenced_code','tables'])
+ return pre + markdown.markdown(txt, extensions=['fenced_code', 'tables', 'sane_lists']) + suf
+
+
+def close_up_code_segment_during_stream(gpt_reply):
+ """
+ 在gpt输出代码的中途(输出了前面的```,但还没输出完后面的```),补上后面的```
+ """
+ if '```' not in gpt_reply:
+ return gpt_reply
+ if gpt_reply.endswith('```'):
+ return gpt_reply
+
+ # 排除了以上两个情况,我们
+ segments = gpt_reply.split('```')
+ n_mark = len(segments) - 1
+ if n_mark % 2 == 1:
+ # print('输出代码片段中!')
+ return gpt_reply+'\n```'
+ else:
+ return gpt_reply
def format_io(self, y):
"""
将输入和输出解析为HTML格式。将y中最后一项的输入部分段落化,并将输出部分的Markdown和数学公式转换为HTML格式。
"""
- if y is None or y == []: return []
+ if y is None or y == []:
+ return []
i_ask, gpt_reply = y[-1]
- i_ask = text_divide_paragraph(i_ask) # 输入部分太自由,预处理一波
+ i_ask = text_divide_paragraph(i_ask) # 输入部分太自由,预处理一波
+ gpt_reply = close_up_code_segment_during_stream(
+ gpt_reply) # 当代码输出半截的时候,试着补上后个```
y[-1] = (
- None if i_ask is None else markdown.markdown(i_ask, extensions=['fenced_code','tables']),
+ None if i_ask is None else markdown.markdown(
+ i_ask, extensions=['fenced_code', 'tables']),
None if gpt_reply is None else markdown_convertion(gpt_reply)
)
return y
@@ -164,8 +329,33 @@ def extract_archive(file_path, dest_dir):
with tarfile.open(file_path, 'r:*') as tarobj:
tarobj.extractall(path=dest_dir)
print("Successfully extracted tar archive to {}".format(dest_dir))
+
+ # 第三方库,需要预先pip install rarfile
+ # 此外,Windows上还需要安装winrar软件,配置其Path环境变量,如"C:\Program Files\WinRAR"才可以
+ elif file_extension == '.rar':
+ try:
+ import rarfile
+ with rarfile.RarFile(file_path) as rf:
+ rf.extractall(path=dest_dir)
+ print("Successfully extracted rar archive to {}".format(dest_dir))
+ except:
+ print("Rar format requires additional dependencies to install")
+ return '\n\n需要安装pip install rarfile来解压rar文件'
+
+ # 第三方库,需要预先pip install py7zr
+ elif file_extension == '.7z':
+ try:
+ import py7zr
+ with py7zr.SevenZipFile(file_path, mode='r') as f:
+ f.extractall(path=dest_dir)
+ print("Successfully extracted 7z archive to {}".format(dest_dir))
+ except:
+ print("7z format requires additional dependencies to install")
+ return '\n\n需要安装pip install py7zr来解压7z文件'
else:
- return
+ return ''
+ return ''
+
def find_recent_files(directory):
"""
@@ -180,59 +370,101 @@ def find_recent_files(directory):
for filename in os.listdir(directory):
file_path = os.path.join(directory, filename)
- if file_path.endswith('.log'): continue
- created_time = os.path.getctime(file_path)
+ if file_path.endswith('.log'):
+ continue
+ created_time = os.path.getmtime(file_path)
if created_time >= one_minute_ago:
- if os.path.isdir(file_path): continue
+ if os.path.isdir(file_path):
+ continue
recent_files.append(file_path)
return recent_files
def on_file_uploaded(files, chatbot, txt):
- if len(files) == 0: return chatbot, txt
- import shutil, os, time, glob
+ if len(files) == 0:
+ return chatbot, txt
+ import shutil
+ import os
+ import time
+ import glob
from toolbox import extract_archive
- try: shutil.rmtree('./private_upload/')
- except: pass
+ try:
+ shutil.rmtree('./private_upload/')
+ except:
+ pass
time_tag = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
os.makedirs(f'private_upload/{time_tag}', exist_ok=True)
+ err_msg = ''
for file in files:
file_origin_name = os.path.basename(file.orig_name)
shutil.copy(file.name, f'private_upload/{time_tag}/{file_origin_name}')
- extract_archive(f'private_upload/{time_tag}/{file_origin_name}',
- dest_dir=f'private_upload/{time_tag}/{file_origin_name}.extract')
- moved_files = [fp for fp in glob.glob('private_upload/**/*', recursive=True)]
+ err_msg += extract_archive(f'private_upload/{time_tag}/{file_origin_name}',
+ dest_dir=f'private_upload/{time_tag}/{file_origin_name}.extract')
+ moved_files = [fp for fp in glob.glob(
+ 'private_upload/**/*', recursive=True)]
txt = f'private_upload/{time_tag}'
moved_files_str = '\t\n\n'.join(moved_files)
- chatbot.append(['我上传了文件,请查收',
- f'[Local Message] 收到以下文件: \n\n{moved_files_str}\n\n调用路径参数已自动修正到: \n\n{txt}\n\n现在您点击任意实验功能时,以上文件将被作为输入参数'])
+ chatbot.append(['我上传了文件,请查收',
+ f'[Local Message] 收到以下文件: \n\n{moved_files_str}' +
+ f'\n\n调用路径参数已自动修正到: \n\n{txt}' +
+ f'\n\n现在您点击任意实验功能时,以上文件将被作为输入参数'+err_msg])
return chatbot, txt
def on_report_generated(files, chatbot):
from toolbox import find_recent_files
report_files = find_recent_files('gpt_log')
- if len(report_files) == 0: return report_files, chatbot
+ if len(report_files) == 0:
+ return None, chatbot
# files.extend(report_files)
- chatbot.append(['汇总报告如何远程获取?', '汇总报告已经添加到右侧文件上传区,请查收。'])
+ chatbot.append(['汇总报告如何远程获取?', '汇总报告已经添加到右侧“文件上传区”(可能处于折叠状态),请查收。'])
return report_files, chatbot
+
+@lru_cache(maxsize=128)
+def read_single_conf_with_lru_cache(arg):
+ try:
+ r = getattr(importlib.import_module('config_private'), arg)
+ except:
+ r = getattr(importlib.import_module('config'), arg)
+ # 在读取API_KEY时,检查一下是不是忘了改config
+ if arg == 'API_KEY':
+ # 正确的 API_KEY 是 "sk-" + 48 位大小写字母数字的组合
+ API_MATCH = re.match(r"sk-[a-zA-Z0-9]{48}$", r)
+ if API_MATCH:
+ print(f"[API_KEY] 您的 API_KEY 是: {r[:15]}*** API_KEY 导入成功")
+ else:
+ assert False, "正确的 API_KEY 是 'sk-' + '48 位大小写字母数字' 的组合,请在config文件中修改API密钥, 添加海外代理之后再运行。" + \
+ "(如果您刚更新过代码,请确保旧版config_private文件中没有遗留任何新增键值)"
+ if arg == 'proxies':
+ if r is None:
+ print('[PROXY] 网络代理状态:未配置。无代理状态下很可能无法访问。建议:检查USE_PROXY选项是否修改。')
+ else:
+ print('[PROXY] 网络代理状态:已配置。配置信息如下:', r)
+ assert isinstance(r, dict), 'proxies格式错误,请注意proxies选项的格式,不要遗漏括号。'
+ return r
+
+
def get_conf(*args):
# 建议您复制一个config_private.py放自己的秘密, 如API和代理网址, 避免不小心传github被别人看到
res = []
for arg in args:
- try: r = getattr(importlib.import_module('config_private'), arg)
- except: r = getattr(importlib.import_module('config'), arg)
+ r = read_single_conf_with_lru_cache(arg)
res.append(r)
- # 在读取API_KEY时,检查一下是不是忘了改config
- if arg=='API_KEY' and len(r) != 51:
- assert False, "正确的API_KEY密钥是51位,请在config文件中修改API密钥, 添加海外代理之后再运行。" + \
- "(如果您刚更新过代码,请确保旧版config_private文件中没有遗留任何新增键值)"
return res
+
def clear_line_break(txt):
txt = txt.replace('\n', ' ')
txt = txt.replace(' ', ' ')
txt = txt.replace(' ', ' ')
- return txt
\ No newline at end of file
+ return txt
+
+
+class DummyWith():
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_value, traceback):
+ return
diff --git a/version b/version
new file mode 100644
index 0000000..8ad8971
--- /dev/null
+++ b/version
@@ -0,0 +1,5 @@
+{
+ "version": 2.4,
+ "show_feature": true,
+ "new_feature": "(1)新增PDF全文翻译功能; (2)新增输入区切换位置的功能; (3)新增垂直布局选项; (4)多线程函数插件优化。"
+}
 +
+
 +
+
 @@ -84,45 +81,43 @@ chat分析报告生成 | [实验性功能] 运行后自动生成总结汇报
## 直接运行 (Windows, Linux or MacOS)
-下载项目
-
+### 1. 下载项目
```sh
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-我们建议将`config.py`复制为`config_private.py`并将后者用作个性化配置文件以避免`config.py`中的变更影响你的使用或不小心将包含你的OpenAI API KEY的`config.py`提交至本项目。
+### 2. 配置API_KEY和代理设置
-```sh
-cp config.py config_private.py
+在`config.py`中,配置 海外Proxy 和 OpenAI API KEY,说明如下
```
-
-在`config_private.py`中,配置 海外Proxy 和 OpenAI API KEY
-```
-1. 如果你在国内,需要设置海外代理才能够使用 OpenAI API,你可以通过 config.py 文件来进行设置。
+1. 如果你在国内,需要设置海外代理才能够顺利使用 OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
2. 配置 OpenAI API KEY。你需要在 OpenAI 官网上注册并获取 API KEY。一旦你拿到了 API KEY,在 config.py 文件里配置好即可。
+3. 与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
```
-安装依赖
+(P.S. 程序运行时会优先检查是否存在名为`config_private.py`的私密配置文件,并用其中的配置覆盖`config.py`的同名配置。因此,如果您能理解我们的配置读取逻辑,我们强烈建议您在`config.py`旁边创建一个名为`config_private.py`的新配置文件,并把`config.py`中的配置转移(复制)到`config_private.py`中。`config_private.py`不受git管控,可以让您的隐私信息更加安全。)
+
+### 3. 安装依赖
```sh
-python -m pip install -r requirements.txt
+# (选择一)推荐
+python -m pip install -r requirements.txt
+
+# (选择二)如果您使用anaconda,步骤也是类似的:
+# (选择二.1)conda create -n gptac_venv python=3.11
+# (选择二.2)conda activate gptac_venv
+# (选择二.3)python -m pip install -r requirements.txt
+
+# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:
+# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
```
-或者,如果你希望使用`conda`
-
-```sh
-conda create -n gptac 'gradio>=3.23' requests
-conda activate gptac
-python3 -m pip install mdtex2html
-```
-
-运行
-
+### 4. 运行
```sh
python main.py
```
-测试实验性功能
+### 5. 测试实验性功能
```
- 测试C++项目头文件分析
input区域 输入 `./crazy_functions/test_project/cpp/libJPG` , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
@@ -136,8 +131,6 @@ python main.py
点击 "[实验] 实验功能函数模板"
```
-与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
-
## 使用docker (Linux)
``` sh
@@ -145,7 +138,7 @@ python main.py
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
# 配置 海外Proxy 和 OpenAI API KEY
-config.py
+用任意文本编辑器编辑 config.py
# 安装
docker build -t gpt-academic .
# 运行
@@ -166,20 +159,12 @@ input区域 输入 ./crazy_functions/test_project/python/dqn , 然后点击 "[
```
-## 使用WSL2(Windows Subsystem for Linux 子系统)
-选择这种方式默认您已经具备一定基本知识,因此不再赘述多余步骤。如果不是这样,您可以从[这里](https://learn.microsoft.com/zh-cn/windows/wsl/about)或GPT处获取更多关于子系统的信息。
+## 其他部署方式
+- 使用WSL2(Windows Subsystem for Linux 子系统)
+请访问[部署wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
-WSL2可以配置使用Windows侧的代理上网,前置步骤可以参考[这里](https://www.cnblogs.com/tuilk/p/16287472.html)
-由于Windows相对WSL2的IP会发生变化,我们需要每次启动前先获取这个IP来保证顺利访问,将config.py中设置proxies的部分更改为如下代码:
-```python
-import subprocess
-cmd_get_ip = 'grep -oP "(\d+\.)+(\d+)" /etc/resolv.conf'
-ip_proxy = subprocess.run(
- cmd_get_ip, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True
- ).stdout.strip() # 获取windows的IP
-proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请自行修改
-```
-在启动main.py后,可以在windows浏览器中访问服务。至此测试、使用与上面其他方法无异。
+- nginx远程部署
+请访问[部署wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E7%9A%84%E6%8C%87%E5%AF%BC)
## 自定义新的便捷按钮(学术快捷键自定义)
@@ -204,7 +189,7 @@ proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请
如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests!
## 配置代理
-
+### 方法一:常规方法
在```config.py```中修改端口与代理软件对应
@@ -84,45 +81,43 @@ chat分析报告生成 | [实验性功能] 运行后自动生成总结汇报
## 直接运行 (Windows, Linux or MacOS)
-下载项目
-
+### 1. 下载项目
```sh
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-我们建议将`config.py`复制为`config_private.py`并将后者用作个性化配置文件以避免`config.py`中的变更影响你的使用或不小心将包含你的OpenAI API KEY的`config.py`提交至本项目。
+### 2. 配置API_KEY和代理设置
-```sh
-cp config.py config_private.py
+在`config.py`中,配置 海外Proxy 和 OpenAI API KEY,说明如下
```
-
-在`config_private.py`中,配置 海外Proxy 和 OpenAI API KEY
-```
-1. 如果你在国内,需要设置海外代理才能够使用 OpenAI API,你可以通过 config.py 文件来进行设置。
+1. 如果你在国内,需要设置海外代理才能够顺利使用 OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
2. 配置 OpenAI API KEY。你需要在 OpenAI 官网上注册并获取 API KEY。一旦你拿到了 API KEY,在 config.py 文件里配置好即可。
+3. 与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
```
-安装依赖
+(P.S. 程序运行时会优先检查是否存在名为`config_private.py`的私密配置文件,并用其中的配置覆盖`config.py`的同名配置。因此,如果您能理解我们的配置读取逻辑,我们强烈建议您在`config.py`旁边创建一个名为`config_private.py`的新配置文件,并把`config.py`中的配置转移(复制)到`config_private.py`中。`config_private.py`不受git管控,可以让您的隐私信息更加安全。)
+
+### 3. 安装依赖
```sh
-python -m pip install -r requirements.txt
+# (选择一)推荐
+python -m pip install -r requirements.txt
+
+# (选择二)如果您使用anaconda,步骤也是类似的:
+# (选择二.1)conda create -n gptac_venv python=3.11
+# (选择二.2)conda activate gptac_venv
+# (选择二.3)python -m pip install -r requirements.txt
+
+# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:
+# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
```
-或者,如果你希望使用`conda`
-
-```sh
-conda create -n gptac 'gradio>=3.23' requests
-conda activate gptac
-python3 -m pip install mdtex2html
-```
-
-运行
-
+### 4. 运行
```sh
python main.py
```
-测试实验性功能
+### 5. 测试实验性功能
```
- 测试C++项目头文件分析
input区域 输入 `./crazy_functions/test_project/cpp/libJPG` , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
@@ -136,8 +131,6 @@ python main.py
点击 "[实验] 实验功能函数模板"
```
-与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
-
## 使用docker (Linux)
``` sh
@@ -145,7 +138,7 @@ python main.py
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
# 配置 海外Proxy 和 OpenAI API KEY
-config.py
+用任意文本编辑器编辑 config.py
# 安装
docker build -t gpt-academic .
# 运行
@@ -166,20 +159,12 @@ input区域 输入 ./crazy_functions/test_project/python/dqn , 然后点击 "[
```
-## 使用WSL2(Windows Subsystem for Linux 子系统)
-选择这种方式默认您已经具备一定基本知识,因此不再赘述多余步骤。如果不是这样,您可以从[这里](https://learn.microsoft.com/zh-cn/windows/wsl/about)或GPT处获取更多关于子系统的信息。
+## 其他部署方式
+- 使用WSL2(Windows Subsystem for Linux 子系统)
+请访问[部署wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
-WSL2可以配置使用Windows侧的代理上网,前置步骤可以参考[这里](https://www.cnblogs.com/tuilk/p/16287472.html)
-由于Windows相对WSL2的IP会发生变化,我们需要每次启动前先获取这个IP来保证顺利访问,将config.py中设置proxies的部分更改为如下代码:
-```python
-import subprocess
-cmd_get_ip = 'grep -oP "(\d+\.)+(\d+)" /etc/resolv.conf'
-ip_proxy = subprocess.run(
- cmd_get_ip, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True
- ).stdout.strip() # 获取windows的IP
-proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请自行修改
-```
-在启动main.py后,可以在windows浏览器中访问服务。至此测试、使用与上面其他方法无异。
+- nginx远程部署
+请访问[部署wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E7%9A%84%E6%8C%87%E5%AF%BC)
## 自定义新的便捷按钮(学术快捷键自定义)
@@ -204,7 +189,7 @@ proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请
如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests!
## 配置代理
-
+### 方法一:常规方法
在```config.py```中修改端口与代理软件对应
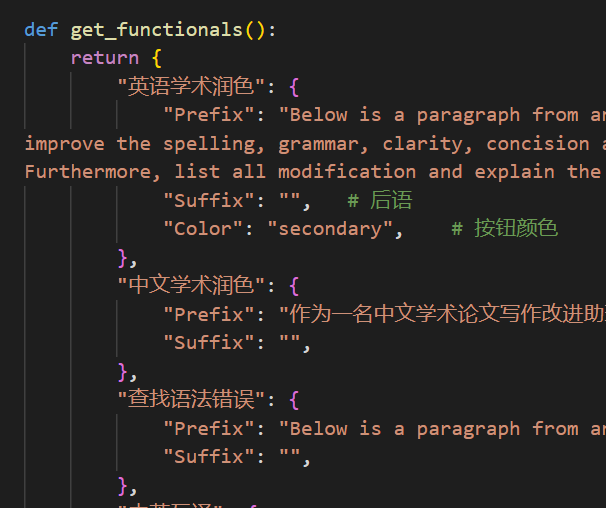 +
+
